













Generic Log-based Incremental Checkpoint (GIC for short in this article) has become a production-ready feature since Flink 1.16 release. We previously discussed the fundamental concept and underlying mechanism of GIC in our blog post titled "Generic Log-based Incremental Checkpoints I" [1]. In this blog post, we aim to provide a comprehensive analysis of GIC’s advantages and disadvantages by conducting thorough experiments and analysis.
Overview
To give you a brief overview, making a checkpoint in Flink consists of two phases: synchronous phase and asynchronous phase (sync phase and async phase for short). During the sync phase, in-memory states are flushed to disk, while in the async phase, local state files are uploaded to remote storage. A checkpoint completes successfully if every task successfully finishes its async phase. It’s important to note that for jobs with a large number of tasks and large states, the duration of the async phase determines how fast and stable a checkpoint can be. However, there are two problems in the async phase when GIC is not enabled:
- The size of files to upload heavily depends on the implementation of the Flink state backend, which means that these files may not always be small.
- The async phase does not start until the sync phase finishes.
For instance, let’s take the example of RocksDB, which is one of the commonly used state backends in Flink. Though Flink supports RocksDB incremental checkpoint, RocksDB's compaction leads to large fluctuations in the size of uploaded files. This is because compaction may create lots of new files, which need to be uploaded in the next incremental checkpoint. As a result, some tasks may end up spending more time uploading newly generated files during the async phase, which can lead to longer checkpoint completion time. With a large number of tasks, the probability of some tasks spending more time in the async phase is high.
For the second problem, without GIC, the set of files to be uploaded is not ready until the end of the sync phase. Hence, the async phase can not start before that, wasting a large proportion of time between two consecutive checkpoints. In other words, file uploading in the async phase happens in a short period of time without GIC. If uploaded files are large in size, file uploading will take up lots of CPU and network resources in a short duration of time.
GIC is introduced to address the above issues by decoupling the procedure of state backend materialization from the Flink checkpoint procedure. Specifically, the state updates are not only inserted into the state backend but also stored as state changelogs in an append-only mode. The state backend periodically takes a snapshot and persists the snapshot to remote DFS. This procedure is denoted as materialization in GIC and is independent of the checkpoint procedure of Flink jobs. The interval of materialization is usually much larger than checkpointing, 10 minutes by default. Meanwhile, state changelogs are continuously uploaded to durable storage. In checkpointing, only the part of state changelogs not yet uploaded needs to be forcibly flushed to DFS. In this way, data to upload in each async phase becomes small and stable.
GIC is designed to improve the speed and stability of the checkpoint procedure, with benefits including more stable and lower end-to-end latency for exactly-once sinks, less data replay after failover due to shorter checkpoint duration, and more stable cluster resource utilization. On the flip side, GIC slightly degrades the maximum processing capacity and a controlled increase in resource consumption (remote DFS storage). This blog analyzes the benefits and costs of GIC mentioned above and shares the corresponding evaluation results in detail.
2 Pros. and Cons.
2.1 More Stable and Lower End-to-end Latency
End-to-end processing latency is a key performance indicator for a Flink job, which represents the time between receiving input data and producing results. A lower end-to-end processing latency can improve the data freshness in the downstream system. Flink's checkpoint procedure realizes the exactly-once semantic within a job. To guarantee the end-to-end exactly-once semantic, the source needs to support replay and the sink needs to support transactions. As illustrated in Figure 1, only after the checkpoint is completed, the transactional sink can submit the committed offset. Therefore, the faster a checkpoint can be made, the more frequently a transactional sink can submit, thereby providing a lower end-to-end latency.
