














This post is based on the talk I gave at the Strata/Hadoop World conference in San Jose, March 31 2016. You can find the slide set here, and you can also read this article at the MapR blog.

{kind=link}
Continuous counting
In this post, we focus on a, seemingly simple, extremely widespread, but surprisingly difficult (in fact, an unsolved) problem in practice: counting in streams. Essentially, we have a continuous stream of events (e.g., visits, clicks, metrics, sensor readings, tweets, etc), and we want to partition the stream by some key, and produce a rolling count over some period of time (e.g., count number of visitors in the last hour per country).
First, let us see how to solve this problem using a classic batch architecture, i.e., using tools that operate on finite data sets. In the diagram below, imagine time flowing from left to right. In a batch architecture, continuous counting consists of a continuous ingestion stage (e.g., by using Apache Flume), which produces periodic files (e.g., in HDFS). For example, if we are counting hourly we are producing a file every hour. Then, periodic batch jobs (using any kind of batch processor - e.g., MapReduce or Spark) are scheduled on these files, perhaps with the help of a scheduler (e.g., Oozie).
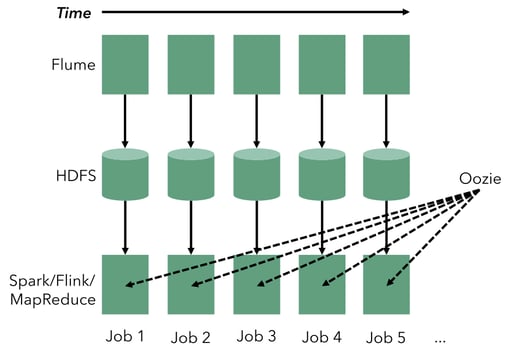
While this architecture can be made to work, it can also be very fragile, and suffers from a multitude of problems:
-
High latency: The system is based on batch processing, so there is no straightforward way to react to events with low latency (e.g., get approximate or rolling counts early).
-
Too many moving parts: We used 3 different systems to count events in our incoming data. All these come with their learning and administration costs, as well as bugs in all the different programs.
-
Implicit treatment of time: Let’s assume that we want to count every 30 minutes rather than an hour. This logic is part of the workflow scheduling (and not the application code) logic, which mixes devops concerns with business requirements. Making that change would mean changing the Flume job, the Oozie logic, and perhaps the batch processing jobs, in addition to changing the load characteristics in the YARN cluster (smaller, more frequent jobs).
-
Out of order event handling: Most real-world streams arrive out-of-order, i.e., the order that the events occur in the real world (as indicated by the timestamps attached to the events when they are produced - e.g., the time measured by the smartphone when a user logs in an application) is different from the order that the events are observed in the data center. This means that an event that belongs to the previous hourly batch is wrongly counted in the current batch. There is really no straightforward way to resolve this using this architecture - most people choose simply to ignore that this reality exists.
-
Unclear batch boundaries: The meaning of “hourly” is kind of ambiguous in this architecture as it really depends on the interaction between different systems. The hourly batches are, at best, approximate with events at the edges of batches ending up in either the current or the next batch with very little guarantees. Cutting the data stream into hourly batches is actually the simplest possible way to divide time. Assume that we would like to produce aggregates not for simple hourly batches but for sessions of activity (e.g., from login until logout or inactivity). There is no straightforward way to do this with the above architecture.
To address the first problem (high latency), the big data community (and in particular the Storm community) came up with the idea of the Lambda architecture, using a stream processor alongside a batch architecture in order to provide early results. This architecture looks as follows:
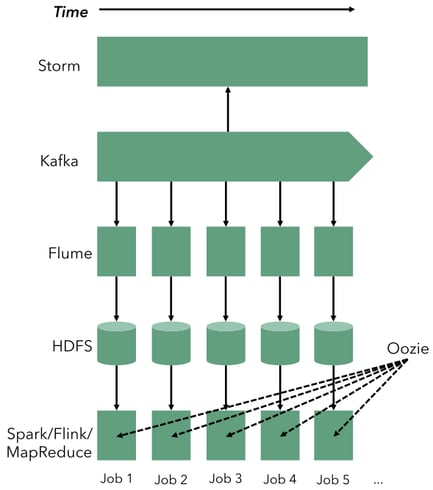
The lower part of the figure is the same batch architecture we saw before. In addition to the previous tools, we have added Kafka (for stream ingestion) and Storm to provide early approximate results. While this resolves the latency issue, the rest of the issues remain, and it introduces, in addition two more systems, as well as code duplication: the same business logic needs to be expressed in Storm and the batch processor with two very different programming APIs, introducing two different codebases to maintain with two different sets of bugs. To recap, some problems with Lambda are:
-
Too many moving parts (as before and worse)
-
Code duplication: the same application logic needs to be expressed in two different APIs (the batch processor and Storm), leading almost certainly to two different sets of bugs.
