













Apache Flink, Ververica Platform and Alibaba Cloud's RealTime Compute technology stack processes record breaking real time data during this year's Double 11!
Wondering how Apache Flink, Ververica Platform and Alibaba Cloud's Realtime Compute for Apache Flink product powered this year Double 11? Alibaba Cloud's Reatime Compute for Apache Flink Product is a Ververica Platform-based solution for real time data processing at scale. And it was this product that managed to successfully process a peak traffic processing rate of four billion records per second during this years Global Shopping Festival! To add to this, the data volumes processed by the same technology stack during the event reached an incredible seven TB per second at peak. The volume of data processed by the Flink-based stream-batch unification has successfully withstood strict tests in terms of stability, performance, and efficiency in Alibaba's core data service scenarios. In the following sections, we discuss our experience and review the evolvement of stream and batch unification within Alibaba's core data systems.
As Double 11 ended at midnight on November 12, the Gross Merchandise Volume (GMV) of the 2020 Double 11 Global Shopping Festival reached an extraordinary US$74.1 billion. With the support of Apache Flink, the GMV figure is exhibited steadily and in real time in our monitors during the entire festival. Additionally, the Flink-based real-time computing platform of Alibaba has successfully performed real-time data processing for the Alibaba digital economy during this year's event, successfully passing the annual test.
In addition to the GMV dashboard, Flink also provided support for many other critical services. These services include real-time machine learning for search and recommendation, real-time advertisement anti-fraud, real-time tracking and feedback of Cainiao's order status, ECS real-time attack detection, and monitoring and alerting for massive infrastructures. The real-time business and data volume are increasing dramatically every year. This year, the peak rate of real-time computing reached four billion records per second, and the data volume reached an astonishing seven TB per second. This is equivalent to reading five million copies of the Xinhua Dictionary in one second.
So far, the number of Alibaba Cloud's real-time computing jobs has reached more than 35,000. The cluster size of our computations has scaled to over 1.5 million CPUs, by far the largest Apache Flink deployment worldwide. By now, Flink has supported all the real-time computing needs of the Alibaba digital economy and has provided great insights to customers, merchants, and operations staff.
In addition, for the first time during this year's Global Shopping Festival, Flink has performed unification of stream and batch processing and has successfully withstood strict tests in terms of stability, performance, and efficiency in Alibaba's core business scenarios.

Applying Stream-Batch Unification with Flink in Alibaba's Core Data Scenarios
The unification of stream and batch processing started at Alibaba a long time ago. Flink was initially used in Alibaba's real time search and recommendation scenario, in which index building and feature engineering were based on the initial version of unified stream and batch processing in Apache Flink. However, during this year's Double 11, Apache Flink further enhanced its capability of stream and batch unification to help the Alibaba data platform achieve more accurate data analysis and business decision-making by cross verifications between real time and offline data.
Alibaba offers two types of data reports: real-time reports and offline reports. The former plays an important role in the Double 11 promotion scenario. It can provide real-time information in various dimensions for merchants, operations staff, and managers. It also helps them make timely decisions to improve the efficiency of the platform and our business. Taking real-time marketing data analysis as an example, operations staff and decision-makers need to compare the results of big promotions from different periods, such as the turnover at 10:00 am during the promotion day compared with the turnover at the same time the day before. Through comparison, they can determine the current marketing effectiveness and whether it is necessary to carry out additional activities or perform any controlling mechanisms on the promotion.
In the previous scenario, two kinds of data analytics reports are required. The first is the offline data report calculated based on batch processing every night while the second is the real-time data report generated by stream processing. Through comparing and analyzing both the real-time and historical data, decisions can be made timely, securely and accurately ensuring optimal results.
Without the unification of stream and batch processing powered by Apache Flink, offline reports and real-time reports would need to be generated by separate batch and streaming engine, resulting in double development costs, increased maintenance overhead and a consistent data processing logic maintained for two separate engines, which makes it difficult to ensure data processing consistency.
Using a single engine to unify stream and batch processing for data analysis would mean that offline and real-time analytics remain naturally consistent. With a mature stream and batch unification architecture in Apache Flink and a successful deployment of this architecture in our search and recommendations use case, it was time to upgrade the real-time computing platform to support, for the first time, the core data use cases of Double 11. All with the help of Apache Flink's unified stream and batch engine.
