














Today, we’re excited to announce that dA Platform, a production-ready stream processing infrastructure with open-source Apache Flink®, is generally available!
We first unveiled dA Platform at Flink Forward Berlin 2017, and during the past few months, we’ve been running an early access program during which large-scale enterprises have been testing the product and providing us with feedback. And now we’re ready to share it with everyone else.
How can I get started with dA Platform?
A dA Platform trial sandbox VM is available at data-artisans.com/download. This is the easiest way to get started--we’ve taken care of the deployment environment and pre-deployed the platform so that you can be up and running in a matter of minutes.

Already have access to a Kubernetes cluster and want to run the real thing? On our download page, we also offer a dA Platform trial that you can deploy on your own Kubernetes infrastructure. First, be sure to read the Kubernetes Trial Getting Started Guide in our documentation.
Want to learn more about dA Platform? You can...
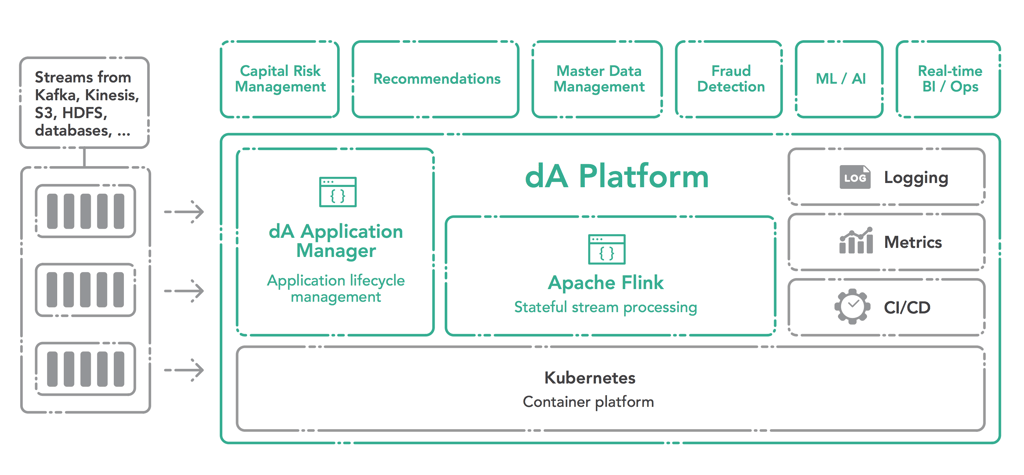
Why provide a complete stream processing infrastructure with Apache Flink®?
The mission behind dA Platform is the same now as it was when we first announced the product:
Today’s business reality is dominated by data–data that is produced continuously in the form of data streams.
We believe that the only way for enterprises to gain a meaningful business advantage from this data is through an architecture where services run continuously and can react immediately to important events. Gone are the days of waiting for hours for a computation to finish while competitors are already taking advantage of insights derived from their real-time data.
Building Apache Flink applications to model complex business logic has become relatively easy, as Flink’s APIs have evolved significantly since the project’s inception. But as we’ve mentioned before, we know that there’s still much work to be done to make stateful stream processing applications as easy as possible for anyone to deploy and manage.
Working closely with a wide variety of Flink production users has convinced us that operationalizing and supporting 24/7 stateful stream processing applications is a process that can be made easier. We have distilled that experience into a platform that addresses the shortcomings of existing operations technologies, which are generally designed for stateless applications, and builds a powerful foundation for stateful real-time applications.
Get In Touch
Want to speak with someone on our team? Just fill at the form at the bottom of the download page, and we’ll follow up with you as quickly as possible.
We look forward to your feedback!

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
