














This is a guest post by Hung Chang & Mihail Vieru of Zalando. It originally appeared on the Zalando Technology Blog and was reposted here with permission.
While developing Zalando’s real-time business process monitoring solution, we encountered the need to generate complex events upon the detection of specific patterns of input events. In this blog post we describe the generation of such events using Apache Flink, and share our experiences and lessons learned in the process. You can read more on why we have chosen Apache Flink over other stream processing frameworks here: Apache Showdown: Flink vs. Spark.
This post is aimed at those familiar with stream processing in general and having had first experiences working with Flink. We recommend Tyler Akidau’s blog post The World Beyond Batch: Streaming 101 to understand the basics of stream processing, and Fabian Hueske’s Introducing Stream Windows in Apache Flink for the specifics of Flink.
Defining Business Processes
To start off, we would like to offer more context on the problem domain. Let’s begin by having a look at the business processes monitored by our solution. A business process is, in its simplest form, a chain of correlated events. It has a start and a completion event. See the example depicted below:

The start event of the example business process is ORDER_CREATED. This event is generated inside Zalando’s platform whenever a customer places an order. It could have the following simplified JSON representation:
{
"event_type": "ORDER_CREATED",
"event_id": 1,
"occurred_at": "2017-04-18T20:00:00.000Z",
"order_number": 123
}
The completion event is ALL_PARCELS_SHIPPED. It means that all parcels pertaining to an order have been handed over for shipment to the logistic provider. The JSON representation is therefore:
{
"event_type": "ALL_PARCELS_SHIPPED",
"event_id": 11,
"occurred_at": "2017-04-19T08:00:00.000Z",
"order_number": 123
}
Notice that the events are correlated on order_number, and also that they occur in order according to their occurred_at values.
So we can monitor the time interval between these two events, ORDER_CREATED and ALL_PARCELS_SHIPPED. If we specify a threshold, e.g. 7 days, we can tell for which orders the threshold has been exceeded and then can take action to ensure that the parcels are shipped immediately, thus keeping our customers satisfied.
Problem Statement
A complex event is an event which is inferred from a pattern of other events.
For our example business process, we want to infer the event ALL_PARCELS_SHIPPED from a pattern of PARCEL_SHIPPED events, i.e. generate ALL_PARCELS_SHIPPED when all distinct PARCEL_SHIPPED events pertaining to an order have been received within 7 days. If the received set of PARCEL_SHIPPED events is incomplete after 7 days, we generate the alert event THRESHOLD_EXCEEDED.
We assume that we know beforehand how many parcels we will ship for a specific order, thus allowing us to determine if a set of PARCEL_SHIPPED events is complete. This information is contained in the ORDER_CREATED event in the form of an additional attribute, e.g."parcels_to_ship": 3.
Furthermore, we assume that the events are emitted in order, i.e. the occurred_at timestamp of ORDER_CREATED is smaller than all of the PARCEL_SHIPPED’s timestamps.
Additionally we require the complex event ALL_PARCELS_SHIPPED to have the timestamp of the last PARCEL_SHIPPED event.
The raw specification can be represented through the following flowchart:
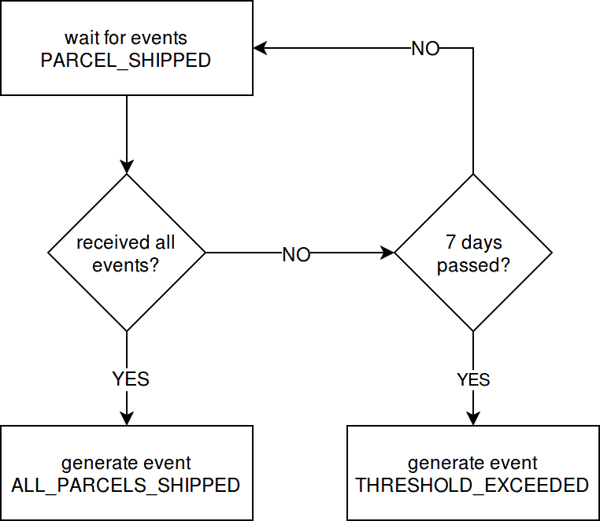
We process all events from separate Apache Kafka topics using Apache Flink. For a more detailed look of our architecture for business process monitoring, please have a look here.
Generating Complex Events
We now have all the required prerequisites to solve the problem at hand, which is to generate the complex events ALL_PARCELS_SHIPPED and THRESHOLD_EXCEEDED.
First, let’s have an overview on our Flink job’s implementation: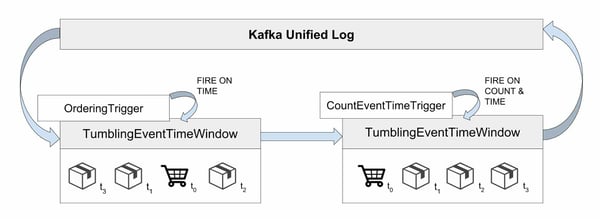
-
Read the Kafka topics ORDER_CREATED and PARCEL_SHIPPED.
-
Assign watermarks for event time processing.
-
Group together all events belonging to the same order, by keying by the correlation attribute, i.e. order_number.
-
Assign TumblingEventTimeWindows to each unique order_number key with a custom time trigger.
-
Order the events inside the window upon trigger firing. The trigger checks whether the watermark has passed the biggest timestamp in the window. This ensures that the window has collected enough elements to order.
-
Assign a second TumblingEventTimeWindow of 7 days with a custom count and time trigger.
-
Fire by count and generate ALL_PARCELS_SHIPPED or fire by time and generate THRESHOLD_EXCEEDED. The count is determined by the "parcels_to_ship" attribute of the ORDER_CREATED event present in the same window.
-
Split the stream containing events ALL_PARCELS_SHIPPED and THRESHOLD_EXCEEDED into two separate streams and write those into distinct Kafka topics.
The simplified code snippet is as follows:
// 1
List<String> topicList = new ArrayList<>();
topicList.add("ORDER_CREATED");
topicList.add("PARCEL_SHIPPED");
DataStream<JSONObject> streams = env.addSource(
new FlinkKafkaConsumer09<>(topicList, new SimpleStringSchema(), properties))
.flatMap(new JSONMap()) // parse Strings to JSON// 2-5
DataStream<JSONObject> orderingWindowStreamsByKey = streams
.assignTimestampsAndWatermarks(new EventsWatermark(topicList.size()))
.keyBy(new JSONKey("order_number"))
.window(TumblingEventTimeWindows.of(Time.days(7)))
.trigger(new OrderingTrigger<>())
