













The Hyperconnect team attended Flink Forward for the first time a couple of months back and presented how we utilize Apache Flink to perform real time matchmaking for the video-based social discovery and communication platform Azar. In the following sections, we will describe our motivation behind moving to a distributed, streaming architecture to perform machine learning in real time, the reasons for choosing Apache Flink and the different layers of our matchmaking streaming architecture.
About Hyperconnect and Azar
Hyperconnect is a technology-based company and the first in the world, to develop a WebRTC technology that could be used on mobile platforms. Based on this technology, Hyperconnect developed Azar, a social discovery platform that utilizes video to connect people from around the world. Azar is revolutionizing the way people make new friends and communicate with others using technology powered by machine learning. The app can be accessed on mobile and allows you to talk and make friends with people from over 230 countries. Azar has over 400 million downloads worldwide while the platform has completed more than 80 billion matches!

Why we chose Flink for our Matchmaking service
Azar has been growing very rapidly and the platform is now handling at peak times more than 180 million discoveries daily (the action of “swiping left” in the live video of your mobile screen). In order to ensure that Azar’s matchmaking service is able to support this ongoing increase in user activity and engagement, we redesigned our matchmaking service bringing Apache Flink at the core of its architecture. Flink was chosen as the preferred data processing framework since it provided the necessary scalability, stability and capacity to handle stateful computations over large amounts of data.
-
ScalabilityDuring peak times, our system handles more than 5,000 match requests per second and processes more than 12 million pairwise computations per second to provide the optimal results for the user.
-
StabilityThe matchmaking service is mission-critical and a core function of our product offering, and as a result, we need the response time of the returning results in milliseconds while there should be zero downtime to the service since it directly impacts our business and the user experience in our app.
-
Handling stateful computationsIn order to improve our matchmaking algorithm, it was essential to keep some state about the users. Our previous stateless computations resulted in indirect workarounds that had a direct impact on the latency of our computations and the overall complexity of our event streaming pipelines. As a result, we decided to redesign the matchmaking service from the ground up.
Apache Flink was uniquely positioned to perform low latency iterations, resulting in an overall feedback cycle for our pipeline computations of less than a second. Additionally, Flink’s operator-based, loosely-coupled architecture could support us in improving the quality of the original matchmaking system by adding more potential candidate pairs with multiple scores through the scoring exploration process. Finally, Flink’s intrinsic support for state management allowed us to deliver more value to our users by implementing a real-time inference pipeline performing stateful computations based on Flink’s state and memory management architectures. All of the above provided a scalable and stable system for our real time matchmaking service.
HyperMatch Architecture for data-driven Matchmaking at Azar
In order to get a better understanding of our system’s architecture, let’s explain how matchmaking is executed at Hyperconnect and Azar. Traditionally, matchmaking evolves around matching two or more entities together. In order to perform real time matchmaking at Azar, we collect match requests from specific individuals in a specific time window and we try to match the best pairs among them with low latency. We have broken down our Flink-based real time matchmaking system in six steps:
1. Collect Source (Data & Input Source)2. Feature Engineering3. Pair Generation4. Scoring Operation5. Pair Aggregation (i.e. “Matchmaker”)6. Output to multiple sinks
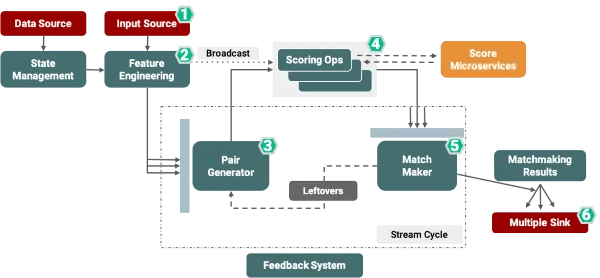
Figure 1: HyperMatch Architecture at Hyperconnect and Azar
Our matchmaking process starts with the Handling Source collecting match requests from different clients through custom Netty HTTP sources, allowing us to improve the system’s response time to closer to real time.
The second step in the matchmaking process is the Feature Engineering step including processes such as vectorizing, segmentation and user tagging. Data in this step is pre-processed before entering the match cycle, including conditional tagging for segmentation (i.e. performing A/B tests) or vectorization of user features for machine learning models to be then utilized by our Score Matching Operation. In this step the state backend of our Flink job manages the user’s matching history, taking into account users’ preferences and characteristics.
