














We are thrilled to announce the launch of Stateful Functions (statefun.io), an open source framework that reduces the complexity of building and orchestrating distributed stateful applications at scale. Stateful Functions brings together the benefits of stream processing with Apache Flink® and Function-as-a-Service (FaaS) to provide a powerful abstraction for the next generation of event-driven architectures.
This blog post will introduce you to the why, what and how of Stateful Functions, including the motivation behind proposing the project to the Apache Flink community as an open source contribution.

The problem: stateful applications are still hard
Orchestration for stateless compute has come a long way, driven by technologies like Kubernetes and FaaS — but most offerings still fall short when it comes to stateful distributed applications by focusing primarily on computation, not state. Also, the interaction between functions still poses challenges to the overall ease of development and distributed data consistency.
Stateful Functions API
The API is based on, well, stateful functions: small snippets of functionality that encapsulate business logic, somewhat similar to actors. These functions exist as virtual instances — typically, one per entity in the application (e.g. per user or stock item) — and are distributed across shards, making applications horizontally scalable out-of-the-box. Each function has persistent user-defined state in local variables and can arbitrarily message other functions (including itself!) with exactly-once guarantees.
Runtime
The runtime that powers Stateful Functions is based on stream processing with Apache Flink. State is kept in the stream processing engine, co-located with the computation, giving you fast and consistent state access. State durability and fault tolerance build on Flink’s robust distributed snapshots model.
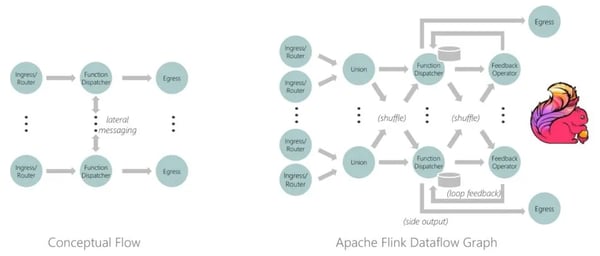 Figure 1
Figure 1
Computing over state, not from state
The framework is not meant as a replacement for FaaS or (even) serverless — instead, it is designed to provide a set of properties similar to what characterizes serverless compute, but applied to state-centric problems.
State-centric
Stateful Functions primarily scales state and the interaction between different states and events, with logic that facilitates these interactions as the main focus of computation. Event-driven applications, that juggle interacting state machines and need to remember contextual information, are a good fit for the state-centric paradigm.
Compute-centric
On the other hand, FaaS and serverless application frameworks excel at elastically scaling dedicated resources for computation. Interacting with state and other functions is not as well integrated and not their core strength. A good example of fitting use cases is the classical “Image Resizing with AWS Lambda”.
 Figure 2
Figure 2
To achieve this, the runtime underneath the Stateful Functions API relies on stream processing with Apache Flink and extends its powerful model for state management and fault tolerance. The major advantage of this model is that state and computation are co-located on the same side of the network — which means you don’t need the round-trip per record to fetch state from an external storage system (e.g. Cassandra, DynamoDB) nor a specific state management pattern for consistency (e.g. event sourcing, CQRS). Other advantages include:
-
No need to manage in-flight messages and maintain complex replication or repartition strategies, as persistence is as simple as having an object store for state snapshots;
-
High throughput for both stream (fast real-time) and batch (offline) processing, allowing you to blur the boundaries between event-driven applications and generic data processing.
Stateful Functions splits compute and storage differently than the classical two-tier architecture, maintaining: one ephemeral state/compute tier (Apache Flink) and a simple persistent blob storage tier (Fig. 2). Programatically, persistence is based on the concept of persisted values that enable each function instance to maintain and track fault-tolerant state independently.
Extending the scope of stream processing
Although the Stateful Functions API is independent of Flink, the runtime is built on top of Flink’s DataStream API and uses a lightweight version of process functions (i.e. low-level functions accessing state) to materialize this abstraction under the hood. The core advantage here, compared to vanilla Flink, is that functions can arbitrarily send events to all other functions, rather than only downstream in a DAG.
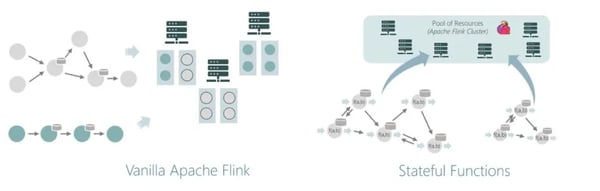 Figure 3
Figure 3
Stateful Functions applications are typically modular, containing multiple bundles of functions, that can interact consistently and reliably, multiplexed into a single Flink application (Fig. 3). This allows many small jobs to share the same pool of resources and harness them as needed, instead of requiring upfront the resources you might need at peak. At any point in time, the vast majority of virtual instances are idle and consume no compute resources.
Get started with Stateful Functions
If you find this project interesting, give Stateful Functions a try! To get started, have a look through the documentation and follow one of the introduction walkthroughs, going from a simple stateful “Hello World!” (Fig.4) to a more complex Ride Sharing App.
 Figure 4
Figure 4
If you find a bug or have an idea about how to improve something, we strongly encourage you to file an issue or open a pull request on GitHub! At any time, you can ask us questions on Stack Overflow, too, using the hashtag #statefun.
Upcoming work
Stateful Functions is a work in progress with what we believe is a promising direction. Our team will continue to introduce improvements to establish and amplify the value of the project, such as support for non-JVM languages, fine-grained observability and stricter recovery times. Possibilities for enhancements to the runtime and operations will also evolve with the evolution of capabilities of Apache Flink.
Our goal is to contribute Stateful Functions to the Apache Software Foundation and make it part of Apache Flink. Developing in an open community, in close collaboration with real people solving real problems is — for us — the best way to learn and grow. Nevertheless: the decision whether to accept this project as a contribution ultimately rests with the Flink community.


You may also like

Ververica Platform 3.0: The Turning Point for Unified Streaming Data

Introducing Apache Fluss™ on Ververica’s Unified Streaming Data Platform

VERA-X: Introducing the First Native Vectorized Apache Flink® Engine