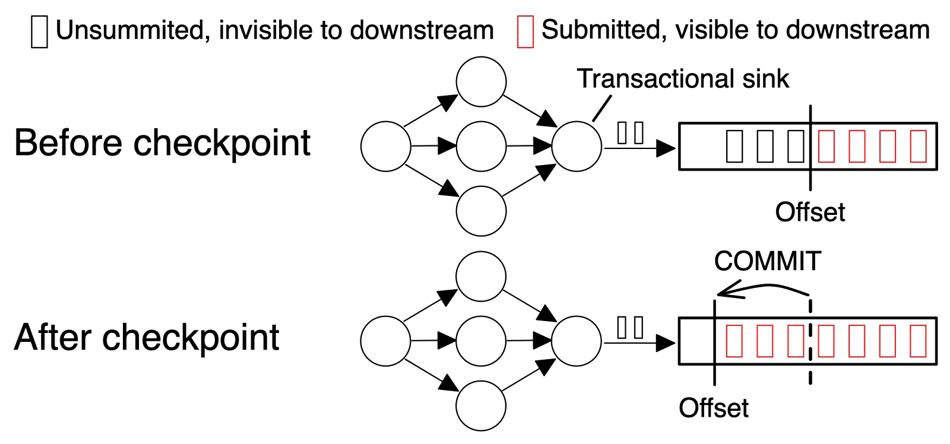
Figure 1: End-to-end latency of a transactional sink
GIC reduces end-to-end processing latency and improves stability. As mentioned above, GIC decouples the state backend's materialization from the checkpoint procedure, which mitigates the effect of unpredictable time spent in uploading files due to state backend implementation details (compaction for example). Moreover, only a small amount of state changelogs need to be uploaded during the checkpoint procedure. These enhancements accelerate the checkpoint's async phase, making the checkpoint procedure faster and resulting in lower end-to-end latency and better data freshness.
2.2 Less Data Replay after Failover
If the sink does not support transactions, data replay leads to duplicated outputs to the downstream system. This causes data correctness issues if the downstream system does not support deduplication. Output duplication is introduced by data replay. When recovering from a failover, Flink rolls back to the latest complete checkpoint. As shown in Figure 2, the amount of data to replay is the amount of data from the last checkpoint to the time of job failure. Since GIC allows for faster checkpoint completion, the amount of data to replay is reduced, which can be particularly beneficial for businesses that are sensitive to data duplication, such as BI aggregation, thereby enhancing data quality.
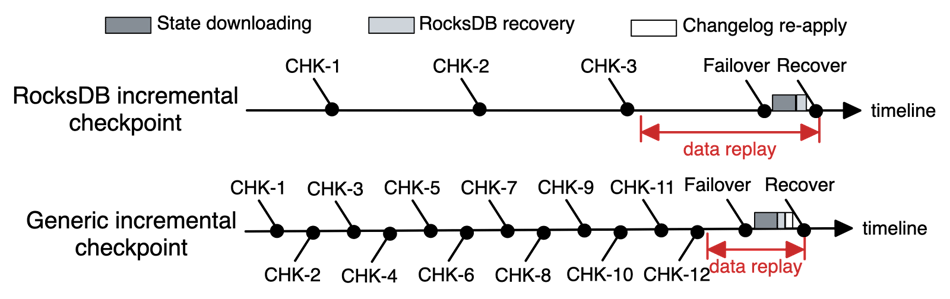
Figure 2: Data replay after failover using RocksDB Vs. GIC
2.3 More Stable Utilization of Resources
Triggering a checkpoint can lead to a burst in CPU and network usage, especially for jobs with large states. Let’s take RocksDB as an example, without GIC enabled, each checkpoint triggers a flush from memory to disk, resulting in a RocksDB compaction. Compaction usually consumes a significant amount of IO and CPU resources, and that's the reason why we see spikes in CPU and IO metrics right after a checkpoint is triggered. In addition, the uploading of state files (the async phase of a checkpoint) of all instances overlaps with each other. This results in a surge in network resource usage in a short period of time, which sometimes saturates the outbound traffic, causing the entire cluster unstable.
As shown in Figure 3, after triggering a checkpoint, all instances upload files to DFS almost simultaneously. For a job with large states, burst CPU usage indicates that more CPU resources may need to be reserved and burst traffic may cause checkpoint timeout. Clusterwise, jobs may still share CPU and network resources even though modern container techniques provide isolation. Hence, burst CPU and network usage may cause the entire cluster unstable.
