














In November 2017, data Artisans conducted a second-annual Apache Flink user survey. There were a total of 217 responses, and the survey provided of lots of useful insights and feedback about Flink.
At the end of 2017, we put out a press release with some of the highlights from the survey. In this post, we’re going to recap some of the key takeaways from survey data, and we’ll also share (anonymously) responses to open-ended questions from users who gave us permission to do so.
Separately, we’re in the process of compiling a report with all survey data that we’ll make available for download from our website--stay tuned for that.
First, here are a few highlights from the survey data.
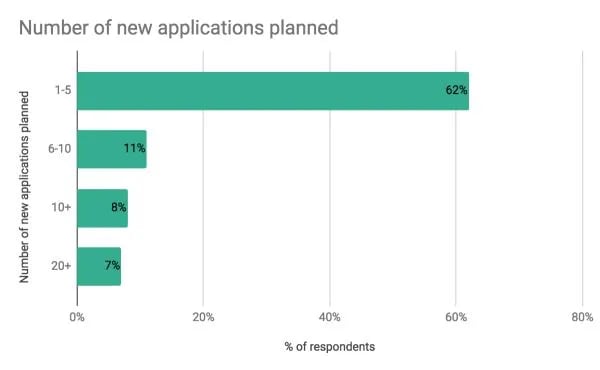
Apache Flink users are planning to do more with Flink in the coming year. 87 percent of survey respondents plan to deploy more Flink applications in the coming year. How many applications are planned? Of users whose organizations are planning to deploy more applications:
-
62 percent expect to deploy one to five more applications
-
11 percent say six to 10 more applications
-
8 percent say 10+ applications
-
7 percent expect to deploy 20+ additional applications in 2018
Machine learning is on users’ roadmaps. Many respondents who are planning to deploy new applications will be using Flink for machine learning, both for model scoring and serving (34 percent) and model training (30 percent). A range of other types of applications are planned, too:
-
27 percent will build anomaly detection/system monitoring applications
-
25 percent will build business intelligence/reporting applications
-
22 percent will build recommendation & decisioning engines
-
19 percent will build applications for security & fraud detection

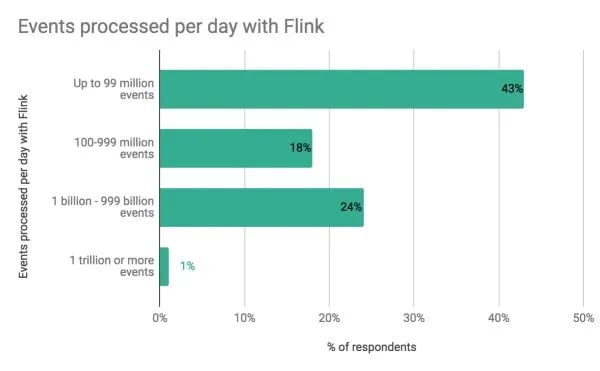
25 percent of respondents are using Flink to process more than 1 billion events per day. And 1 percent are processing more than a trillion events per day. Here’s a breakdown:
-
1 percent process 1 trillion or more events per day
-
24 percent process between 1 billion and 999 billion events per day
-
18 percent process from 100-999 million events per day
-
43 percent process up to 99 million events per day
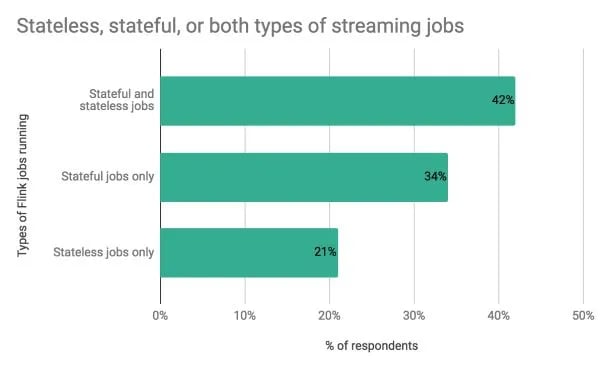
A majority of respondents are using Flink for stateful stream processing. 76 percent of respondents are running only stateful jobs or both stateful and stateless streaming jobs:
-
42 percent are running both stateful and stateless streaming jobs
-
34 percent are running stateful streaming jobs only
-
21 percent are running stateless streaming jobs only
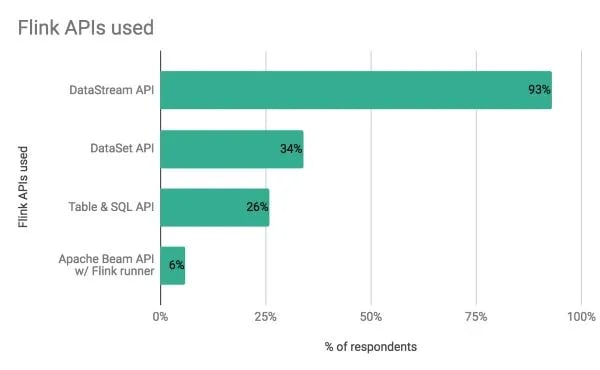
The DataStream API remains the most heavily-used among respondents, but ⅓ are using the DataSet API, too. Along with the DataStream API, other APIs are being used by a substantial portion of respondents, as well:
-
93 percent use the DataStream API
-
34 percent use the DataSet API
-
26 percent use the Table and SQL API
-
6 percent use the Apache Beam API with the Flink runner
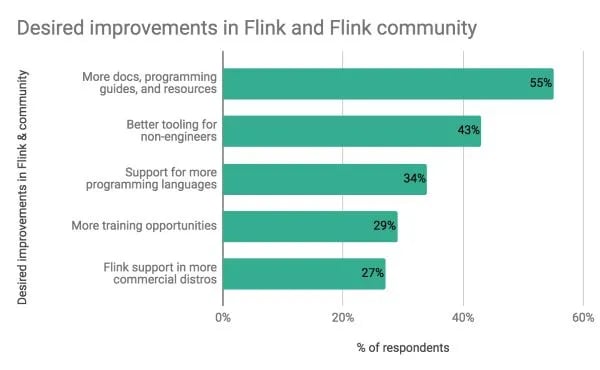
Flink users are hoping to see more documentation: 55 percent of respondents, when asked what new features or developments they’d like to see in Flink or the Flink community, cited docs, programming guides, and resources as a top priority. Other requests include:
-
43 percent for better tooling for non-engineering users
-
34 percent for support of programming languages beyond Java, Scala, and SQL
