














It’s official: on June 1, the Apache Flink® community announced the release of Flink® 1.3.0.
The announcement on the project site and the changelog provide detail on what’s included in the release. In this post, we’ll look instead at how 1.3.0 serves as an important step in Flink’s maturation since March 2016’s 1.0.0 release.

Flink’s evolution over the past 14 months mirrors how usage of the project has evolved, too. These days, we at data Artisans see many Flink users with:
-
Applications that go beyond analytics and act on data in real-time
-
Applications running at large scale and with very large state
-
Applications with a more diverse set of Flink users who require higher-level APIs for interacting with Flink
-
Applications that run 24/7 on modern container infrastructures
Next, we’ll look at each of these categories in more detail.
APIs for Event-driven Stream ProcessingScalability and Large State Handling
Beyond the DataStream API: High-level & Domain-specific
Application Management, Deployment, and Ecosystem
Open Source Community Growth
APIs for Event-driven Stream Processing
In the past year, we’ve seen many instances of Flink users building not only real-time analytics platforms, but also applications that act on insights from analytics in real-time. This “convergence of real-time analytics and data-driven applications”, as our CTO Stephan Ewen has called it, was a recurring theme at Flink Forward San Francisco in April.
And Flink’s streaming APIs have evolved to meet the needs of these use cases, enabling true event-driven stream processing.
-
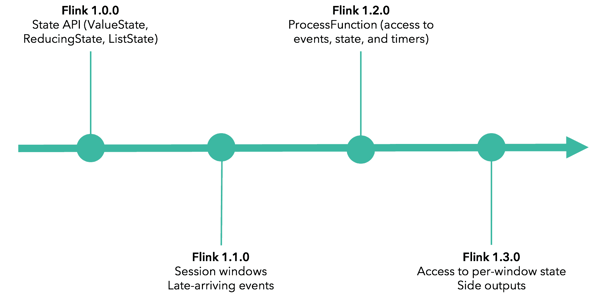
Flink 1.0.0 introduced the current state API with ValueState, ReducingState, ListState, and more.
-
Flink 1.1.0 added first-class support for session windows, enabling users to generate windows based on periods of inactivity (representing the end of a “session”) as well as support for late element handling.
-
Flink 1.2.0 introduced ProcessFunction, a flexible operator that provides access to all of the key building blocks of streaming applications: events, state, and timers without imposing a mode of thinking around windowing or CEP.
-
Flink 1.3.0 provides access to per-window state, a feature that greatly increases the utility of ProcessWindowFunction, as well as side outputs, which make it possible to remove corrupted input data while preventing a job from failing and also to remove sparsely-received late-arriving events.
Scalability and Large State Handling
A stream processor capable of low latency and high throughput can only be useful if it also includes robust tooling for state management and failure recovery--both of which are critical for managing continuous applications in a high-stakes production environment.
And so the Flink community has added support for a range of features to accommodate the increasing size of state and the scale of data processed by Flink applications.
-
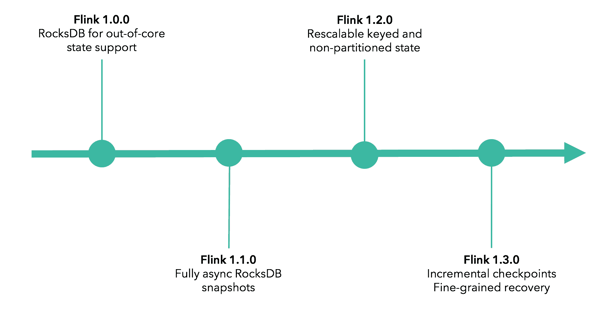
Flink 1.0.0 added RocksDB for out-of-core state support, enabling active state in a streaming program to grow well beyond memory.
-
Flink 1.1.0 added support for fully asynchronous snapshots for RocksDB.
-
Flink 1.2.0 added support for rescalable partitioned (keyed) and non-partitioned state, meaning that a user can restart Flink a job with a different parallelism via a savepoint without losing state. This allows for easily scaling a stateful job to more machines.
-
And asynchronous checkpoints for RocksDB were enabled by default in Flink 1.2.0, reducing the time an operator is not processing incoming data to a minimum.
-
-
Flink 1.3.0 introduces incremental checkpoints for RocksDB, allowing users to take a checkpoint of state updates only since the last successful checkpoint. This is a meaningful performance enhancement for jobs with very large state--early testing of the feature by production users shows a drop in incremental checkpoint time from more than 3 minutes down to 30 seconds for a checkpoint--because the full state does not need to be transferred to durable storage on each checkpoint.
-
Flink now also has support for asynchronous checkpoints for all state backends.
-
1.3.0 also adds beta support for fine-grained recovery, meaning more efficient recovery from failure by reducing the amount of state transferred upon recovery.
-
Beyond the DataStream API: High-level & Domain-specific APIs
There’s been significant progress in the past year on the Flink APIs beyond the DataStream API, and two relevant examples are the Table & SQL API and the complex event processing (CEP) library.