-
Implicit treatment of time (as before)
-
Out of order event handling (as before)
-
Unclear batch boundaries (as before)
An elegant and easy solution to all of these problems is a streaming architecture. There, a stream processor (in our case Flink, but can be any stream processor with a certain feature set) is used in conjunction with a message queue (e.g., Kafka) to provide the counts:
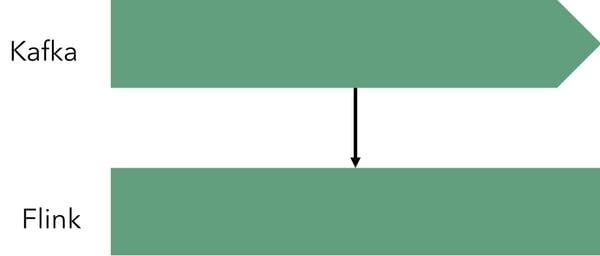
Using Flink, such an application becomes trivial. Below is a code template of a Flink program for continuous counting that does not suffer of any of the aforementioned problems:
[java] DataStream<LogEvent> stream = env .addSource(new FlinkKafkaConsumer(...)) // create stream from Kafka .keyBy("country") // group by country .timeWindow(Time.minutes(60)) // window of size 1 hour .apply(new CountPerWindowFunction()); // do operations per window [/java]
It is worth noting that a fundamental difference between the streaming and the batch approach is that the granularity of counting (here 1 hour) is part of the application code itself and not part of the overall wiring between systems. We will come back to this later in this article, but for now, the point is that changing the granularity from 1 hour to 5 minutes needs only a trivial change in the Flink program (changing the argument of the window function).
Counting hierarchy of needs
Maslow’s hierarchy of needs describes a “pyramid” of of human needs as they evolve from simple physiological needs up to self-actualization. Inspired by that (and Martin Kleppmann’s use of the same parabole in the context of data management), we will describe a hierarchy of needs for our counting use case:
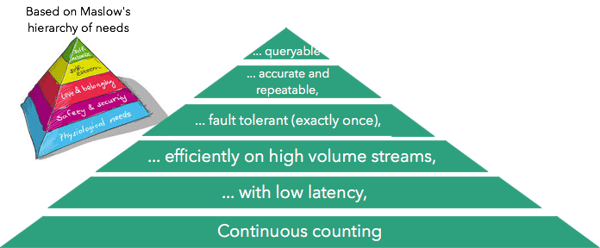
Let us go through these needs starting from the bottom:
-
Continuous counting refers to the ability to simply count continuously
-
Low latency means getting results with low (typically sub-second) latencies
-
Efficiency and scalability means using hardware resources well and scaling to large input volumes (typically millions of events per second)
-
Fault tolerance refers to the ability of completing the computation correctly under failures
-
Accuracy and repeatability refers to the ability to be able to provide deterministic results repeatably
-
Ability to query refers to the ability to query the counts inside the stream processor
Now, let us climb through this hierarchy of needs and see how we can satisfy them using the current state of the art in open source. We already established that a streaming architecture (and thus a stream processing system) is necessary to do continuous counting, so we will disregard batch processing systems and focus on stream processors. We will consider the most popular open source systems: Spark Streaming, Storm, Samza, and Flink, all of which can count continuously. The following sequence shows how certain stream processors are eliminated at every step in the pyramid:




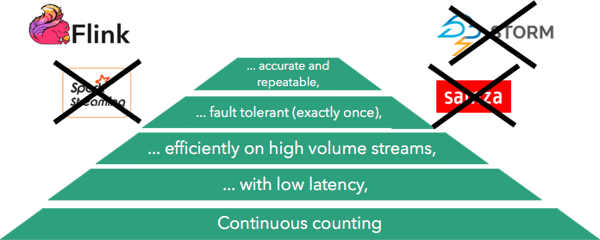
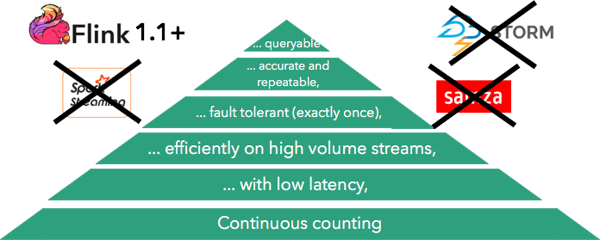
Going up in the pyramid, we see how more sophisticated needs for counting eliminate the ability to use certain streaming frameworks. The need for low latency eliminates Spark Streaming (due to its micro-batching architecture). The need for efficiently handling streams of very high volume eliminates Storm. The need to provide strict fault tolerance guarantees (exactly once) eliminate Samza (and Storm), and the need to provide accurate and repeatable results eliminate all frameworks besides Flink. The final need, querying the results inside the stream processor without exporting them to an external database is not satisfied by any of the stream processors right now (including Flink), but this is an upcoming feature in Flink.