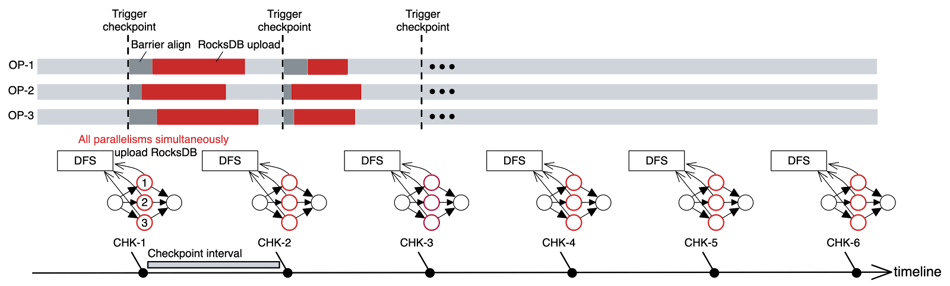
Figure 3: File uploading during the async procedure of RocksDB incremental checkpoint.
GIC can effectively reduce and stabilize CPU and network usage. On the one hand, GIC continuously uploads incremental state changelogs to DFS, thereby evenly scattering file uploading work along the time. On the other hand, GIC can reduce the materialization frequency of state backends, and the materialization of each instance is randomized. As shown in Figure 4, with GIC enabled, the file uploading of different instances is evenly distributed within the entire materialization interval. The materialization of the RocksDB state backend becomes low-frequency and scattered.
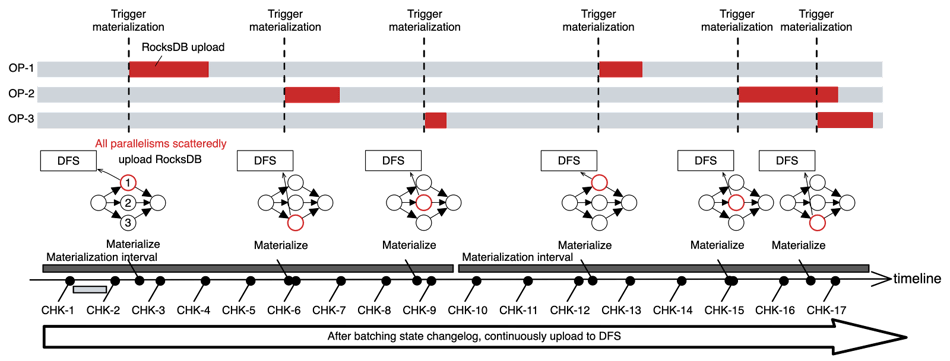
Figure 4: File uploading during the materialization of RocksDB state backend in GIC.
2.4 Predictable Overhead
Negligible performance influence caused by dual-writes (2 ~ 3%)
Dual-writes denote that GIC needs to write state updates to the underlying state backend and state changelogs at the same time. Intuitively, dual-writes bring extra processing overhead for each state update. As shown in Figure 5, GIC introduces a Durable Short-Term Log (DSTL) to manage the state changelog. State changelogs are sequentially batched in an append-only format. According to evaluation results, when network bandwidth is not a bottleneck, dual-writes have a negligible impact on the maximum processing capability (2 ~ 3%).

Figure 5: The procedure of dual-write, using RocksDB state backend.
Predictable overhead on network usage and DFS storage
The data stored in the remote DFS with GIC enabled consists of two parts: a materialized snapshot of the underlying state backend and state changelogs in DSTL. State changelogs are deleted after the corresponding changes are reflected in the materialized snapshot and are not referenced by any active checkpoint anymore. Therefore, in theory, DSTL reaches its maximum just before materialization is finished but its corresponding changelogs have not yet been cleaned up. Given that state updates usually have regular patterns for a given operator, the maximal size of DSTL is estimable. Accordingly, we can adjust parameters to control the size. For example, shortening the materialization interval can reduce the maximal DSTL size. As shown in Figure 6, the materialization part remains unchanged between two adjacent materialization executions, while DSTL keeps accumulating state changelogs. CHK-7 is the largest amongst checkpoints from t1 to t8, i.e., CHK-2 to CHK-9 as CHK-7 is the last checkpoint after MID-1 and before MID-2, including all state changelogs between t1 and t7.
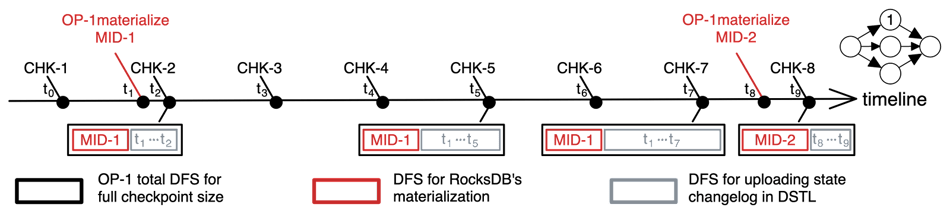
Figure 6: OP-1's DFS usage of full checkpoint size during checkpoint progress.
