














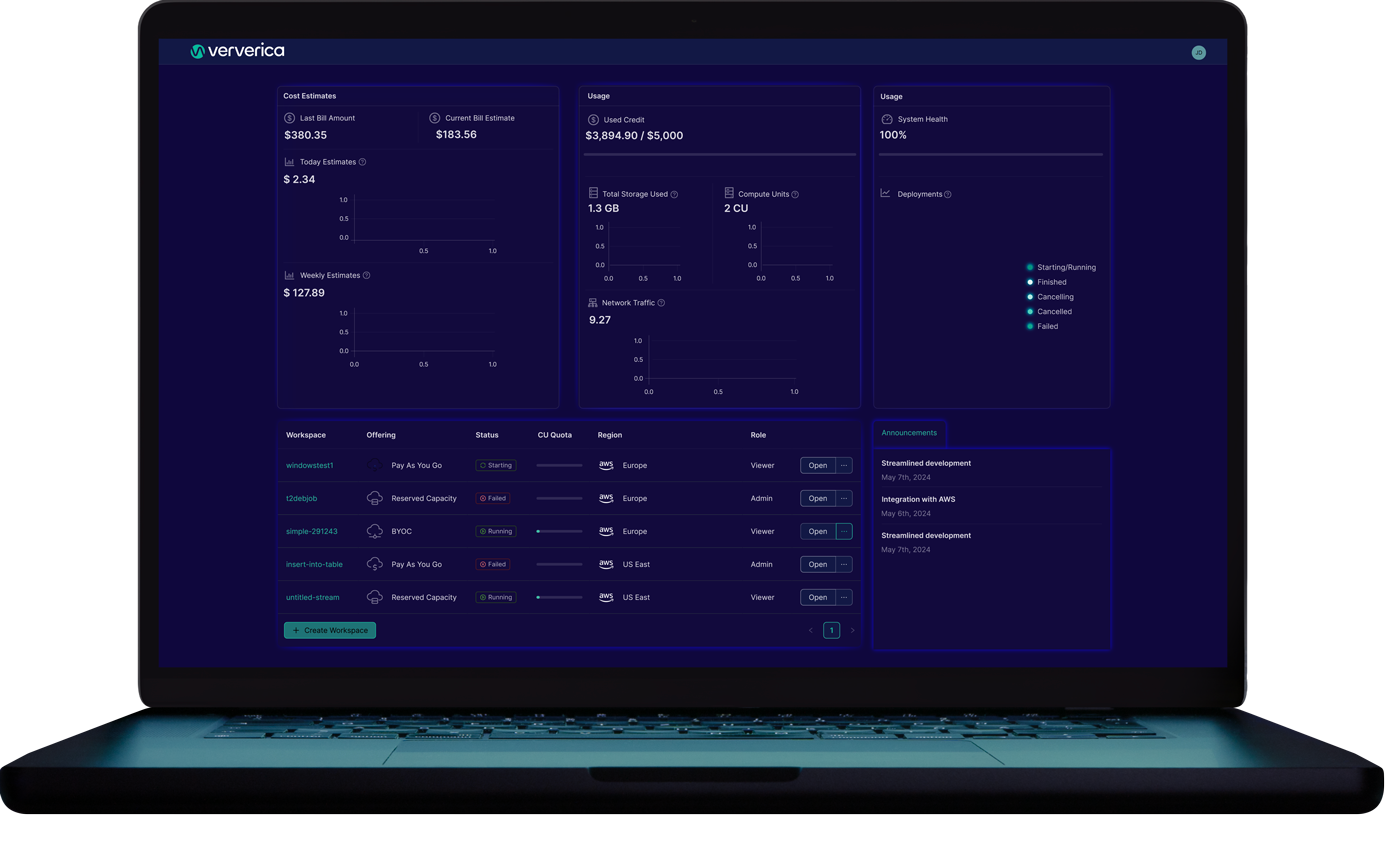

35,000 +
Jobs running on a single cluster
>10 Petabytes
Data ingested per day
>2 Million
CPU cores in an elastically scaling cluster
6.9 Billion
Records processed per second
10 Trillion
Records ingested per day
Brought to you by the original creators of Apache Flink®