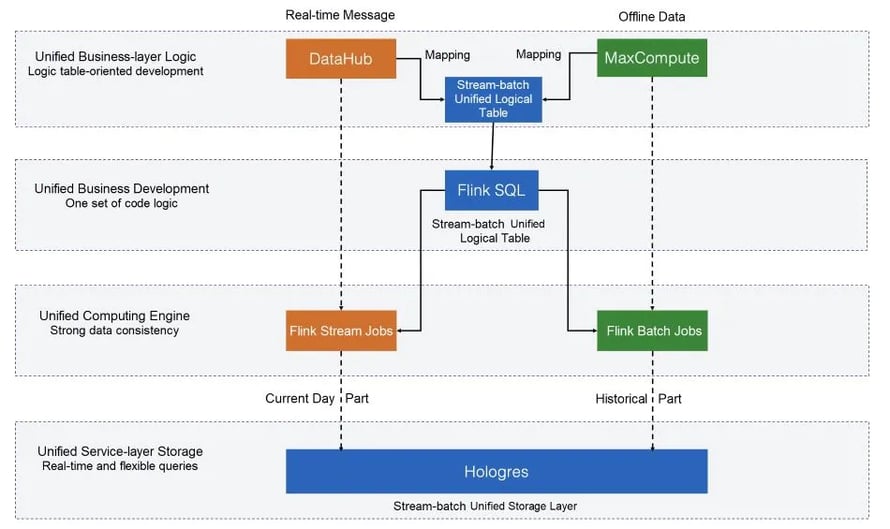
This year, the stream and batch unification computing framework, jointly developed by both the Flink and the Data Platform Team at Alibaba, made its debut during Double 11 for the company's core data use case scenarios. As a result of stream and batch unification, only one set of code was required for multiple computing processing modes, while the computing speed was twice as fast as other frameworks, and querying was four times faster. Unified batch and streaming also resulting in four to ten times increase in the speed of developing and generating data reports as well as ensuring full consistency of real-time and offline data.
In addition to the advancement in business development efficiency and computing performance, the unified stream and batch computing architecture improves our cluster resource utilization. With a rapid expansion in recent years, Alibaba's Flink real-time cluster now contains millions of CPUs, with tens of thousands of real-time computing tasks running. During the day, computing resources are occupied for real-time data processing. At night, the idle computing resources can be used for offline batch processing, for free. Both batch and stream processing use the same engine and resources, saving significantly in development, operations & management, and resource costs. During this year's Double 11, the Flink-based batch and streaming applications did not apply for any additional resources. The batch mode reused the Flink real-time computing cluster, which greatly improved the cluster utilization and saved a large amount of resource overhead. This efficient resource utilization mode also served as the basis for more subsequent business innovations.
Apache Flink Stream-Batch Unification with Great Investment and Efforts
The complete unification of Flink's stream and batch architecture was not constructed overnight. In Flink's earlier versions, stream and batch processing were neither completely unified in terms of APIs nor in terms of their Runtime. With the release of Flink 1.9, the community has accelerated the improvement and upgrade of the framework's stream-batch unification. Flink SQL, the most mainstream API for users, took the lead in achieving stream-batch unification semantics. This allows users to use only one set of SQL statements for stream and batch pipeline development, significantly reducing development costs.

However, SQL cannot meet all user requirements. For some tasks requiring a high degree of customization, such as fine-grained manipulation on state, users still need to use DataStream API. In common business scenarios, after submitting a streaming job, users will often create another batch job to replay historical data. Although DataStream can effectively meet various requirements of stream computing scenarios, its support for batch processing can be further enhanced.
Therefore since Flink 1.11, the community started focusing on the improvement of the stream and batch unification capability over Apache Flink's DataStream API by adding batch processing semantics to it. By applying the concept of batch and stream unification to the design of Connectors, Flink can connect DataStream APIs with different types of stream and batch data sources, such as Kafka and HDFS. In the future, the unified iterative APIs will be introduced into the DataStream APIs as well for machine learning scenarios.