It is worth mentioning that the cost of DFS only accounts for a small proportion of the entire job's billing. For example, the monthly fee for Amazon S3 is $0.021/GB [2]. Namely, the monthly storage fees are less than 0.21$ for 10 GB, which is far less than the bill for the computing resources, e.g, CPU and memory.
The extra network overhead is caused by the continuous uploading of state changelogs. However, this overhead can be counterweighted by the lower frequency of materialization. Moreover, checkpointing usually uses intranet traffic, with negligible cost as well.
3 Performance Evaluation
We use the following experiments to illustrate the pros. and cons. of GIC analyzed above in this section.
3.1 Setup
- Version: Flink 1.16, FRocksDB 6.20.3
- DFS: Aliyun OSS
- Memory: Task Manager 1 core 4GB, Job Manager 1 core 4GB
- Deployment mode: K8S application
- Parallelism: 50
- State backend: RocksDB (incremental checkpoint enabled)
- checkpoint interval: 1 second
- Materilazation interval: 3 minutes
Two widely used types of states are selected: states with aggregated data and with raw data:
- Aggregation (with aggregated data): Typically, aggregation jobs accumulate multiple inputs to one value based on aggregate functions such as min, max, count, etc. WordCount is chosen in this case, as a typical aggregation job. In the testing, the state size per instance is about 500 MB (medium-size state) with each word 200 bytes.
- Window (with raw data): Window states keep raw input from a stream, and slide over it. A sliding window job is picked up in this case. The state size per instance is about 2 GB with per record length of 100 bytes.
3.2 Faster Checkpoint
This experiment uses the number of completed checkpoints (in Table 1) and checkpoint duration (in Table 2) to measure the speed of checkpoint completion. Their results show that GIC can greatly speed up the completion of checkpoints.
With GIC enabled in Table 1, the number of checkpoints completed for the WordCount job increased by 4.23 times, and for the Sliding Window Job increased by nearly 40 times. In Table 2, with GIC enabled, the average checkpoint duration for the wordCount and window jobs dropped by 89.7% and 98.8%, respectively. For the sliding window job with a relatively large state size, the checkpoint duration can be reduced from minutes to seconds.
Table 1: Number of completed checkpoints within 12 hours.
|
GIC Enabled |
GIC Disabled |
Increase ratio |
|
|
Wordcount |
18936 |
3621 |
4.23 times |
|
Window |
11580 |
294 |
38.39 times |
Table 2:Checkpoint duration with or without GIC.
|
P50 |
P99 |
P99.9 |
|
|
Wordcount |
-89.7% (10.21s -> 1.05s) |
-79.5% (16.08s -> 3.30s) |
-72.3% (17.76s -> 4.92s) |
|
Window |
-98.8% (129.47s -> 1.58s) |
-98.8% (383.63s -> 4.47s) |
-98.8% (408.79s -> 4.96s) |
Checkpoint is accelerated due to the reduced amount of data uploaded to DFS during the checkpoint async phase. As shown in Figure 7 and Figure 8, the size of incremental checkpoints is reduced by more than 95% when GIC is enabled. This is because of the continuous writing and uploading of changelog data. Hence when a checkpoint is triggered, only the not-yet uploaded state changes (less than 5MB) needs to be flushed and transited to DFS, which is much smaller than the size without GIC.
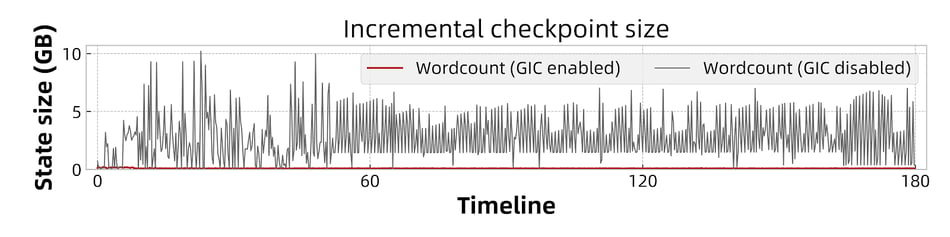
Figure 7: Incremental checkpoint size of wordCount.