The third step of our architecture consists of the Pair Generator service that collects matchmaking requests and generates pairs before passing them for scoring calculation. In this step, the operator collects match requests using Flink’s Window API with a keyed tumbling window.
The next step in our matchmaking process is our Scoring Operation. Here we adapt the multiple scoring logics in parallel to get optimized results, so multiple teams in the organization can get involved in the advancement of the scoring logic. During this step we manage the matchability matrix globally and use it in each scorer to implement a Multi Armed Bandit for improving the matching quality. The Score Operator is responsible for calculating all the pairs’ scores and responds back in time. For that, we parallelize each scorer group. The communication with each scoring microservice is based on a REST API and it utilizes Apache Flink’s AsyncDataStream operation.
The fifth step in the HyperMatch system is the MatchMaker service that selects the best pair based on the results of the scoring operation. The service aggregates the results of the different scoring microservices in a fault-tolerant manner and selects the best pairs through the implementation of our custom triggers and evictors as well as a distributed sorting algorithms that significantly enhance the performance of the MatchMaker service. Here, successful pairs will be passed to the Matchmaking Results service, while the leftover pairs are being redirected back to the Pair Generator (step 3) using Flink’s iterative streaming function.
The final step of the matchmaking process includes the Matchmaking Results service This service has multiple functions such as delivering the best pair into one of our matchmaking brokers as a sink, showing the actual client-to-client video matching. The service additionally distributes the results and provides feedback for improving the performance of future matches or sends the results to our logging & metrics reporters.
The Flink-based HyperMatch architecture described above is deployed in our production environments using Kubernetes as the underlying resource management framework. Utilizing Kubernetes allows high-availability (HA) with our Flink deployments and makes setting up new staging infrastructure for performance testing easy and frictionless. To achieve zero downtime for such a mission-critical real time data application, we have configured our deployment pipeline based on a Blue/Green architecture.
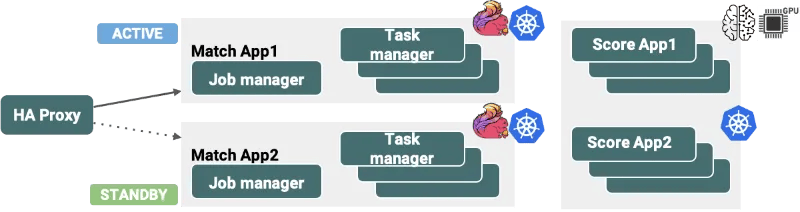 Figure 2: Blue/green Deployment approach on Kubernetes
Figure 2: Blue/green Deployment approach on Kubernetes
In the previous sections of this post, we explained why we chose Apache Flink to migrate our matchmaking service to a real time, event streaming architecture and achieve the stability and scalability to perform machine learning and pair generation at large scale. Using Flink enabled us to realize stateful matchmaking based on our redesigned matchmaking system and enabled us to serve multiple training models and provide a better experience for our users. If you want to find out more information about the use of Flink at Hyperconnect and Azar, you can watch the recording of our Flink Forward session on the Flink Forward Youtube channel or get in touch with the team for more information.


About the authors:
 Jacob Oh is a senior software engineer and team leader at Hyperconnect. The Data Application Team is designing, developing and maintaining Hyperconnect's Recommendation Engine (Such as Azar's matchmaking system). Hyperconnect is the company serving the services like Azar based on Real-time Communication and ML Tech. With the experiences on researching UX and engineering Applications, he designs and develops the products to make a better service experience.
Jacob Oh is a senior software engineer and team leader at Hyperconnect. The Data Application Team is designing, developing and maintaining Hyperconnect's Recommendation Engine (Such as Azar's matchmaking system). Hyperconnect is the company serving the services like Azar based on Real-time Communication and ML Tech. With the experiences on researching UX and engineering Applications, he designs and develops the products to make a better service experience.
 Gihoon Yeom has worked as a software engineer for 4 years at HyperConnect. He is interested in using data to create new value and has focused on real-time distributed data engineering projects using Spark and Flink.
Gihoon Yeom has worked as a software engineer for 4 years at HyperConnect. He is interested in using data to create new value and has focused on real-time distributed data engineering projects using Spark and Flink.
You may also like

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure

Data Sovereignty Is Existential Most Platforms Treat It Like a Feature