From a functionality standpoint, Flink is still a combination of stream and batch computing, using both SQL and the DataStream APIs. The users' code is executed either in the stream mode or in the batch mode. However, some business scenarios place higher requirements on stream-batch unification with automatic switching between stream and batch computing. For example, in scenarios of data integration and data lake, a full set of data in the database needs to be synchronized to the HDFS or cloud storage services first. Then, incremental data in the database needs to be automatically synchronized. Unified stream and batch ETL processing is performed during such synchronization. Flink will support more intelligent stream-batch unification scenarios in the future.
The Development of Flink-Based Stream-Batch Unification at Alibaba
Alibaba was the first enterprise in China to choose Flink. In 2015, the Search and Recommendation Team wanted to choose a new big data computing engine to meet the challenges of the next 5 to 10 years. The new computing engine would help with processing massive items and user data in the search and recommendation backend. Considering the high requirement for short latency in the e-commerce industry, the team hoped the new computing engine would be capable of both large-scale batch processing and millisecond-level real-time processing. In other words, the engine should be a stream-batch unified engine. At that time, Spark's ecosystem had matured, and the stream-batch unification capability was provided through Spark Streaming. Flink was regarded as the top-level Apache project one year prior. After research and discussion about Spark and Flink, the team agreed that although the Flink ecosystem was not mature at that time, its stream processing-based architecture was more suitable for stream-batch unification. Therefore, the team quickly decided to build a real-time computing platform for search and recommendations based on the internal improvement and optimization of Flink within Alibaba.
After one year of hard work by the team, the real-time computing platform for search and recommendations based on Flink, successfully supported the Double 11 Global Shopping Festival in 2016. Alibaba gained an understanding of the Flink-based real-time computing engine through its practice in core business scenarios. As a result, all of Alibaba's real-time data services were migrated to the platform. After another year of hard work, Flink successfully the supported real-time data services of Alibaba during the 2017 Double 11 Global Shopping Festival, including the GMV dashboard and other core data service scenarios.
In 2018, Alibaba Cloud launched a real-time computing product based on Flink to provide cloud computing services for small and medium-sized enterprises. Not just to use Flink to solve its own business problems, Alibaba wanted to promote the development of the Flink open-source community, and make more contributions. By 2020, almost all mainstream technology companies globally have adopted Flink for real-time computing. Flink has become a de facto standard for real-time computing in the big data industry.
The Flink community continues its technology innovation. During the 2020 Double 11 Global Shopping Festival, the Flink-based stream-batch unification performed remarkably in the core marketing decision-making system of Tmall. In addition, the Apache Flink-based stream-batch unification successfully completed the stream-batch indexing and machine learning processes in search and recommendation scenarios proving the success of our decision to choose Flink a little over five years ago.
Flink Forward Asia 2020: Unveiling Technologies behind Stream-Batch Unification
This year, the Flink Forward Asia Conference will adopt live broadcasts online for developers to learn open-source big data technology for free. Many leading Internet companies worldwide, including Alibaba, Ant Group, Tencent, ByteDance, Meituan, Xiaomi, Kuaishou, Bilibili, NetEase, Weibo, Intel, DellEMC, and LinkedIn, will share their technical practices and innovation with Apache Flink.
Stream-batch unification will be a hot topic at Flink Forward Asia this year. The Head of Data Technology from Tmall will share the use case and implementation of the Flink-based stream-batch unification at Alibaba. Audiences will learn how stream-batch unification creates business value at the core scenarios of Double 11. Flink PMC and Committer experts of Alibaba and ByteDance will carry out in-depth technical talks about Apache Flink SQL and Flink's Unified Runtime. They will also share the latest technology updates of the Flink community. Among other speakers, gaming technology experts from Tencent will introduce use cases of Flink in the game "Honor of Kings." The Director of Real-Time Big Data from Meituan will explain how Flink helps life service scenarios work in real-time. The machine learning technology experts from Weibo will introduce how to use Flink for information recommendation. In addition, Flink-related topics will cover finance, banking, logistics, automobile manufacturing, travel, and many other industries, presenting a flourishing ecosystem. Enthusiastic developers that are interested in open source big data technologies are welcome to attend the FFA Conference. During this conference, they will learn more about the latest technological development and innovation in the Flink community.
Official website of the conference: https://www.flink-forward.org/
You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