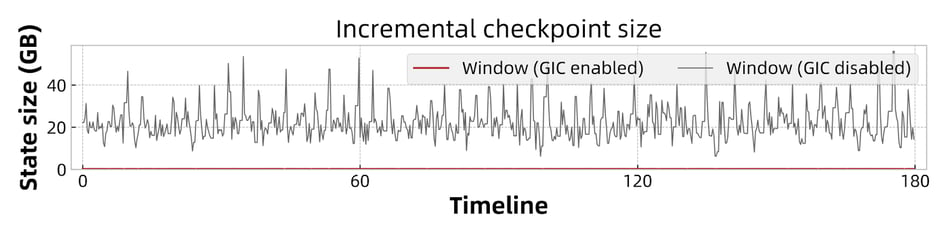
Figure 8: Incremental checkpoint size of the window job.
Faster checkpoints lead to shorter end-to-end latency for sinks supporting transactions. A transactional sink finishes committing only after a checkpoint is completed. Therefore, for exactly-once sinks, GIC can significantly reduce the end-to-end latency (from minutes to seconds).
3.3 More Stable & Predictable Checkpoint
The fluctuation range of checkpoint duration (duration to complete a checkpoint) is used to measure the stability of checkpoints in this experiment. As shown in Figure 9 and Figure 10, the checkpoint duration of the wordCount and window jobs are kept within 5 seconds with GIC enabled. Without GIC, the duration fluctuates in a much wider range. In the case of Sliding Windows, the range exceeds 100 seconds and in extreme cases, it exceeds 400 seconds.
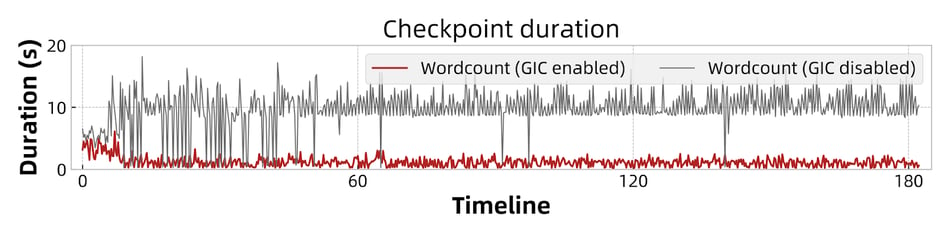
Figure 9: Checkpoint duration of wordCount.
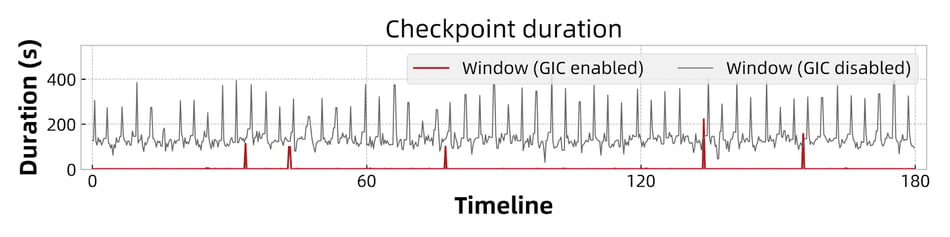
Figure 10: Checkpoint duration of Sliding Window.
The main reason for the improved checkpoint stability is decoupling the state backend's materialization from the checkpoint procedure. RocksDB is used in this experiment. The incremental checkpoint size depends on the RocksDB snapshot mechanism, and the internal compaction of RocksDB will affect the size of the incremental files generated by the RocksDB snapshot, leading to the uploading time varying in a wider range. GIC only needs to upload the incremental state changelogs in the async phase, which effectively avoids the negative impact of RocksDB compaction, making the checkpoint duration fluctuate within a small range.
3.4 Less Data Replay after Failover
We use lag from Sources to roughly estimate the amount of data to replay after a failover, which is measured by currentEmitEventTimeLag[3] in a Kafka Source. The same sliding window job is used in this case and triggered to fail by injecting a special record in the source. As shown in Figure 11, the data replay time is reduced from 180 seconds to 105 seconds with GIC enabled, a reduction of 41.7%.
.
