The latest release includes Apache FlinkⓇ 1.10 and significantly enhances the platform’s capabilities around multi-tenancy and disaster recovery
We are very excited to announce the release of Ververica Platform 2.1, the enterprise stream processing platform by the original creators of Apache Flink.
Ververica Platform enables every enterprise to continuously derive immediate insight from its data and better serve both internal and external stakeholders in real-time. It is powered by the leading stream processing framework, Apache Flink, and provides an integrated, enterprise-ready solution for secure, scalable, and cost-effective stateful stream processing and streaming analytics. Our latest release unlocks many new capabilities and enhances the way platform operators can address multi-tenancy and disaster recovery. The latest release ships with Apache Flink 1.10 which includes many improvements and new features, such as unified memory configuration for TaskManagers, improved application lifecycle management with the recently-introduced stop command, and enhanced Hive integration. Learn more about the major new features of Ververica Platform in the following paragraphs or refer to the release notes for a complete list of changes and updates.
Apache Flink 1.10
At the core of Ververica Platform sits Apache Flink. The latest release includes Apache Flink 1.10 and Apache Flink 1.9. As always, the latest Apache Flink release comes with numerous new features and improvements. Here are some of the highlights of the new release that are most relevant to users of Ververica Platform.
Unified Memory Configuration for TaskManagers (FLIP-49)
Flink 1.10 introduces an overall revamp and simplification of the memory configuration of Apache Flink TaskManagers, Apache Flink’s worker processes.
Simply put, TaskManagers can now make better use of their overall memory without loss of stability by assigning memory budgets on a more fine-grained basis. In particular, the platform no longer needs to be as conservative when accounting for the JVM overhead and other non-JVM memory consumption of TaskManager containers when requesting resources from Kubernetes, which directly leads to a higher memory utilization.
While you previously had to consider the memory consumption of Flink’s RocksDBStatebackend separately when sizing TaskManager containers, in Flink 1.10 you now only need to configure the ratio between JVM and RocksDB memory consumption, and Flink will ensure that both stay within their respective memory limits. This, again, results in higher memory utilization and increased robustness by avoiding containers being killed by Kubernetes due to memory usage.
Full Hive Support in Apache Flink
Flink 1.10 further extends its integration with Apache Hive (announced as a preview in Flink 1.9). On top of existing functionality (i.e. persisting Flink-specific metadata in Hive’s Metastore, calling UDFs defined in Hive, and using Flink for reading and writing Hive tables), Flink 1.10 has now expanded its SQL syntax to support `INSERT OVERWRITE` and `PARTITION` (FLIP-63), enabling you to write into both static and dynamic partitions in Hive.
Stop with Side-Effects (FLIP-34)
Whenever you use Ververica Platform to perform a stateful upgrade to an application, the corresponding Deployment is suspended. This means the Deployment is shut down gracefully and its state consistently archived so it can be resumed from later.
Ververica Platform 2.1 now uses Flink’s recently-introduced stop command when suspending a Deployment. The stop command performs a savepoint, atomically shuts down the Apache Flink application, and guarantees persistence to external storage systems for exactly-once sinks by committing all outstanding transactions. The resulting savepoint is thus fully self-contained.
Dedicated Classloaders for User Code & Filesystems
Ververica Platform 2.1 takes advantage of two recent Flink features to avoid classloading conflicts between Apache Flink, its file system implementations, and user code: firstly, we utilize a dedicated classloader for the user code that eliminates class loading issues during deployment (FLINK-13993). Additionally, we make use of Flink’s plugin system for Flink filesystems (FLINK-11952) which makes bundling more filesystems within our distribution of Apache Flink efficient without risking additional classloading issues.
Platform State Storage in External Database
Ververica Platform maintains all resources, such as Deployments, savepoint metadata, and additional global settings in a dedicated persistence layer. We call this data “platform state”, as opposed to the “application state” of your Apache Flink application. Until now, Ververica Platform has always stored platform state locally in a mounted volume.
Losing this platform state during an infrastructure failure is a significant risk for Ververica Platform operations teams and may result in extended downtime and limited ability to monitor and control your running Apache Flink applications. While you could manually recover some of the state based on the content of the distributed file system and version-controlled resource definitions, it is something that has so far created additional overhead to operations teams.
With Ververica Platform 2.1 you can choose to use an external database to store platform state. Its durability and consistency is no longer bound to the guarantees of your Kubernetes Persistent Volume (PV), but rather it relies on an existing external database. While this adds an additional component to your stream processing infrastructure, the widespread availability of (replicated) relational databases in today’s enterprise enables flexible recovery strategies in the presence of infrastructure faults. Similarly, there exist standard processes for backups and migrations of relational databases while analogous procedures have, in many cases, not yet been established for Kubernetes PVs. Finally, storing the state in a relational database management system enables Ververica Platform operators to have full transparency over the platform state at any given point in time.