.apply(new CEGWindowFunction<>());
// 6-7
DataStream<JSONObject> enrichedCEGStreams = orderingWindowStreamsByKey
.keyBy(new JSONKey("order_number"))
.window(TumblingEventTimeWindows.of(Time.days(7)))
.trigger(new CountEventTimeTrigger<>())
.reduce((ReduceFunction<JSONObject>) (v1, v2) -> v2); // always return last element
// 8
enrichedCEGStreams
.flatMap(new FilterAllParcelsShipped<>())
.addSink(new FlinkKafkaProducer09<>(Config.allParcelsShippedType,
new SimpleStringSchema(), properties)).name("sink_all_parcels_shipped");
enrichedCEGStreams
.flatMap(new FilterThresholdExceeded<>())
.addSink(new FlinkKafkaProducer09<>(Config.thresholdExceededType,
new SimpleStringSchema(), properties)).name("sink_threshold_exceeded");
Challenges and Learnings
The firing condition for CEG requires ordered events
As per our problem statement, we need the ALL_PARCELS_SHIPPED event to have the event time of the last PARCEL_SHIPPED event. The firing condition of the CountEventTimeTrigger thus requires the events in the window to be in order, so we know which PARCEL_SHIPPED event is last.
We implement the ordering in steps 2-5. When each element comes, the keyed state stores the biggest timestamp of those elements. At the registered time, the trigger checks whether the watermark is greater than the biggest timestamp. If so, the window has collected enough elements for ordering. We assure this by letting the watermark only progress at the earliest timestamp among all events. Note that ordering events is expensive in terms of the size of the window state, which keeps them in-memory.
Events arrive in windows at different rates
We read our event streams from two distinct Kafka topics: ORDER_CREATED and PARCEL_SHIPPED. The former is much bigger than the latter in terms of size. Thus, the former is read at a slower rate than the latter.
Events arrive in the window at different speeds. This impacts the implementation of the business logic, particularly the firing condition of the OrderingTrigger. It waits for both event types to reach the same timestamps by keeping the smallest seen timestamp as the watermark. The events pile up in the windows’ state until the trigger fires and purges them. Specifically, if events in the topic ORDER_CREATED start from January 3rd and and the ones in PARCEL_SHIPPED start from January 1st, the latter will be piling up and only purged after Flink has processed the former at January 3rd. This consumes a lot of memory.
Some generated events will be incorrect at the beginning of the computation
We cannot have an unlimited retention time in our Kafka queue due to finite resources, so events expire. When we start our Flink jobs, the computation will not take into account those expired events. Some complex events will either not be generated or will be incorrect because of the missing data. For instance, missing PARCEL_SHIPPED events will result in the generation of a THRESHOLD_EXCEEDED event, instead of an ALL_PARCELS_SHIPPED event.
Real data is big and messy; test with sample data first
At the beginning, we used real data to test our Flink job and reason about its logic. We found its use inconvenient and inefficient for debugging the logic of our triggers. Some events were missing or their properties were incorrect. This made reasoning unnecessarily difficult for the first iterations. Soon after, we implemented a custom source function, simulated the behaviour of real events, and investigated the generated complex events.
Data is sometimes too big for reprocessing
The loss of the complex events prompts the need to generate them again by reprocessing the whole Kafka input topics, which for us hold 30 days of events. This reprocessing proved to be unfeasible for us. Because the firing condition for CEG needs ordered events, and because events are read at different rates, our memory consumption grows with the time interval of events we want to process. Events pile up in the windows’ state and await the watermark progression so that the trigger fires and purges them.
We used AWS EC2 t2.medium instances in our test cluster with 1GB of allocated RAM. We observed that we can reprocess, at most, 2 days worth without having TaskManager crashes due to OutOfMemory exceptions. Therefore, we implemented additional filtering on earlier events.
Conclusion
Above we have shown you how we designed and implemented the complex events ALL_PARCELS_SHIPPED and THRESHOLD_EXCEEDED. We have shown how we generate these in real-time using Flink’s event time processing capabilities. We have also presented the challenges we’ve encountered along the way and have described how we met those using Flink’s powerful event time processing features, i.e. watermark, event time windows and custom triggers.
Advanced readers will be aware of what the CEP library Flink offers. When we started on our use cases (Flink 1.1), we determined that these cannot be easily implemented with it. We believed that full control of the triggers gave us more flexibility when refining our patterns iteratively.
In the meantime, the CEP library has matured, and in the upcoming Flink 1.4 it will also support dynamic state changes in CEP patterns. This will make implementations of use cases similar to ours more convenient.
If you have any questions or feedback you’d like to share, please get in touch. You can reach us via e-mail: hung.chang@zalando.de and mihail.vieru@zalando.de.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow

Meet the Flink Forward Program Committee: A Q&A with Yuan Mei

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti