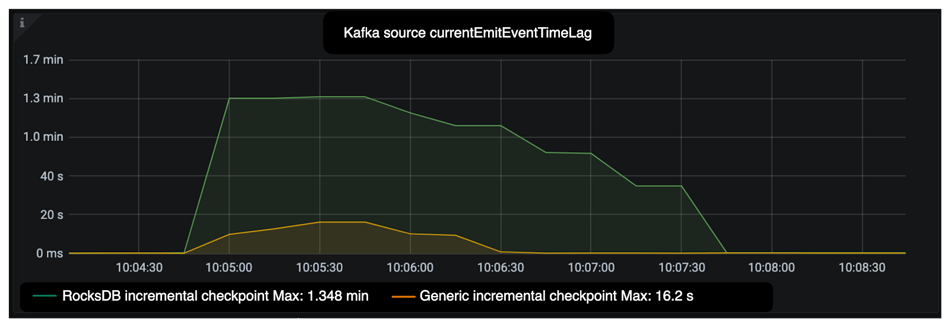
Figure 11: The currentEmitEventTimeLag metric of Kafka source in window job.
Lag from Sources after a failover is also affected by the recovery speed, so let us take a look at this part for the same experiment. Table 3 shows the P99 time spent on Recovery. With GIC enabled, extra 16 seconds is needed to re-apply the state changelogs. Since local recovery is enabled, time spent in state downloading is saved.
Combining the results shown in Table 3 with the source lag shown in Figure 11, we can conclude that the amount of data replayed is significantly reduced. Data replay affects data duplication for non-transactional sinks as discussed in Section 2.2.
Table 3: P99 duration of the steps to recover window job.
|
State downloading |
RocksDB Recovery |
Changelog Re-apply |
|
|
GIC Enabled |
- |
0.094 s |
16.7 s |
|
GIC Disabled |
- |
0.129 s |
- |
3.5 More Stable Utilization of Cluster Resource
We use the wordcount job with a single parallelism state size set at about 2GB to compare the CPU usage and network traffic. Three experiments are set up as follows:
- Case 1: Checkpoint interval 10min, GIC disabled.
- Case 2: Checkpoint interval 10s, GIC disabled.
- Case 3: Checkpoint interval 10s, Materialization interval 3 min, GIC enabled.
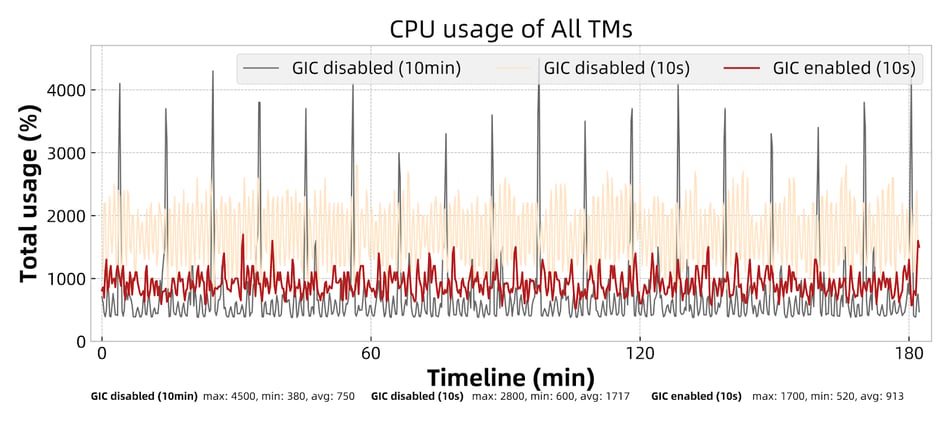
Figure 12: Total CPU usage of all TMs.
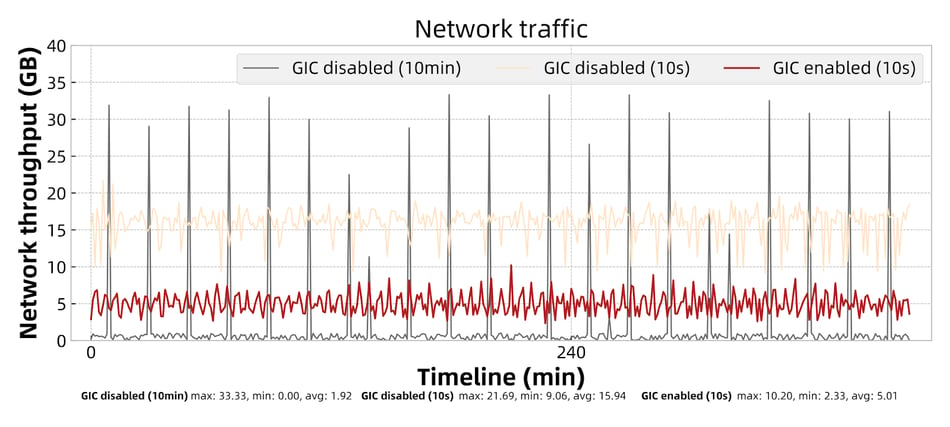
Figure 13: Network traffic of the job.