Ververica Platform:
Self-Managed
Ververica Cloud:
Managed Service
Ververica Cloud:
Bring Your Own Cloud
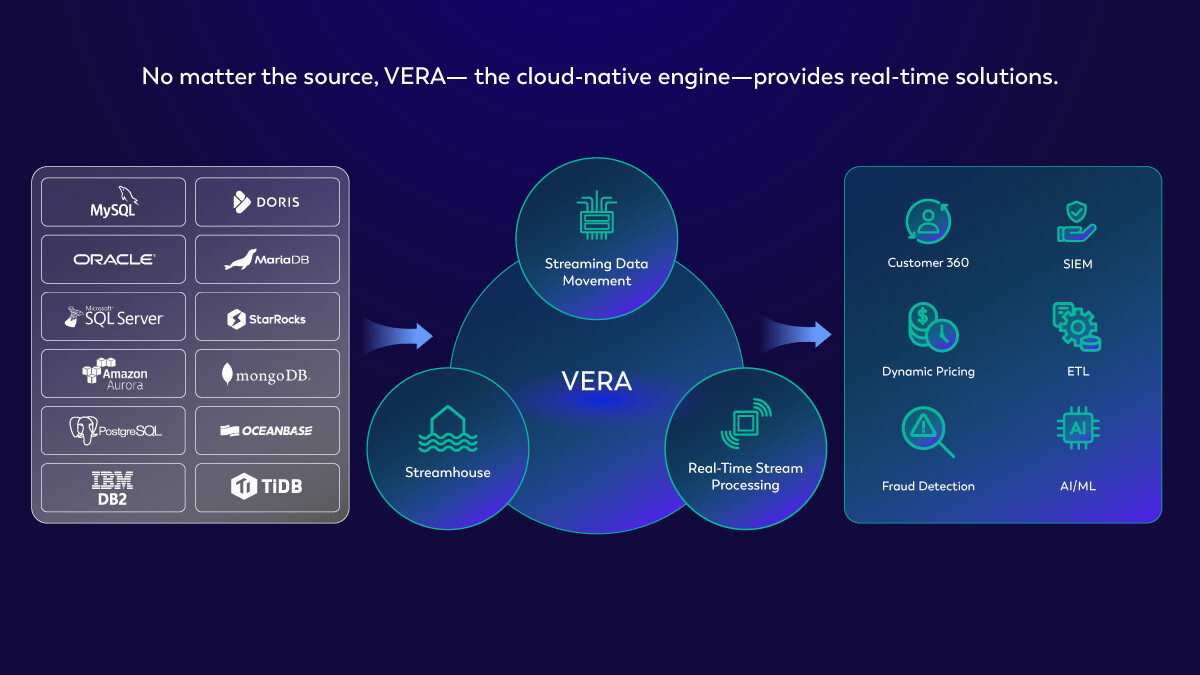
Source Data & Events
Customer
Customer
Customer
Source Integration
Unified Streaming Data Platform
VERA Engine
Public Cloud
Customer
Private Cloud
Customer
Sink Integration
Destination Data
and Events Sink Integration
Customer
Customer
Customer



Latest News

KartShoppe: Real-Time Feature Engineering With Ververica
This is a story based on a real business use case, featuring an e-commerce company (“KartShoppe”)... October 1, 2024 by Giannis Polyzos
Real-Time Insights for Airlines with Complex Event Processing
Introduction Businesses are embracing real-time data processing to better handle their... October 1, 2024 by Giannis Polyzos
Highlights from Flink Forward Berlin 2024
Flink Forward Berlin 2024 is a wrap, and Ververica is proud to have hosted the 10-year anniversary... October 1, 2024 by Karin Landers
From Kappa Architecture to Streamhouse: Making the Lakehouse Real-Time
The demand for real-time insights has transformed how businesses approach data architectures. Over... October 1, 2024 by Giannis Polyzos
The Streamhouse Evolution
A Glimpse Into the House of Streams In addition to being the heart of Ververica’s Streaming Data... October 1, 2024 by Giannis Polyzos
Streamhouse: Data Processing Patterns
Introduction In October, at Flink Forward 2023, Streamhouse was officially introduced by Jing Ge,... October 1, 2024 by Giannis Polyzos
Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling
💡What is real-time data processing, and why is it important for energy grid blackout prevention?... October 1, 2024 by Jaime López
Real-Time Fraud Detection Using Complex Event Processing
💡 What is real-time fraud detection, and how does it benefit the financial industry? Real-time... October 1, 2024 by Giannis Polyzos