Next, we will go into all of these stages in detail, and see how certain frameworks are eliminated at every stage.
Latency
To measure the latency of stream processors, the Storm team at Yahoo! published last December a blog post and a benchmark comparing Apache Storm, Apache Spark, and Apache Flink™. This was a very important step for the space, as it was the first streaming benchmark modeled after a real-world use case at Yahoo!. In fact, the benchmark task was essentially counting, the use case that we have focused on in this blog post as well. In particular, the job does the following (from the original blog post):
“The benchmark is a simple advertisement application. There are a number of advertising campaigns, and a number of advertisements for each campaign. The job of the benchmark is to read various JSON events from Kafka, identify the relevant events, and store a windowed count of relevant events per campaign into Redis. These steps attempt to probe some common operations performed on data streams.”
The results obtained by the Yahoo! Team showed that “Storm 0.10.0, 0.11.0-SNAPSHOT and Flink 0.10.1 show sub- second latencies at relatively high throughputs with Storm having the lowest 99th percentile latency. Spark streaming 1.5.1 supports high throughputs, but at a relatively higher latency.”, as shown at the diagram below:
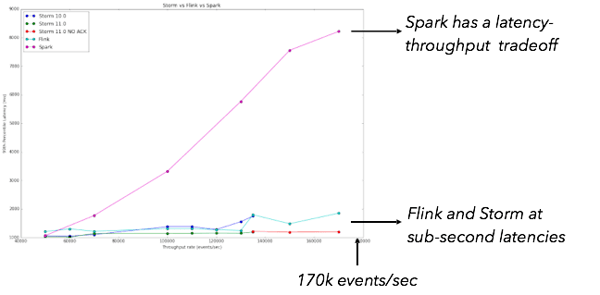
Essentially, when using Spark Streaming, there is a latency-throughput tradeoff, whereas both Storm and Flink do not show such a tradeoff.
Efficiency and scalability
While the Yahoo! benchmark was an excellent starting point in comparing the performance of stream processors, it was limited in two dimensions:
-
The benchmark stopped at very low throughputs (170,000 events per second aggregate)
-
All jobs in the benchmark (for Storm, Spark, and Flink) were not fault tolerant.
Knowing that Flink can achieve much higher throughputs, we decided to extend the benchmark as follows:
-
We re-implemented the Flink job to use Flink’s native window mechanism so that it provides exactly-once guarantees (the Flink job in the original Yahoo! benchmark was not making use of Flink’s native state, but was rather modeled after the Storm job).
-
We tried to push the throughput further by re-implementing the data generator to pump out events faster.
-
We focused on Flink and Storm as these were the only frameworks that could provide acceptable latency in the original benchmark.
Using a similar cluster (same number of machines but faster interconnect) as the original benchmark, we got the following results:
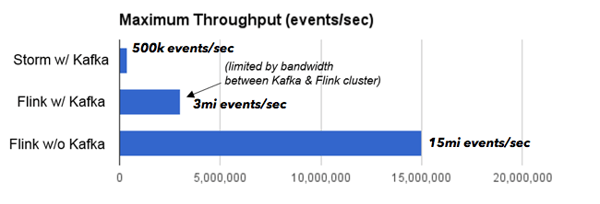
We managed to scale Storm to a higher throughput (0.5 million events per second) than the original benchmark due to the faster interconnect. Flink at the same setting scaled to 3 million events per second. The Storm job was bottlenecked on CPU, while the Flink job was bottlenecked on the network bandwidth between the machines running Kafka and the machines running Flink. To eliminate that bottleneck (which had nothing to do with Kafka, but was just the available cluster setup), we moved the data generator inside the Flink cluster. In that setting, Flink could scale to 15 million events per second.
