













During Flink Forward Global 2020 the team from Razorpay showcased how Apache Flink is being utilized in it’s ‘Mitra’ Data Platform as a way to overcome challenges around feature generation and machine learning model serving in real time. ‘Mitra’ is a data platform that powers the Thirdwatch product for preventing frauds in real-time by serving machine learning models at scale. In the following paragraphs, I will explain our approach to delivering machine learning models and explain why we use Flink as the stream processing engine to perform such tasks.
About Razorpay
Razorpay is one of the leading payments solutions in India that allows businesses to accept, process and disburse payments with its product suite. The technology provides access to all payment modes including credit card, debit card, netbanking, UPI and many popular wallets. With more than 5 million merchants, annualized payment volume of $25 billion and over 100 parameters for each transaction, the company processes a significant amount of data on a daily basis.
In 2019, Razorpay made its first acquisition - Thirdwatch, an AI-powered solution that helps businesses process transactions and detect fraud in real-time. Let’s look at how Razorpay and Thirdwatch leveraged Apache Flink to optimize Mitra.
Why choose Apache Flink
We chose Apache Flink as the core stream processing engine of the Mitra Data Platform because of multiple reasons. First and foremost, Apache Flink is a true, low-latency stream processing framework resulting in actual real time processing of events, with no delay. Additionally Flink’s in-memory state management, CEP (Complex Event Processing) library and support for event time processing help us bring additional logic to our computations, such as applying prediction models, sequencing our events in different ways, handling out-of-orderness and ensuring accurate and reliable event processing in real time. Flink’s Async IO is also heavily utilized in our platform, because for many operators we need to query external services like graph databases or other external systems. Finally, Flink’s checkpointing mechanism and the new enhancements in Flink’s schema evolution and State TTL features were some decisive reasons for making Flink a core part of how we perform our computations.
Data Science at Razorpay
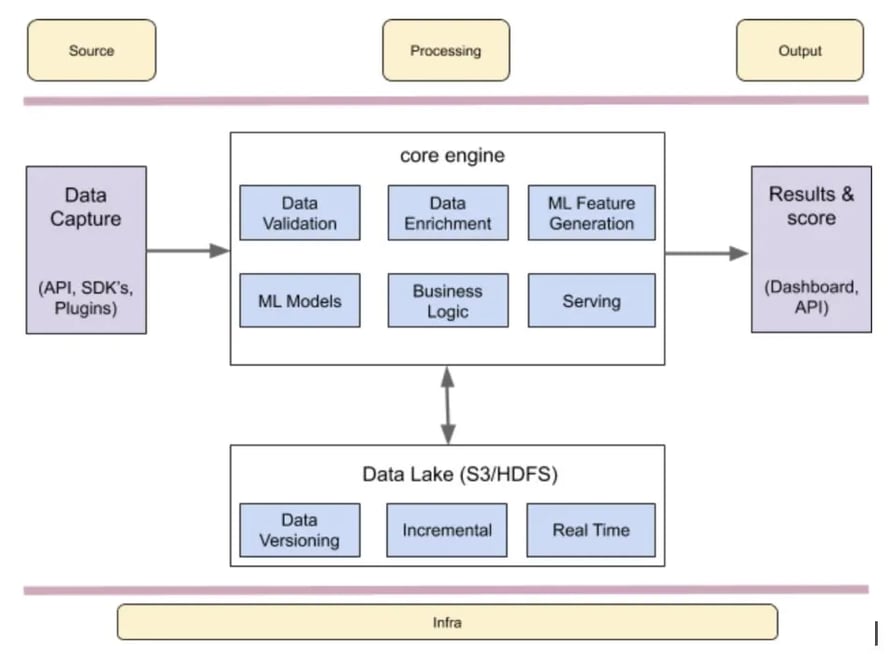
Because of the amount of data generated and the scale of our technology, the Data Science team at Razorpay is faced with multiple challenges around data science, machine learning and real time processing. To overcome these challenges the team developed an internal data intelligence platform called Mitra. Mitra’s architecture incorporates three main components that handle the workloads in a near real time fashion. The Customer Input Data component of the platform gathers data using different APIs, SDKs or Plugins before this data is parsed to the Core Engine part of our platform that includes multiple components such as Apache Flink and performs multiple functions like data augmentation, data validation, ML feature generation, identity clustering, velocity profiling and more. The core processing part of our infrastructure also includes a data lake with Presto and Hive where our analysts can perform multiple queries. Once the real time processing is executed by our Flink application we move the data to the Output part of our system that incorporates analytics dashboards, APIs and Kafka topics or other downstream operators.