Comparing the data of the three experiments on CPU usage and network traffic, we can see:
- With GIC disabled and a 10-minute checkpoint interval, the CPU usage and network traffic fluctuate in a wide range. The peak usage of both CPU and network is 10X times higher compared to the average. The peak fluctuation occurs at the same time as checkpoints are triggered, causing each RocksDB backend instance to compact at roughly the same time. This will affect the stability of the entire cluster, and will also result in a waste of resources because we have to reserve peak resources for the stability concern.
- With GIC disabled and a 10-second checkpoint interval, the peak CPU usage and network traffic decrease by 37.8% and 34.9% compared to the first case. However, their average values increase by 128.9% and 730.2% and the fluctuation range is still large. Shortening the checkpoint interval reduces the peak value because it results in fewer state updates within a checkpoint interval and consequently reduces the amount of data to be uploaded. However, the frequency of compaction increases, which leads to an increase in the average resource usage.
- With GIC enabled and a 10-second checkpoint interval, the peak value decreases by 62.2% and 69.4% compared to the first case; decreases by 39.3% and 53.0% compared to the second case. The average value decreases by 46.8% and 67.7% compared to the second case. Dropping in the peak and average value is mainly because of randomized and lower RocksDB compaction frequency (lower materialization frequency).
Based on the results presented, enabling GIC has been found to be an effective way to decrease computing and network traffic expenses. Furthermore, in a cloud-native environment with limited resources, GIC’s capacity to provide more stable CPU utilization and network traffic can enhance the stability of Flink’s TPS, thereby further improving the performance of the job.
3.6 Negligible Impact on Maximal TPS
In this experiment, we evaluate the impact of GIC on the maximum processing capability.
It is worth noting that GIC in Flink 1.16 has additional serialization overhead. After optimization in FLINK-30345 [4], Table 4 shows that the regression of maximum TPS is stable within 3%, which is very small. Even if local recovery is enabled at the same time, the performance impact is still negligible, as shown in Table 5, the decrease is within 5%. Overall, the overhead of dual-write (state changelog) and triple-write (local recovery) is negligible.
Table 4:After optimization in Flink 1.16, maximum processing capability with and without GIC
|
Setup |
GIC Disabled |
GIC Enabled |
Regression of Maximum Processing Capability |
|
|
Key Len |
State Size |
|||
|
16 |
30MB |
102550 |
101865 |
-0.7% |
|
128 |
100MB |
52086 |
50838 |
-2.4% |
|
16 |
1.2GB |
25865 |
25620 |
-0.9% |
|
128 |
7.6GB |
2550 |
2495 |
-2.2% |
Table 5:After enabling local recovery, maximum processing capability with and without GIC.
|
Setup |
GIC Disabled |
GIC Enabled |
Regression of Maximum Processing Capability |
|
|
Key Len |
State Size |
|||
|
16 |
30MB |
100829 |
98682 |
-2.1% |
|
128 |
100MB |
51125 |
48578 |
-4.9% |
|
16 |
1.2GB |
24898 |
24150 |
-3.0% |
|
128 |
7.6GB |
2434 |
2319 |
-4.7% |
3.7 Predictable DFS overhead
A GIC is composed of materialized states and incremental state changelogs, which requires more storage space than a normal checkpoint. The section of "Benchmark results" in [1] has related evaluation results. In this article, we demonstrate how to estimate the increased storage size.
