













Flink SQL has emerged as the de facto standard for low-code data analytics. It has managed to unify batch and stream processing while simultaneously staying true to the SQL standard. In addition, it provides a rich set of advanced features for real-time use cases. In a nutshell, Flink SQL provides the best of both worlds: it gives you the ability to process streaming data using SQL, but it also supports batch processing.
Ververica Platform makes Flink SQL even more accessible and efficiently scalable across teams. The platform comes with additional tools for developing SQL scripts, managing user-defined functions (UDFs), catalogs and connectors, as well as operating the resulting long-running queries.
Since Flink SQL stayed true to the ANSI-SQL 2011 standard, all features from compliant databases should work. This includes inner and outer joins, and all the other join types that are described in the SQL standard. In this three-part series of blog posts, we will show you different types of joins in Flink SQL and how you can use them to process data in a variety of ways. This post will focus on regular joins, interval joins, and lookup joins.
We have seen that there are many use cases for Flink SQL, and we are excited to see what you will build with it.
Make sure to check out our previous articles on Flink SQL: Flink SQL: Window Top-N and Continuous Top-N
Regular Joins
The four types of joins commonly used in SQL are: INNER and [FULL|LEFT|RIGHT] OUTER.
- INNER JOIN: Returns all rows from both tables where the key columns match
- LEFT JOIN: Returns all rows from the left table, and the matching rows from the right table
- RIGHT JOIN: Returns all rows from the right table, and the matching rows from the left table
- FULL JOIN: Returns all rows from both tables, whether the key columns match or not
Joins are used in SQL to combine data from two or more tables. When you use a join, you specify the columns from each table that you want to use to create the new table.
You can also use joins to create a single table that contains data from multiple tables. For example, if you had a table that contained information on customers and another table that contained information on orders, you could use a join to create a single table that contained both customer information and order information.
How to use Flink SQL to write Regular Joins
This example will show how you can use joins to correlate rows across multiple tables.
Flink SQL supports complex and flexible join operations over continuous tables. There are several different types of joins to account for the wide variety of semantics that queries may require.
Regular joins are the most generic and flexible types of join. These include the standard INNER and [FULL|LEFT|RIGHT] OUTER joins that are available in most modern databases.
Suppose we have a NOC list of secret agents all over the world. Your mission if you choose to accept it, is to join this table with another containing the agents’ real name.
In Flink SQL, this can be achieved using a simple INNER JOIN. Flink will join the tables using an equi-join predicate on the agent_id and output a new row every time there is a match.
However, there is something to be careful of. Flink must retain every input row as part of the join to potentially join it with the other table in the future. This means the queries’ resource requirements will grow indefinitely and will eventually fail. While this type of join is useful in some scenarios, other joins are more powerful in a streaming context and significantly more space-efficient.
In this example (which uses flink-faker to generate record values based on defined expressions), both tables are bounded to remain space efficient.
CREATE TABLE NOC (
agent_id STRING,
codename STRING
)
WITH (
'connector' = 'faker',
'fields.agent_id.expression' = '#{regexify ''(1|2|3|4|5){1}''}',
'fields.codename.expression' = '#{superhero.name}',
'number-of-rows' = '10'
);
CREATE TABLE RealNames (
agent_id STRING,
name STRING
)
WITH (
'connector' = 'faker',
'fields.agent_id.expression' = '#{regexify ''(1|2|3|4|5){1}''}',
'fields.name.expression' = '#{Name.full_name}',
'number-of-rows' = '10'
);
SELECT
name,
codename
FROM NOC
INNER JOIN RealNames ON NOC.agent_id = RealNames.agent_id;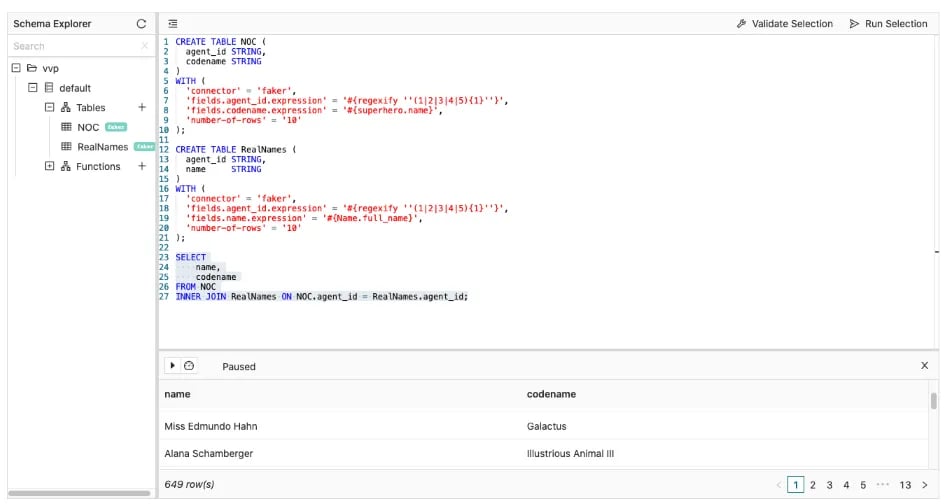
Interval Joins
Interval joins in Flink SQL are joins that are performed on two sets of data, where each set is divided into intervals. The intervals are defined by a start and end time, and the data in each set is assigned to an interval based on its timestamp. Interval joins are used to compare data in two sets that are separated by a certain amount of time.
