














This post originally appeared on the Dell EMC blog. It was reproduced on the Ververica blog with permission from its author.
Every single entity in the digital world, be it an end user or a sensor device, continuously produces activity updates. People leave traces of their activity when they shop online or use any other online application. Machines then report on actions and statuses. Capturing such traces and reports in the form of data streams enables software applications that digitally reconstruct the history of these entities to allow queries against the data and actionable insights. The same is true for applications that represents these streams in different formats.
To satisfy the demanding requirements of such applications, we developed the Dell EMC Streaming Data Platform (SDP). The solution ingests, stores and processes data continuously, mapping the software abstractions more naturally to those types of applications. The centerpiece of our SDP platform is the open source storage system called Pravega.
While ingesting and storing are critical functions of any data pipeline, a streaming data solution needs a stream processor that can benefit from the features that Pravega offers. Pravega exposes streams as storage primitive, enabling applications to ingest and consume data in a stream form. Pravega streams accommodate an unbounded amount of data while being both elastic and consistent.
Apache Flink, a unique framework in the space of data analytics, offers powerful functionality for processing both unbounded and bounded data sets. When used in conjunction with Pravega, Apache Flink can tail, or historically process, data using the same source, while providing end-to-end, exactly once semantics, and dynamically adapt to resource demands. The combination of Pravega and Apache Flink in the Streaming Data Platform raises the bar for stream processing platforms. It brings an unprecedented level of features that have long been needed to fulfill the requirements of existing and future applications.
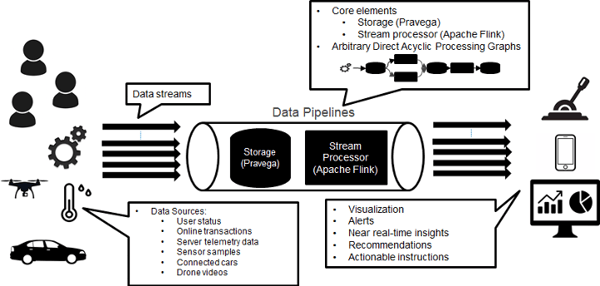
Figure 1: Data pipelines with Pravega and Flink in SDP
The future
Dell Technologies envisions a world in which data streams are ubiquitous and stream processing is the new norm for modern application development. Stream applications are already prevalent, but there’s a clear increase in demand and scale for systems that process stream data. We are excited about this future and the opportunity to build the systems that can help our customers’ applications process stream data efficiently and effectively.
The combination of Pravega and Flink in the Streaming Data Platform to compose data pipelines already provides unique possibilities. The partnership between Dell Technologies and Ververica will further enable us to build features for data pipelines that will help organizations simplify storage needs, create a foundation of unified data and innovate using an endless array of applications. We look forward to working together to deliver streaming data technology that continues to provide meaningful outcomes for our customers.
To learn more about Pravega and Flink, explore the two sessions from the Flink Forward Virtual Conference 2020 by visiting the Flink Forward YouTube Channel. There, you can see the keynote, “Stream analytics made real with Pravega and Apache Flink” with Srikanth Satya, VP of Engineering at Dell Technologies, and “Everything is connected: How watermarking, scaling, and exactly once impact one another in Pravega,” presented by myself, Flavio Junqueira, Senior Distinguished Engineer at Dell Technologies.
About the author:
 Flavio Junqueira leads the Pravega team at DellEMC. He holds a PhD in computer science from the University of California, San Diego and is interested in various aspects of distributed systems, including distributed algorithms, concurrency, and scalability. Previously, Flavio held a software engineer position with Confluent and research positions with Yahoo! Research and Microsoft Research. Flavio has contributed to a few important open-source projects. Most of his current contributions are to the Pravega open-source project, and previously he contributed and started Apache projects such as Apache ZooKeeper and Apache BookKeeper. Flavio co-authored the O’Reilly “ZooKeeper: Distributed process coordination” book.
Flavio Junqueira leads the Pravega team at DellEMC. He holds a PhD in computer science from the University of California, San Diego and is interested in various aspects of distributed systems, including distributed algorithms, concurrency, and scalability. Previously, Flavio held a software engineer position with Confluent and research positions with Yahoo! Research and Microsoft Research. Flavio has contributed to a few important open-source projects. Most of his current contributions are to the Pravega open-source project, and previously he contributed and started Apache projects such as Apache ZooKeeper and Apache BookKeeper. Flavio co-authored the O’Reilly “ZooKeeper: Distributed process coordination” book.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
