














Own Your Now
35 000 +
Jobs running on a single cluster
>10 Petabytes
Data ingested per day
>2 Million
Cores operated in an elastically scaling cluster
6.9 Billion
Records processed per second
10 Trillion
Records ingested per day
Brought to you by the original creators of Apache Flink®

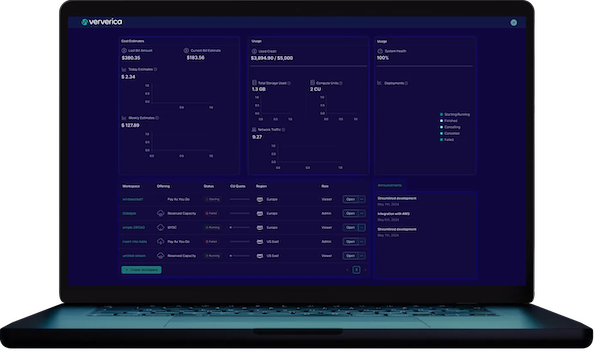
Ververica Platform:
Self-Managed
Ververica Cloud:
Managed Service
Ververica Cloud:
Bring Your Own Cloud
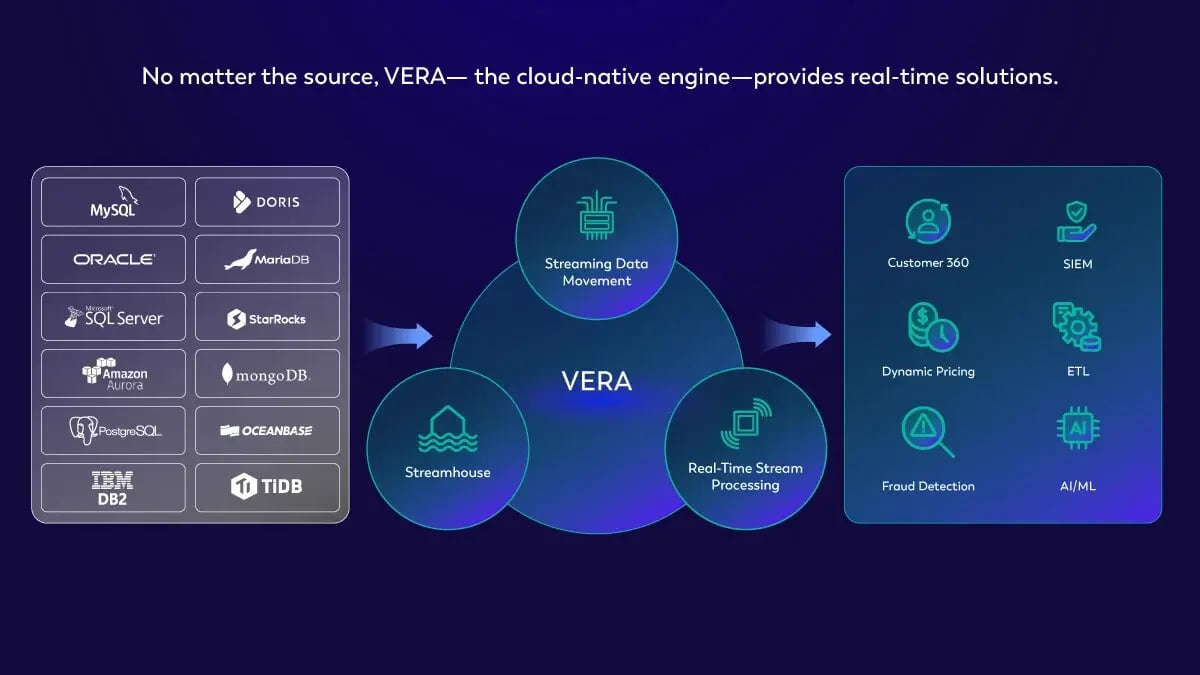
Source Data & Events
Customer
Customer
Customer
Source Integration
Unified Streaming Data Platform
VERA Engine
Public Cloud
Customer
Private Cloud
Customer
Sink Integration
Destination Data
and Events Sink Integration
Customer
Customer
Customer



Latest News

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now
Introducing Ververica’s Model Context Protocol (MCP) Server (Preview): Native Large Language Models... April 2, 2026 by Vladimir Jandreski
Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
“Zero Trust” used to mean something. It described a foundational security model where nothing... February 26, 2026 by Ben Gamble