













The Flink Forward event gave me an amazing opportunity to present to the global Apache Flink community how Weibo uses Apache Flink and Ververica Platform on Alibaba Cloud (Real Time Compute) to run real time data processing and Machine Learning on our platform. In the following sections, I will introduce you to Weibo and I will describe the architecture of our Machine Learning platform and how we use Apache Flink to develop our real-time Machine Learning pipelines. I will finally explain how we plan to extend Flink’s usage at Weibo and give a glimpse into the experience we had with the open source technology in our organization.

What is Weibo
Weibo (新浪微博) is the largest and most popular social media networking platform in China. The website is a microblogging platform (similar to Twitter or Reddit) with functionality including messaging, private messaging, commenting on articles, reposts as well as video and picture recommendations based on context consumption and interest. In 2019, Weibo had more than 220 million daily active users (DAUs) while the monthly active users reached 516 million in the same year. Based on people's social activity — such as consuming, posting and sharing news and updates all over the world — the team at Weibo developed a social network that connects users and maps content to people based on their activities and interest.
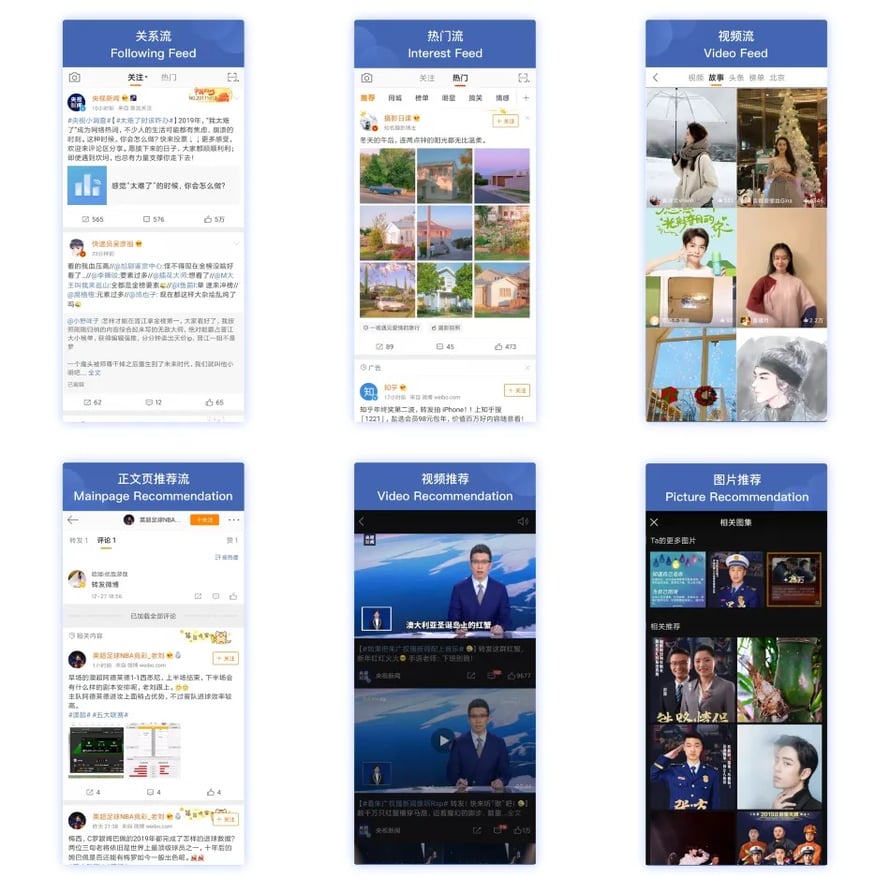 Figure 1: Weibo Functionality: Following Feed, Video Feed, Video Recommendation, Picture Recommendation and more
Figure 1: Weibo Functionality: Following Feed, Video Feed, Video Recommendation, Picture Recommendation and more
Weibo’s Machine Learning Platform (WML)
As illustrated in Figure 2 below, Weibo’s Machine Learning Platform (WML) consists of a multi-layered architecture from cluster and resource management all the way to model and inference training components. At the core of the platform, our cluster deployments, consisting of online, offline and high-performance computing clusters, run our applications and pipelines.
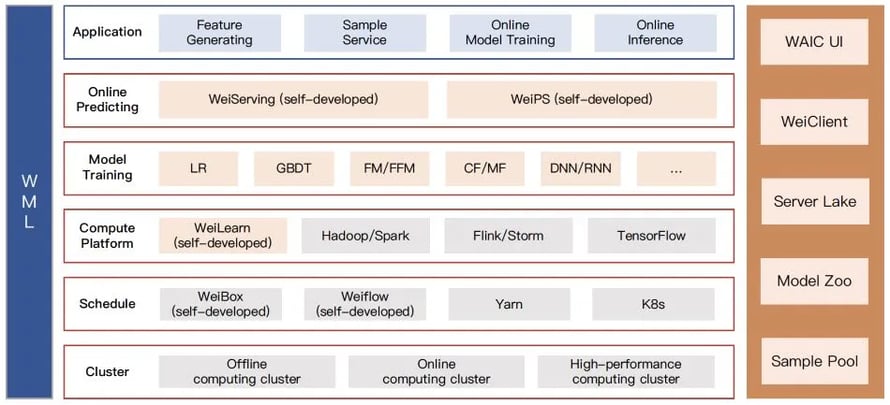 Figure 2: Weibo’s Machine Learning Platform architecture
Figure 2: Weibo’s Machine Learning Platform architecture