Deployment Defaults & Logging Profiles
Ververica Platform 2.1 extends its multi-tenancy support by adding three additional features that enable you to establish Apache Flink best practices and standards across your entire organization. These features are:
Configurable Global Deployment Defaults
With global Deployment Defaults, Ververica Platform operations teams are capable of applying a unified set of standards and best practices across teams in the organization. As an example, you may now specify metrics or logging systems — such as Prometheus or InfluxDB — across all Deployments and Namespaces in a single place.
Namespace-wide Deployment Defaults
In addition to global Deployment Defaults, every team is now able to set up their own Namespace-wide Deployment Defaults, applied on top of the global Deployment Defaults to all Deployments in its Namespace. For instance, your teams may pre-configure a certain state backend, restart strategy, or resource limits for all their applications.
Logging Profiles
Ververica Platform operators can configure global Logging Profiles across all Deployments. For each application, developers may then choose between the pre-configured logging profiles or even customize any of them to the specific needs of an individual application. For example, the platform team could provide one logging profile that simply logs to standard out and a second profile that additionally sends logs to Apache Kafka.
Improved Observability for Apache Flink Deployments
Managing the lifecycle of stateful stream processing applications has always been a key feature of Ververica Platform. During its lifecycle, Deployments move through different stages like “CANCELLED”, “SUSPENDED” or “RUNNING”. In Ververica Platform 2.1, we have enabled additional status information for “RUNNING” Deployments , which take into consideration both the restart rate and the actual status of the underlying Flink job, allowing users to instantly identify unstable or failing Deployments via Ververica Platform’s REST API or web interface.
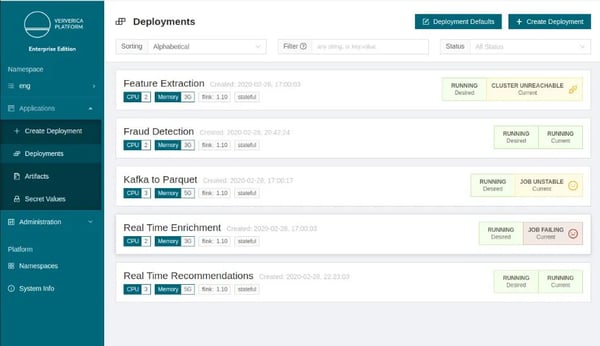
Figure 1:Ververica Platform Deployments in different status
Streamlined Deployment Creation in Web User Interface
With Ververica Platform 2.1, creating and configuring Deployments through the platform’s web interface has become easier. Specifically, each user has the option to choose between three different views (“Standard”, “Advanced”, “YAML”) based on their individual proficiency and the required level of detail. This is particularly valuable as platform operators and team leads are now able to manage more advanced configurations via Deployment Defaults (described above).
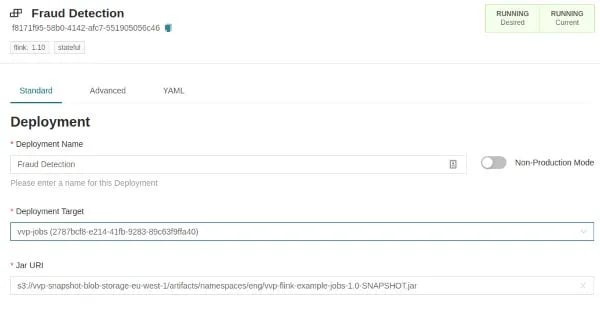 Figure 2: The "Standard" view only requires minimal input by the user and relies on system or user defaults for everything else.
Figure 2: The "Standard" view only requires minimal input by the user and relies on system or user defaults for everything else.
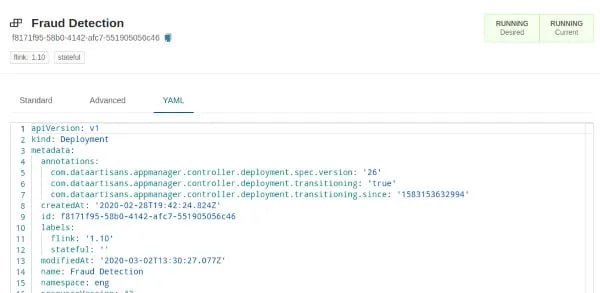
Figure 3: The "YAML" view allows expert users to directly edit (or paste) the raw YAML representation of a Deployment.
Out-of-the-box OpenSSL Support
Ververica Platform 2.1 comes with out-of-the-box support for using OpenSSL for all data transfer and communication between the components of Flink clusters as well as between Ververica Platform and Flink JobManagers. In past releases, both Apache Flink and Ververica Platform provided support for Java’s default SSL engine, which comes with a significant performance penalty when compared with the OpenSSL engine. OpenSSL is now automatically used when you enable SSL for a Ververica Platform Deployment. Stay tuned for more information and performance benchmarks (sneak preview in Figure 4 below) around this feature in the coming weeks!
With the new additions to Ververica Platform we further enhance our technology stack to provide an even more resilient, scalable, and sophisticated stream processing infrastructure for your organization. For a complete list of changes please, check out the Ververica Platform documentation.
We are always looking for your feedback on the latest release. Reach out to platform@ververica.com to let us know of any suggestions or questions you might have.









