














Apache Flink (incubating) is a new project undergoing incubation in the Apache Software Foundation. Flink is a new approach to distributed data processing for the Hadoop ecosystem. We believe that Flink embodies the next evolutionary step in distributed computation engines in the Hadoop ecosystem. Flink is built on the principle:
Write like a programming language, execute like a database.
Using Flink is easy for programmers that are familiar with current popular tools in the Hadoop ecosystem. However, under the hood, Flink introduces several new innovative features that make Flink applications very performant, robust, as well as easy to use and maintain.
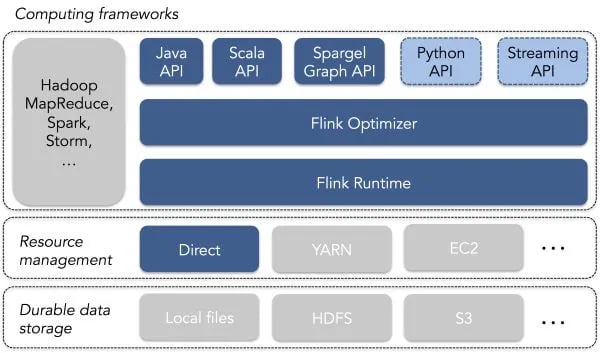
Flink users write programs using one of Flink’s APIs - currently Flink offers APIs in Java and Scala, as well as Spargel, an API that implements a Pregel programing model. Other APIs, such as a Python API and a data streaming API are under development. Flink’s APIs mostly follow the familiar model of bulk transformations on distributed object collections, popularized initially by MapReduce and extended by Apache Spark.
You can find many Flink example programs here and here.
While Flink offers a familiar packaging, the internals of the system contain very unique technology that set it apart from other available DAG processing systems.
-
In-memory and on-disk: users do not need to optimize the memory usage and behavior of their programs
-
Program optimization: users do not need, to a large extend, to tune their applications for performance.
-
Batch and streaming: users will be able to combine true streaming and batch processing applications in one system.
-
Native iterations: the system offers a built-in mechanism for looping over data that makes machine learning and graph applications especially fast.
In-memory and on-disk processing
Current engines for data processing are designed to perform their best in one of two cases: when the working set fits entirely in memory, or when the working set is too large to fit in memory. Flink’s runtime is designed to achieve the best of both worlds: Flink has great performance when the working set fits in memory, and is still be able to keep up very gracefully with “memory pressure” from large datasets that do not fit in memory, or from other cluster applications that run concurrently and consume memory.
Program optimization
In Flink, the code that the user writes is not the code that is executed. Rather, job execution in Flink is preceded by a cost-based optimization phase that generates the executable code. This phase chooses an execution plan for the program that is tailored the specific data sets (using statistics of the data) and cluster that the program will be executed on. This greatly helps the portability and ease of maintenance of Flink applications, improves developer productivity as programmers do not have to worry about low-level optimizations, and guarantees good execution performance. One benefit of optimization is that Flink applications can largely sustain underlying data changes and changes to cluster utilization without a need for rewriting or re-tuning to reflect these changes. Another common benefit is "write once, run everywhere," e.g., when users develop applications locally in their laptops, and then move them to cluster execution without needing to change the application code.
Batch and streaming
Another divide often talked about is between batch and stream processing systems. Flink is a batch processing system backed by a streaming runtime engine. Confused? Flink's runtime is not designed around the idea that operators wait for their predecessors to finish before they start, but they can already consume partially generated results. This is called pipeline parallelism and means that several transformations in a Flink program are actually executed concurrently with data being passed between them through memory and network channels. The end result is very robust performance, but also the ability to mix in the future batch and true stream processing in the same system. The community has already created a data streaming prototype on top of Flink that will be available soon.
Natively iterative processing
Iterative data processing, i.e., running programs that loop over the data many times has attracted a lot of attention recently due to the increasing importance of applications that involve training Machine Learning models or applications that work on graph-shaped data. Flink introduces dedicated "iterate" operators that form closed loops and allow the system to reason about and optimize iterative programs instead of treating an iterative program as multiple invocations of independent jobs (i.e, extenal loops). Both external and closed loop iterations have their use cases, and it is beneficial to have both under the umbrella of one system.
Flink’s community, history, and ecosystem
Flink has its origins in the data management research community of Berlin, and in particular in the Stratosphere research project. When starting Stratosphere in 2009, researchers set out to create an open source system that combines the benefits of a MapReduce engine with those of traditional Database Management System (DBMS) engines, creating a deep hybrid of the two. Over the years Stratosphere grew into an active open source project with contributors from academia and industry. The community decided that the Apache Software Foundation would offer a more permanent roof and help establish the development and community processes of the project. Although Flink is a very new project in the Apache ecosystem, it has already a stable community that is growing very fast. So far, more than 50 people have contributed to the code. The project has added three committers (congrats Till, Marton, and Gyula!) since entering the Apache Incubator. Finally, there is growing interest in integrating Flink with other projects. Some early signs of such efforts are Apache MRQL (incubating) running on Flink, and an ongoing effort to integrate Flink with Apache Tez, and Flink with Apache Mahout. Recently, a team of core committers of Apache Flink created a new Berlin-based company, Data Artisans, committed to developing Flink further, always in the open.
Summary
With this blog post, I tried to shed some light into some of the exciting new technologies and design choices behind Flink and how these are beneficial for the end user. Of course, this was by no means a deep dive or an exhaustive list of Flink's cool features! Stay tuned in this blog, where the developers of Data Artisans will post a lot more detailed posts on how Flink works. Flink is under active development, and the community is working on a wealth of new features. At the same time, the system is stable and ready to use. Try out Flink now!

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