Some of the key features of the Mitra data platform include:
- Predicting results within 200 milliseconds in a distributed environment
- Generating hundreds of features on the fly using 60+ operators
- Serving results from multiple deployed machine learning models
- Applying dynamic rules directly on Apache Flink data streams
- Heavily utilizing Flink’s in-memory state management for storing features and data
- Using the Flink CEP for asynchronous event handling
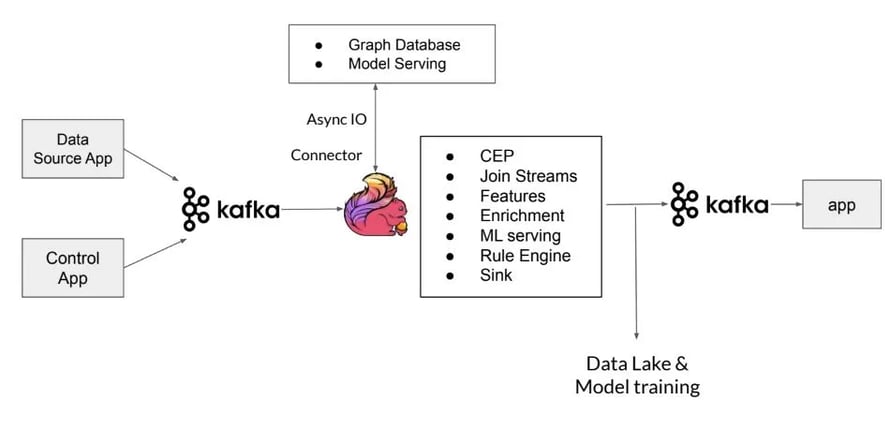
Taking a closer look at our Core Engine and main Flink application, illustrated in the diagram below, we see that there are two data streams as Kafka sources; the data source stream and the control stream. The data source stream sends all data from SDK’s to our Flink application while the control stream includes all control signals, models and rules for our computations. Once the event streams are consumed by Kafka they are then ingested toin the Flink application that incorporates anywhere between eight to ten CEP conditions for different scenarios like successful order, account creation, etc. and then performs different joins, enrichments, operations to generate 100’s of machine learning features in real time for model serving and training. Part of our Core Engine is also the Rule Engine component of our application that applies the business logic to our computations in real time.
Our core engine has more than 60 different types of stateful operators which generate features, apply rules, enrich the data streams and serve the models. After applying the rules and serving the models in real-time, the Flink application pushes the results to the Kafka stream and our ElasticSearch database so that other applications can then consume the results from Kafka.
Machine Learning Model Training and Deployment at scale
Since our system needs to predict results in milliseconds by generating hundreds of features on the fly, two factors become of utmost importance: Scalability and low-latency. While scaling dynamic feature generation and predictions from our machine learning models works well in our Flink application, scaling the model serving part becomes a challenge since the model server needs to scale too in order to handle the data loads with low-latency. In order to achieve this, we we separated our training and serving servers to achieve the optimal:
-
Resource Allocation: During model training we allocate the maximum number of resources and because of that the serving requests suffer and start failing.
-
Network Load: Similarly, during model training we pass features in bulk so the application increases the consumption of the network and starts impacting the serving requests.
-
Separate scalability: After separation, we can scale the training and serving cluster according to load and requirements.
While we have already built significant functionality in Mitra, we have more plans to further enhance the platform’s functionality and scalability in the future. We look forward to continuing working with Apache Flink and leveraging new functionality and improvements implemented by the community to tackle some of the exciting challenges around big data and machine learning at scale. If you are interested in finding out more about our technology, please check our detailed write up on our use of Flink on the Razorpay blog or check the recording of our Flink Forward video.


You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