On top of the cluster layer comes the scheduling layer of our platform that consists of two internally-developed frameworks (WeiBox and WeiFlow) for submitting jobs to different clusters in a unified manner. We additionally utilize Yarn and Kubernetes for resource management. The third layer of our Machine Learning Platform contains the computing layer, that comes with our internally-developed WeiLearn framework (explained in further detail in the following sections of this post) that allows users of our platform to define their own algorithms and construct their own UDFs along with multiple integrated data processing frameworks, such as Hadoop, Flink, Storm and TensorFlow. The model training and online predicting layers of our architecture sit at the very top and deliver different application scenarios for our company including feature generation, sample generation, online model training and online inference, among others.
To dive a bit deeper into how Machine Learning is executed at Weibo, let us introduce two of our own, internally-developed frameworks used for Machine Learning at Weibo: WeiLearn and WeiFlow. WeiLearn — illustrated on the left side of Figure 3 below — was established at Weibo as a framework for our developers to write and plug in their own UDFs with three main steps: Input, Process and Output for our offline data processing jobs and Source, Process and Sink for our real time data processing jobs. WeiFlow, on the other hand, is a tool for handling task dependencies and scheduling, with Cron expressions, such as rerunning from specific tasks or backfilling multiple days of data in a specific time period.
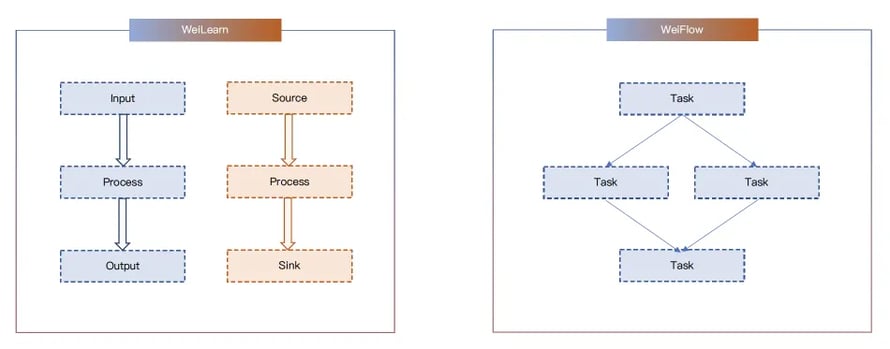 Figure 3: Weibo’s WeiLearn and WeiFlow frameworks
Figure 3: Weibo’s WeiLearn and WeiFlow frameworks
After a few successful iterations, the Machine Learning Platform at Weibo now supports more than 100 billion parameters in our model training and over 1 million queries per second (QPS), while we managed to reduce our iteration cycle down to 10 minutes from a weekly cadence in the earlier iterations of the platform.
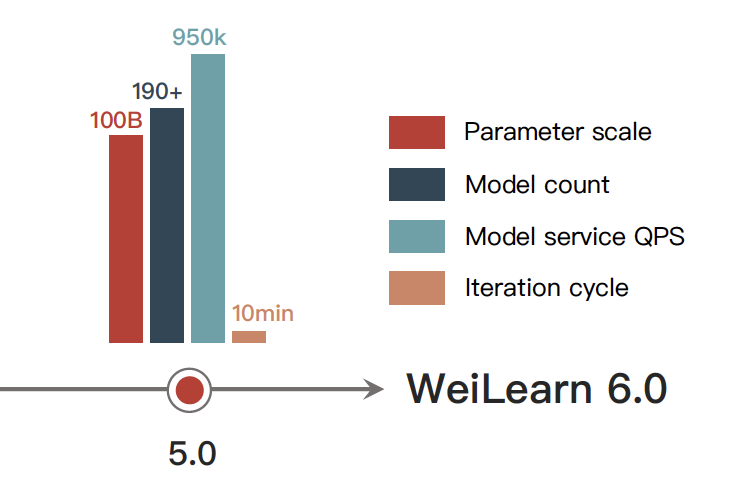 Figure 4: Performance of WeiLearn 6.0 - Included in WML Platform
Figure 4: Performance of WeiLearn 6.0 - Included in WML Platform
For more information on how Ververica Platform and Apache Flink have been a great enabler for Weibo's efforts to unify our batch and stream processing jobs and how the framework has extended to hundreds of instances and handled petabytes of data being for Weibo's machine learning pipelines, you can download the the case study below.

You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