For example, consider two sets of data, one for sales data and one for customer data. The sales data set is divided into intervals of one hour, and the customer data stream is divided into intervals of one day. Interval joins can be used to join the sales data for each hour with the customer data for the corresponding day.
How to use Flink SQL to write Interval Joins
This example will show how you can perform joins between tables with events that are related in a temporal context.
In the above-mentioned example, you learned about using regular joins in Flink SQL. This kind of join works well for some scenarios, but for others a more efficient type of join is required to keep resource utilization from growing indefinitely.
One of the ways to optimize joining operations in Flink SQL is to use interval joins. An interval join is defined by a join predicate that checks if the time attributes of the input events are within certain time constraints, i.e. a time window.
Suppose you want to join events of two tables that correlate to each other in the order fulfillment lifecycle (orders and shipments) and that are under a Service-level Agreement (SLA) of 3 days. To reduce the amount of input rows Flink has to retain and optimize the join operation, you can define a time constraint in the WHERE clause to bound the time on both sides to that specific interval using a BETWEEN predicate.
In the query below, the source tables (orders and shipments) are backed by the built-in datagen connector, which continuously generates rows in memory.
CREATE TABLE orders (
id INT,
order_time AS TIMESTAMPADD(DAY, CAST(FLOOR(RAND()*(1-5+1)+5)*(-1) AS INT), CURRENT_TIMESTAMP)
)
WITH (
'connector' = 'datagen',
'rows-per-second'='10',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='1000'
);
CREATE TABLE shipments (
id INT,
order_id INT,
shipment_time AS TIMESTAMPADD(DAY, CAST(FLOOR(RAND()*(1-5+1)) AS INT), CURRENT_TIMESTAMP)
)
WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.id.kind'='random',
'fields.id.min'='0',
'fields.order_id.kind'='sequence',
'fields.order_id.start'='1',
'fields.order_id.end'='1000'
);
SELECT
o.id AS order_id,
o.order_time,
s.shipment_time,
TIMESTAMPDIFF(DAY,o.order_time,s.shipment_time) AS day_diff
FROM orders o
JOIN shipments s ON o.id = s.order_id
WHERE
o.order_time BETWEEN s.shipment_time - INTERVAL '3' DAY AND s.shipment_time;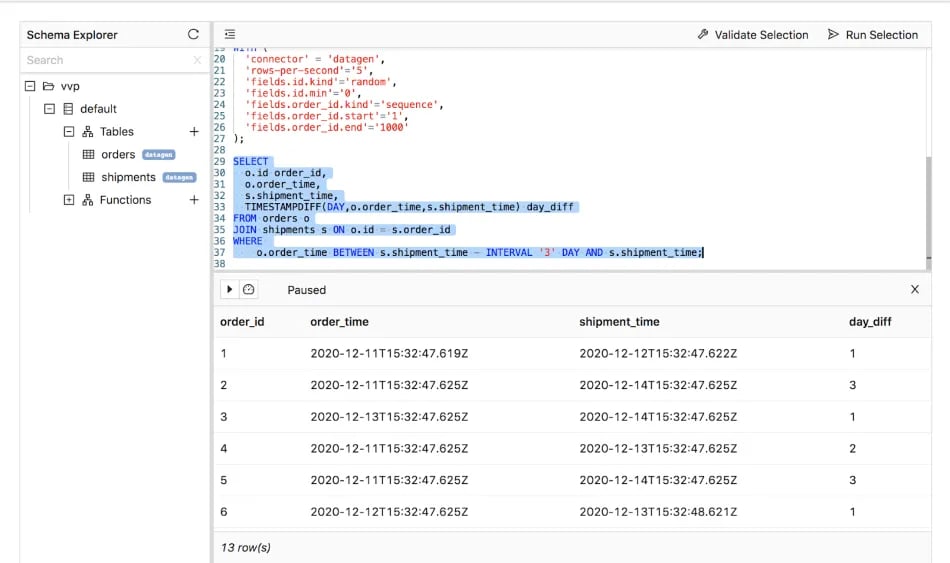
Lookup Joins
In Flink SQL, lookup joins are used to join two data sets on a common key. The first set is joined with a static table, and the second set is joined with a dynamic table.