The Flink community has long requested high-level APIs that make stream processing more accessible to users who aren’t proficient Java or Scala developers. Flink’s Table & SQL API achieves just that, making stateful stream processing available via SQL, the standard language for data manipulation.
And Flink’s CEP library makes it easy to detect complex event patterns in a stream of endless data--a use case that’s particularly well-suited for a stateful stream processor.
-
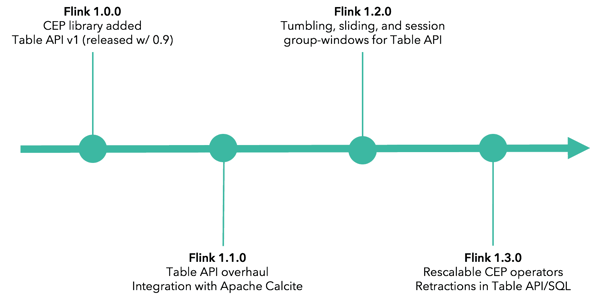
Flink 1.0.0 introduced FlinkCEP, and the first version of Flink’s Table API had been added in Flink 0.9.
-
Flink 1.1.0 included a Table & SQL API overhaul (along with an Apache Calcite integration).
-
Flink 1.2.0 added several Table API & SQL features, including tumbling, sliding, and session group-window aggregations as well as SQL support for more built-in functions and operations, such as EXISTS, VALUES, LIMIT, and more.
-
Flink 1.3.0 Flink 1.3.0 delivers, among other things, support for retractions from Dynamic Tables as well as many new aggregation types (e.g. SQL OVER windows, GROUP BY windows, user-defined aggregates) for the Table & SQL API and a number of new CEP operators, which are also now rescalable.
Application Management, Deployment, and Ecosystem
Where your application runs and how you ensure it’s working as expected are equally as important as development, if not more so.
The Flink community has added a broad range of features that make it easier to deploy, manage, and monitor long-running Flink applications within the broader ecosystem.
-
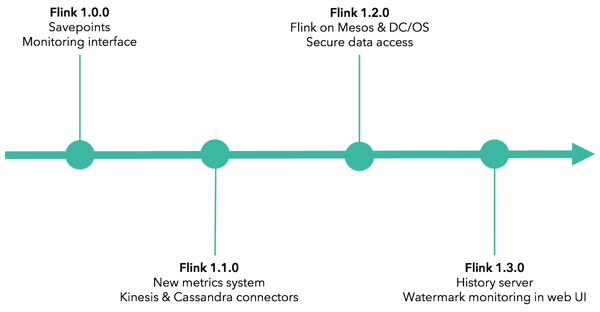
Flink 1.0.0 introduced savepoints, a feature that greatly eases the management of long-running Flink applications. Savepoints enable code updates, framework upgrades, A/B testing of different versions of an application, and more--all without losing application state.
-
Flink 1.1.0 added a new metrics system as well as connectors to Amazon Kinesis and Apache Cassandra, two widely-used source / sink systems.
-
Flink 1.2.0 added first-class support for Apache Mesos and DC/OS and the ability to authenticate against external services such as Zookeeper, Kafka, HDFS and YARN using Kerberos.
-
Flink 1.3.0 introduces a history server, making it possible to query the status and statistics of completed jobs that have been archived by a JobManager, as well as web UI tooling to help with the diagnosis of watermark issues.
Open Source Community Growth
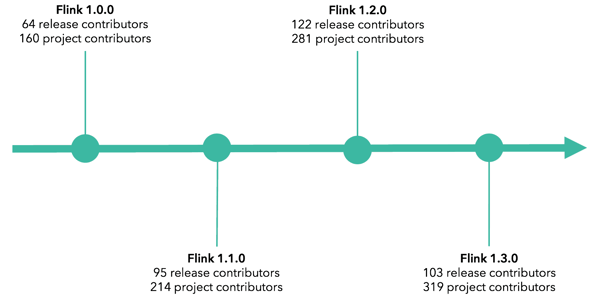
Given what we’ve covered so far, it’s no surprise that the number of contributors in the Flink community has grown considerably since last year, too.
The Flink 1.0.0 release announcement from March 2016 notes that there were 64 people who contributed to the release, and the Flink project as a whole had only approximately 160 contributors at that time.
Over 100 people contributed to the Flink 1.3.0 release, and at the time of publication, there were 319 Flink contributors listed in Github--nearly 100% increase in contributors to the project! The number of Jira issues covered by a release has increased, too. Flink 1.0.0 resolved 450 Jira issues, while 1.3.0 resolved over 680.
Note that Flink 1.1.0->1.2.0 spanned 7 months, while Flink 1.2.0->1.3.0 spanned only 4 months.
Flink 1.4.0 development is already underway, and the 1.4.0 release is scheduled for end of September 2017.
We encourage you to become a contributor, or if you have questions about using Flink, to reach out via the community mailing list.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
