













Figuring out how to manage and model temporal data for effective point-in-time analysis was a longstanding battle, dating as far back as the early 80’s, that culminated with the introduction of temporal tables in the SQL standard in 2011. Up to that point, users were doomed to implement this as part of the application logic, often hurting the length of the development lifecycle as well as the maintainability of the code. And, although there isn’t a single, commonly accepted definition of temporal data, the challenge it represents is one and the same: how do we validate or enrich data against dynamically changing, historical datasets?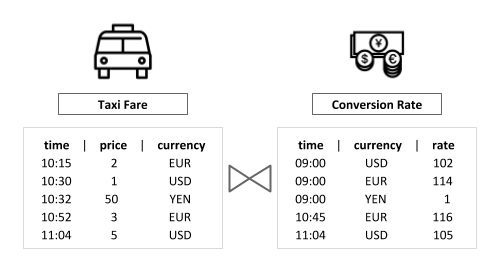 For example: given a stream with Taxi Fare events tied to the local currency of the ride location, we might want to convert the fare price to a common currency for further processing. As conversion rates excel at fluctuating over time, each Taxi Fare event would need to be matched to the rate that was valid at the time the event occurred in order to produce a reliable result.
For example: given a stream with Taxi Fare events tied to the local currency of the ride location, we might want to convert the fare price to a common currency for further processing. As conversion rates excel at fluctuating over time, each Taxi Fare event would need to be matched to the rate that was valid at the time the event occurred in order to produce a reliable result.
Modelling Temporal Data with Flink
In the 1.7 release, Flink has introduced the concept of temporal tables into its streaming SQL and Table API: parameterized views on append-only tables — or, any table that only allows records to be inserted, never updated or deleted — that are interpreted as a changelog and keep data closely tied to time context, so that it can be interpreted as valid only within a specific period of time. Transforming a stream into a temporal table requires:
-
Defining a primary key and a versioning field that can be used to keep track of the changes that happen over time;
-
Exposing the stream as a temporal table function that maps each point in time to a static relation.
Going back to our example use case, a temporal table is just what we need to model the conversion rate data such as to make it useful for point-in-time querying. Temporal table functions are implemented as an extension of Flink’s generic table function class and can be defined in the same straightforward way to be used with the Table API or SQL parser.
import org.apache.flink.table.functions.TemporalTableFunction;
(...)
// Get the stream and table environments.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.getTableEnvironment(env);
// Provide a sample static data set of the rates history table.
List <Tuple2<String, Long>>ratesHistoryData =new ArrayList<>();
ratesHistoryData.add(Tuple2.of("USD", 102L));
ratesHistoryData.add(Tuple2.of("EUR", 114L));
ratesHistoryData.add(Tuple2.of("YEN", 1L));
ratesHistoryData.add(Tuple2.of("EUR", 116L));
ratesHistoryData.add(Tuple2.of("USD", 105L));
// Create and register an example table using the sample data set.
DataStream<Tuple2<String, Long>> ratesHistoryStream = env.fromCollection(ratesHistoryData);
Table ratesHistory = tEnv.fromDataStream(ratesHistoryStream, "r_currency, r_rate, r_proctime.proctime");
tEnv.registerTable("RatesHistory", ratesHistory);
// Create and register the temporal table function "rates".
// Define "r_proctime" as the versioning field and "r_currency" as the primary key.
TemporalTableFunction rates = ratesHistory.createTemporalTableFunction("r_proctime", "r_currency");
tEnv.registerFunction("Rates", rates);
(...)
What does this Rates function do, in practice? Imagine we would like to check what the conversion rates looked like at a given time — say, 11:00. We could simply do something like:
SELECT * FROM Rates('11:00');
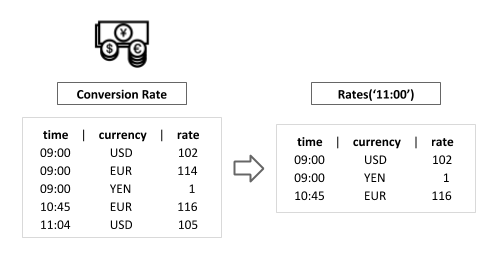
Even though Flink does not yet support querying temporal table functions with a constant time attribute parameter, these functions can be used to cover a much more interesting scenario: temporal table joins.
Streaming Joins using Temporal Tables
Temporal tables reach their full potential when used in combination — erm, joined — with streaming data, for instance to power applications that must continuously whitelist against a reference dataset that changes over time for auditing or regulatory compliance. While efficient joins have long been an enduring challenge for query processors due to computational cost and resource consumption, joins over streaming data carry some additional challenges:
-
The unbounded nature of streams means that inputs are continuously evaluated and intermediate join results can consume memory resources indefinitely. Flink gracefully manages its memory consumption out-of-the-box (even for heavier cases where joins require spilling to disk) and supports time-windowed joins to bound the amount of data that needs to be kept around as state.
-
Streaming data might be out-of-order and late, so it is not possible to enforce an ordering upfront and time handling requires some thinking to avoid unnecessary outputs and retractions.
In the particular case of temporal data, time-windowed joins are not enough (well, at least not without getting into some expensive tweaking): sooner or later, each reference record will fall outside of the window and be wiped from state, no longer being considered for future join results. To address this limitation, Flink has introduced support for temporal table joins to cover time-varying relations.
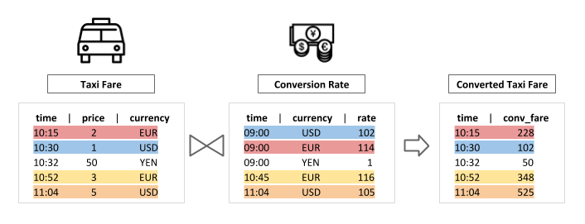
Each record from the append-only table on the probe side (Taxi Fare) is joined with the version of the record from the temporal table on the build side (Conversion Rate) that most closely matches the probe side record time attribute (time) for the same value of the primary key (currency). Remember the temporal table function (Rates) we registered earlier? It can now be used to express this join as a simple SQL statement that would otherwise require a heavier statement with a subquery.

Temporal table joins support both processing and event time semantics and effectively limit the amount of data kept in state while also allowing records on the build side to be arbitrarily old, as opposed to time-windowed joins. Probe-side records only need to be kept in state for a very short time to ensure correct semantics in presence of out-of-order records. The challenges mentioned in the beginning of this section are overcome by:
-
Narrowing the scope of the join: only the time-matching version of ratesHistory is visible for a given taxiFare.time.
-
Pruning unneeded records from state: for cases using event time, records between current time and the watermark delay are persisted for both the probe and build side. These are discarded as soon as the watermark arrives and the results are emitted — allowing the join operation to move forward in time and the build table to “refresh” its version in state.
All this means it is now possible to express continuous stream enrichment in relational and time-varying terms using Flink without dabbling into syntactic patchwork or compromising performance. In other words: stream time-travelling minus the flux capacitor. Extending this syntax to batch processing for enriching historic data with proper (event) time semantics is also part of the Flink roadmap!
You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