For example, consider two sets of data, one for sales data and one for customer data. The sales data set contains a customer ID column, which can be used to join with the customer data set. The customer data set is defined as a lookup table, meaning that it is static and does not change over time. The sales data is then joined with the customer data set on the customer ID column.
How to use Flink SQL to write Lookup Joins
This example will show how you can enrich a stream with an external table of reference data (i.e. a lookup table)
Not all data changes frequently, even when working in real-time: in some cases, you might need to enrich streaming data with static — or reference — data that is stored externally. For example, user metadata may be stored in a relational database that Flink needs to join against directly. Flink SQL allows you to look up reference data and join it with a stream using a lookup join. The join requires one table to have a processing time attribute and the other table to be backed by a lookup source connector, like the JDBC connector.
In this example, you will look up reference user data stored in MySQL to flag subscription events for users that are minors (age < 18). The FOR SYSTEM_TIME AS OF clause uses the processing time attribute to ensure that each row of the subscriptions table is joined with the users rows that match the join predicate at the point in time when the subscriptions row is processed by the join operator. The lookup join also requires an equality join predicate based on the PRIMARY KEY of the lookup table (usub.user_id = u.user_id). Here, the source does not have to read the entire table and can lazily fetch individual values from the external table when necessary.
In the script below, the source table (subscriptions) is backed by the faker connector, which continuously generates rows in memory based on Java Faker expressions. The users table is backed by an existing MySQL reference table using the JDBC connector
CREATE TABLE subscriptions (
id STRING,
user_id INT,
type STRING,
start_date TIMESTAMP(3),
end_date TIMESTAMP(3),
payment_expiration TIMESTAMP(3),
proc_time AS PROCTIME()
) WITH (
'connector' = 'faker',
'fields.id.expression' = '#{Internet.uuid}',
'fields.user_id.expression' = '#{number.numberBetween ''1'',''50''}',
'fields.type.expression'= '#{regexify ''(basic|premium|platinum){1}''}',
'fields.start_date.expression' = '#{date.past ''30'',''DAYS''}',
'fields.end_date.expression' = '#{date.future ''365'',''DAYS''}',
'fields.payment_expiration.expression' = '#{date.future ''365'',''DAYS''}'
);
CREATE TABLE users (
user_id INT PRIMARY KEY,
user_name VARCHAR(255) NOT NULL,
age INT NOT NULL
)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mysql-database',
'table-name' = 'users',
'username' = 'mysql-user',
'password' = 'mysql-password'
);
SELECT
id AS subscription_id,
type AS subscription_type,
age AS user_age,
CASE
WHEN age < 18 THEN 1
ELSE 0
END AS is_minor
FROM subscriptions usub
JOIN users FOR SYSTEM_TIME AS OF usub.proc_time AS u
ON usub.user_id = u.user_id;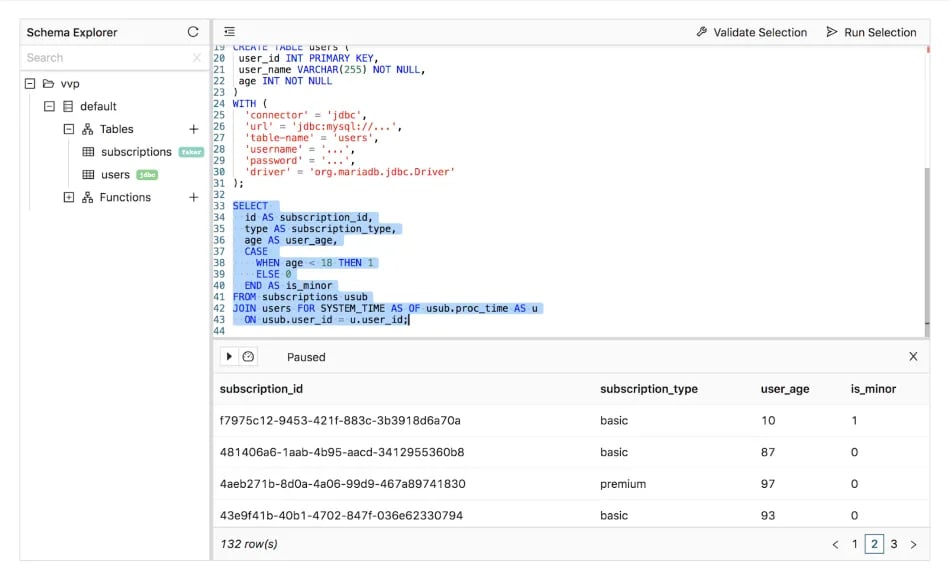
Summary
In this article, you learned about Regular, Interval, and Lookup Joins. You also saw how to use Flink SQL to write queries with them.
We encourage you to run these examples on Ververica Platform. You can follow these simple steps to install the platform.
To learn more about Flink SQL, check out the following resources:
You may also like

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure

Data Sovereignty Is Existential Most Platforms Treat It Like a Feature
