Ververica was founded by the original creators of Apache Flink®, and we’ve spent a long time solving problems in the stream processing space. In this introductory write-up, we’ll provide our perspective on stream processing and where Apache Flink fits in.
Stream processing is the processing of data in motion, or in other words, computing on data directly as it is produced or received.
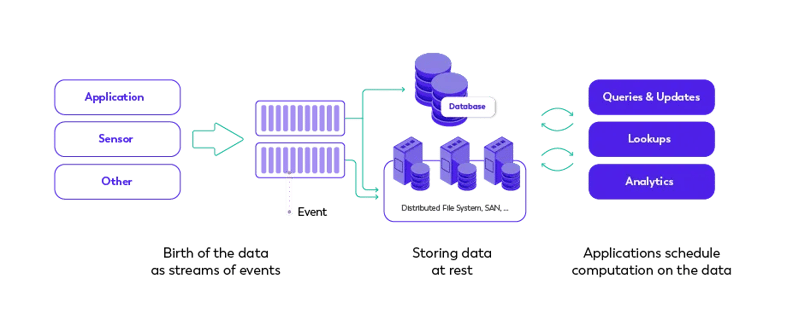
The majority of data are born as continuous streams: sensor events, user activity on a website, financial trades, and so on – all these data are created as a series of events over time.
Before stream processing, this data was often stored in a database, a file system, or other forms of mass storage. Applications would query the data or compute over the data as needed.
Stream Processing turns this paradigm around: The application logic, analytics, and queries exist continuously, and data flows through them continuously.
Upon receiving an event from the stream, a stream processing application reacts to that event: it may trigger an action, update an aggregate or other statistic, or “remember” that event for future reference.
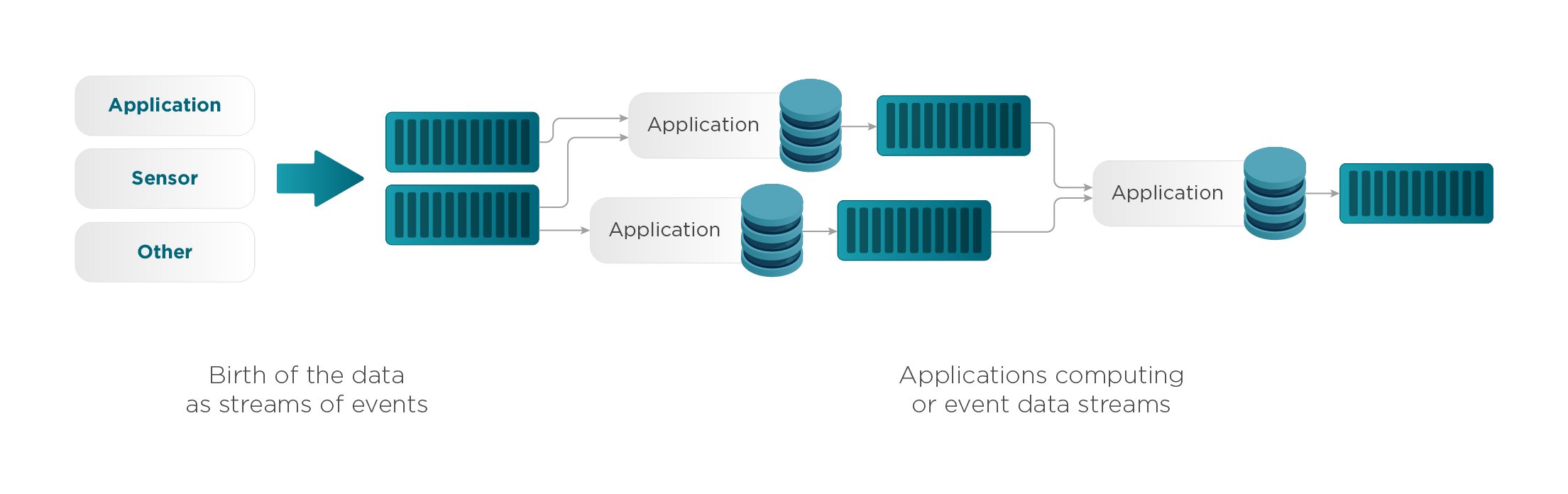
Streaming computations can also process multiple data streams jointly, and each computation over the event data stream may produce other event data streams.
{kind=link}
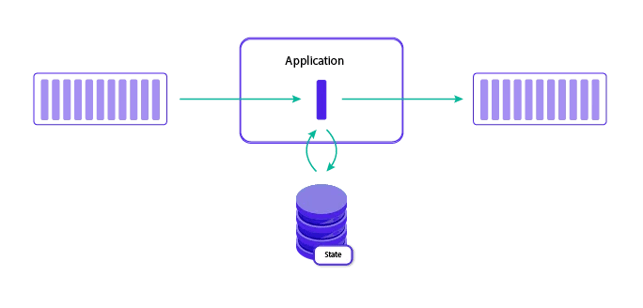
Stateful stream processing is a subset of stream processing in which the computation maintains contextual state. This state is used to store information derived from the previously-seen events.
Virtually all non-trivial stream processing applications require stateful stream processing:
-
A fraud prevention application would keep the last transactions for each credit card in the state. Each new transaction is compared to those in the state, labeled as valid or fraudulent, and the state is updated with that transaction.
-
An online recommender application would keep parameters that describe the user’s preferences. Each product interaction generates an event that updates these parameters.
-
A microservice that handles a song playlist or e-commerce shopping cart receives events for each user interaction with songs or products. The state keeps the list of all added items.
Stateful stream processing
Conceptually, stateful stream processing brings together the database or key/value store tables and the event-driven / reactive application or analytics logic into one tightly-integrated entity.
The deep integration between the state and execution of the application / analytics logic results in very high performance, scalability, data consistency, and operational simplicity.
Stateful stream processing requires a stream processor that supports state management. Apache Flink has world-class support for stateful stream processing, including the ability to handle very large state size, elastic re-scaling of stateful streaming programs, state snapshots (for versioning and application updates), and upgrade and schema evolution features.
Stream Processing unifies Data Processing, Analytics, and Applications
You probably noticed that we mentioned both real-time data processing / analytics and event-driven applications in previous sections. Are those not two different domains, with processing and analytics implemented via frameworks like Hadoop or SQL warehouses and applications implemented via application frameworks and databases?
Current approaches to data processing/analytics and event-driven applications have much in common. For analytics to produce results in real-time or near real-time, a system must continuously compute and update results with each record or event.
Modern applications and microservices also operate in an event-driven or “reactive” fashion, meaning their logic and computation is triggered by events (where events are generated, for example, by a user interacting with a website).
.webp?width=760&height=748&name=stream_processing_3-02%20(2).webp)
Stream processing unifies applications and analytics. This simplifies the overall infrastructure because many systems can be built on a common architecture, and also allows a developer to build applications that use analytical results to respond to insights in the data–to take action–directly.
For example:
-
Classifying a banking transaction as fraudulent based on an analytical model then automatically blocking the transaction
-
Sending push notifications to users based on models about their behavior
-
Adjusting the parameters of a machine based on result of real-time analysis of its sensor data
Interested in learning more? Read up on Apache Flink and its core features, or visit our blog to see real-world use cases from Apache Flink users.