-
29 percent for more training opportunities, both online and in person
-
27 percent for support for Flink in a broader range of commercial distributions
Open-ended Feedback
In the latter half of the post, we’ll include a selection of open-ended feedback from respondents who gave us permission to share their answers anonymously. There are lots of great suggestions here, and we really appreciate the detailed ideas that respondents provided.
Many of the features and requests covered below are being worked on by the community already. If you're interested in seeing work that's already underway, we recommend the following resources.
1) The Apache Flink Jira
2) Flink Improvement Proposals (FLIPs) in the Apache Flink wiki
3) Flink dev@ Mailing List
Question: What new features or developments would you like to see in Flink and the Flink community?
“Scala 2.12 support”
“More documentation regarding state management. For example, how to avoid using the DataStream API in ways that will cause the state to grow quickly.”
“Python support and better Mesos support”
“Better support for integration with Mesos together with troubleshooting guides and best practices configuration so it works out-of-the-box, and if not, a chance to figure out why”
“Better UI dashboard”
“Monitoring UI could be improved”
“Machine learning support for training & serving more algorithms”
“Scheduled periodic savepoints”
“Watermarks per key”
“Better tooling for running in production; better instrumentation - automatic bottleneck detection and dynamic scaling based on throughput; more consistent docs”
“Side inputs!”
Are there any aspects or features of Flink that we didn't include on this list that you'd like to address?strong>
“More info about best practices and troubleshooting guides”
“Better documentation on how work with containers (Docker, K8S, Mesos)”
“Zero-downtime deploys for streaming jobs”
“Integration of support of machine learning algorithms in a streaming environment, for model serving and training, integrating external existing libraries such as Flink-JPMML.”
“I'd like to see more examples and walkthroughs of moderately-complex, real-world use cases to help learn how to compose things together.”
“Best practices and white papers around use cases from an end-to-end solution and resource management would be nice for enterprise architects.”
“The one area where we would love to see more support is around testing stateful operators.”
We welcome any final comments about any aspect of Flink.
“We have used streaming and batch processing engines before, but Flink is totally different with great stateful streaming, and we love the CEP library.”
“Best stream processing system because of event time support, late events handling, snapshotting, checkpointing, exactly-once processing, and the low-level Scala API.”
“Love the project and community, excited about the roadmap!”
“Flink is awesome! But it's hard to grasp event time operating and configure it properly in a scenario when we have to both reprocess old data and then handle online data (when we evaluate new ML models, we do that).”
“Table API is important for us, being able to have a common API for streaming and batch”
We'd like to thank all of the survey respondents for providing valuable feedback, and as mentioned above, we'll be publishing a full report with survey data in the coming weeks.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