While it may be possible to scale Storm to higher volumes using more machines, it is worth noting that efficiency (using the hardware efficiently) is as important as scalability, especially when the hardware budget is limited.
Fault tolerance and repeatability
When talking about fault tolerance, the following terms are often used:
-
At least once: this means, in our counting example, that over-counting after failures is possible
-
Exactly once: this means that counts are the same with or without failures
-
End to end exactly once: this means that counts published to an external sink will be the same with or without failures.
Flink guarantees exactly once with selected sources (e.g., Kafka), and end to end exactly once for selected sources and sinks (e.g., Kafka → Flink → HDFS with more coming up). The only frameworks from the ones examined in this post that guarantee exactly-once are Flink and Spark.
Equally important to tolerating failures is supporting operational needs for deploying applications in production and making those repeatable. Flink internally provides fault tolerance via a mechanism called checkpoints, essentially taking a consistent snapshot of the computation periodically without ever stopping the computation. Recently, we introduced a feature called savepoints, which essentially makes this checkpointing mechanism available directly to the user. Savepoints are Flink checkpoints that are triggered externally by the user, are durable, and never expire. Savepoints make it possible to “version” applications by taking consistent snapshots of the state at well-defined time points, and then rerunning the application (or a different version of the application code from that time point). In practice, savepoints are essential for production use, enabling easy debugging, code upgrades (being that the application or Flink itself), what-if simulations, and A/B testing. You can read more about savepoints here.
Explicit handling of time
In addition to be able to replay a streaming application from a well-defined point in time, repeatability in stream processing requires support for what is called event time. An easy way to explain event time is the Star Wars series: the time in the movies themselves (when the events happened) is called event time, whereas the time that the movies came out in the theaters is called processing time:
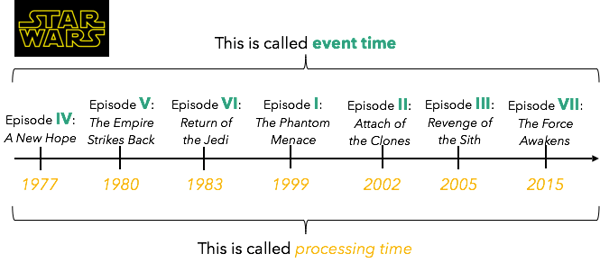
In the context of stream processing, event time is measured by the timestamps embedded in the records themselves, whereas the time measured by the machines that execute the computation (when we see the records) is called processing time. The stream is out of order when the event time order is not the same as the processing time order (like the Star Wars series).
Event time support is essential in many settings, including providing correct results in out of order streams, and providing consistent results when replaying the computation (e.g., in a time travel scenario as we saw before). In short, event time support makes the computation repeatable and deterministic, as the results do not depend on the time of the day that the computation is run.
Of all the frameworks examined in this post, only Flink supports event time (with others building up partial support right now).
Queryable state and what’s coming up in Flink
The tip of the hierarchy pyramid was the ability to query the counts in the stream processor. The motivation for this functionality is the following: we saw that Flink can support a very high throughput in counting and related applications. However, these counts need to presented somehow to the external world, i.e., we need the ability to ask at real time the value of a specific counter. The typical way to do that is to export the counts into a database or key-value store and query them there. However, this may become the bottleneck of the processing pipeline. Since Flink holds these counts already in its internal state, why not query these counts directly in Flink? This is possible right now using a custom Flink operator (see Jamie Grier’s stateful stream processing at in-memory speed), but not supported natively. We are working on bringing this functionality natively into Flink.
A few other features that we are actively working on are:
-
SQL on Flink for both static data sets and data streams using Apache Calcite
-
Dynamic scaling of Flink programs: this gives the ability to the user to adjust the parallelism of a Flink program while it is running
-
Support for Apache Mesos
-
More streaming sources and sinks (e.g., Amazon Kinesis and Apache Cassandra)
Closing
We saw that even seemingly simple streaming use cases (counting), have more “depth” when performance and production use are involved. Based on a “hierarchy of needs”, we saw how Flink has a unique combination of features and performance in the open source space to support these use cases well in practice.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
