














Today, we are delighted to see Dataflow publicly proposed as an Apache Incubator project with an initial project team from Google, data Artisans, Cloudera, and others. data Artisans is the second biggest contributing organization after Google with a total of 4 proposed initial committers.
Dataflow stems from the Google’s growing internal needs for a better programming model and runtime engine for data intensive applications. While Google originally developed MapReduce (which was the blueprint for Apache Hadoop), they very quickly saw the need for high-volume stream processing, as well as the need for integrating stream and batch processing. Dataflow is the successor to many internal Google projects, including MapReduce, FlumeJava, and MillWheel.
One difference between Dataflow and earlier Google systems is that it is actually available to the public, not only to Google engineers. The Dataflow SDK is open source (Apache 2.0 License). Programs written in this SDK can run locally, at Google Compute Engine using Google’s proprietary cloud service, or one of the currently available open source runners, namely Apache Flink™ and Apache Spark. The SDK together with these runners constitute the code that is proposed to become an incubating project.
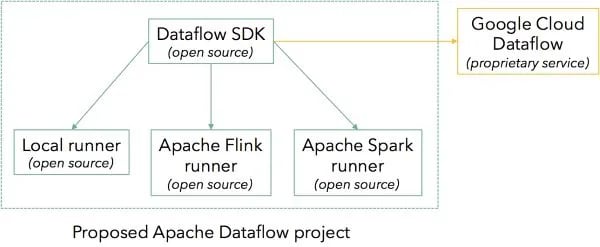
The streaming models of both Flink and Dataflow are based on the Dataflow model, with very similar features such as support for event time and out of order streams, a mechanism to define custom windows based on window assigners and triggers. These features distinguish Flink and Dataflow from older-generation streaming systems. The Dataflow Flink runner allows users to execute both batch and streaming Dataflow programs on an open source engine using alternative cloud providers to Google, or even on premise. The runner also supports all Flink data sources (e.g., Apache Kafka), enabling a better integration of the Dataflow model with the open source ecosystem.>
At data Artisans, we are the primary developers of the Dataflow Flink runner, and have already contributed to the Dataflow SDK. We are looking forward to continue driving this effort forward as committers of the proposed Apache project, if accepted for incubation. Most importantly, we share a common vision with the creators of Dataflow: we believe that the future of writing data applications is a streaming programming model, and Flink and Google Cloud Dataflow are the best embodiments of this model right now, one as an open source Apache project, and the other as a Google-hosted cloud service.>
By bringing Dataflow and the Flink Dataflow runner to the Apache family, this relationship will be further strengthened and accelerated. We believe that evolution within the Apache ecosystem will bring Flink and Dataflow further together, leading eventually to a unified programming model for both batch and stream data processing applications. We are looking forward to continue working with Google, the Flink community, and the future Dataflow community to help companies realize their data infrastructure based on modern streaming technology.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