The increased size mainly comes from state changelogs. As explained in the previous sections, DSTL reaches its maximal size just before materialization is finished but its corresponding changelogs are not yet cleaned up. Hence the maximal size can be roughly estimated as follows:
increment of full checkpoint size ≈ write operation rate × the size of each write operation × materialization interval
Let's verify the above formula using the window job with the ratio of window size / sliding size set to 10 and 5 respectively. According to the processing logic of the sliding window operator (Jave Flink implementation), the estimated increment of the full checkpoint size is:
increment of full checkpoint size ≈ (window + timer write operation rate) × (window + timer size) * materialization interval
As shown in Figure 14 and Figure 15, the increment in size is aligned with the above formula. Meanwhile, we find that the increment size of the window job follows a pattern. That is, for a fixed ratio of "window size / sliding length", the incremental size remains unchanged. For example, the increment size is approximately 1.74 GB when "window size / sliding length = 10", while the increment size is approximately 887.4 MB when the ratio is 5. This is because the "window size / sliding length" determines the "write operation rate" in the above formula. At the same time, the record size and materialization interval of the job are also fixed, so the increase in the full checkpoint is also fixed.
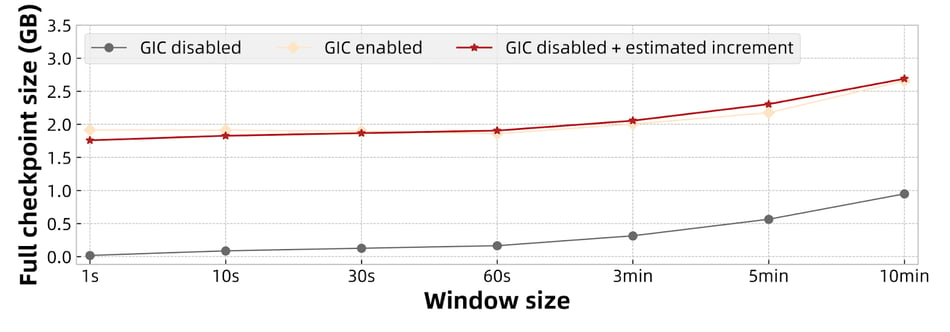
Figure 14: Full checkpoint size when window size / sliding length = 10.
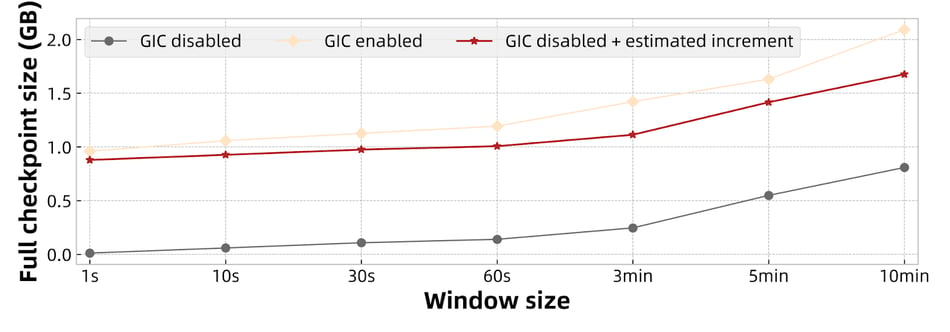
Figure 15: Full checkpoint size when window size / sliding length = 5.
Conclusion
GIC can significantly improve the speed and stability of a Flink checkpoint and can achieve lower end-to-end latency, less data recovery, faster recovery speed, and more stable utilization of cluster resources. On the flip side, GIC brings a slightly increased performance overhead and extra resource costs. However, they are almost negligible or tunable based on the analysis in this article.
GIC has been integrated as a production-ready feature since Flink 1.16 and will continue to be improved in future versions One potential improvement is replacing DSTL with other storage components, such as Apache Bookkeeper, to further reduce long tail delay during double writing. Furthermore, GIC will be integrated with other checkpoint options, such as unaligned checkpoint and buffer debloating, to provide the best checkpoint settings for specific user cases automatically.
Reference
[1] Improving speed and stability of checkpointing with generic log-based incremental checkpoints https://flink.apache.org/2022/05/30/changelog-state-backend.html
[2] The pricing of Amazon S3 Standard in US East https://aws.amazon.com/s3/pricing/?nc1=h_ls
[3] The currentEmitEventTimeLag metrics of Flink Kafka Source
[4] [Flink-30345] Improve the serializer performance of state change of changelog https://issues.apache.org/jira/browse/FLINK-30345
You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
