













In this blog post, we explain how Apache Flink works with Apache Kafka to ensure that records from Kafka topics are processed with exactly-once guarantees, using a step-by-step example.
Checkpointing is Apache Flink’s internal mechanism to recover from failures. A checkpoint is a consistent copy of the state of a Flink application and includes the reading positions of the input. In case of a failure, Flink recovers an application by loading the application state from the checkpoint and continuing from the restored reading positions as if nothing happened. You can think of a checkpoint as saving the current state of a computer game. If something happens to you after you saved your position in the game, you can always go back in time and try again.
Checkpoints make Apache Flink fault-tolerant and ensure that the semantics of your streaming applications are preserved in case of a failure. Checkpoints are triggered at regular intervals that applications can configure.
The Kafka consumer in Apache Flink integrates with Flink’s checkpointing mechanism as a stateful operator whose state are the read offsets in all Kafka partitions. When a checkpoint is triggered, the offsets for each partition are stored in the checkpoint. Flink’s checkpoint mechanism ensures that the stored states of all operator tasks are consistent, i.e., they are based on the same input data. A checkpoint is completed when all operator tasks successfully stored their state. Hence, the system provides exactly-once state update guarantees when restarting from potential system failures.
Below we describe how Apache Flink checkpoints the Kafka consumer offsets in a step-by-step guide. In our example, the data is stored in Flink’s Job Master. It’s worth noting here that under POC or production use cases, the data would usually be stored in an external file storage such as HDFS or S3.
Step 1:
The example below reads from a Kafka topic with two partitions that each contains “A”, “B”, “C”, ”D”, “E” as messages. We set the offset to zero for both partitions.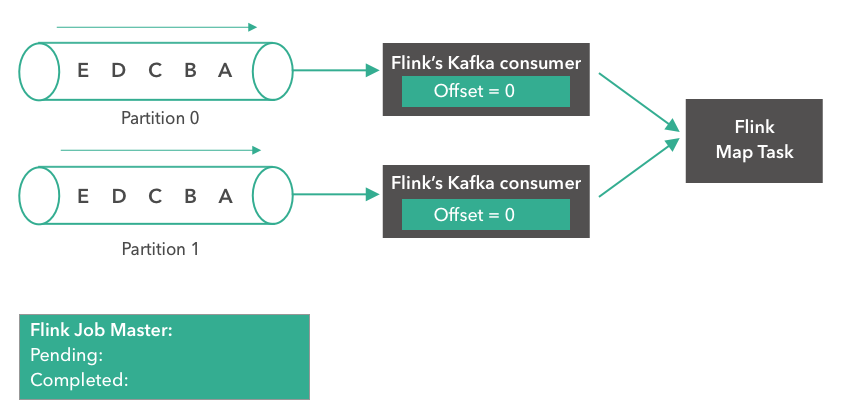
Step 2:
In the second step, the Kafka consumer starts reading messages from partition 0. Message “A” is processed “in-flight” and the offset of the first consumer is changed to 1. 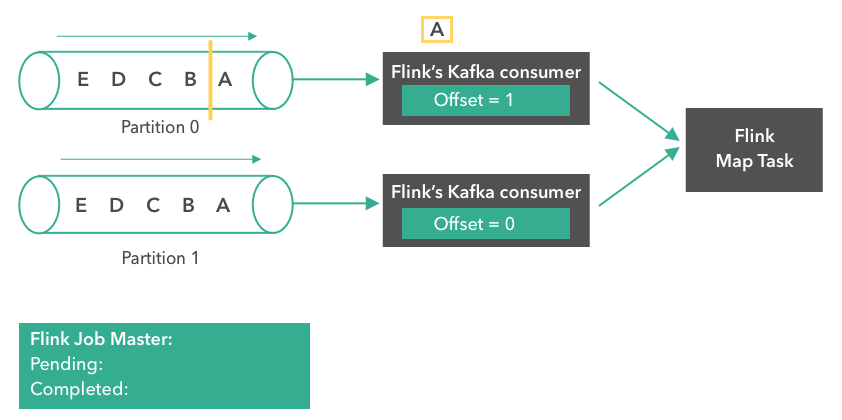
Step 3:
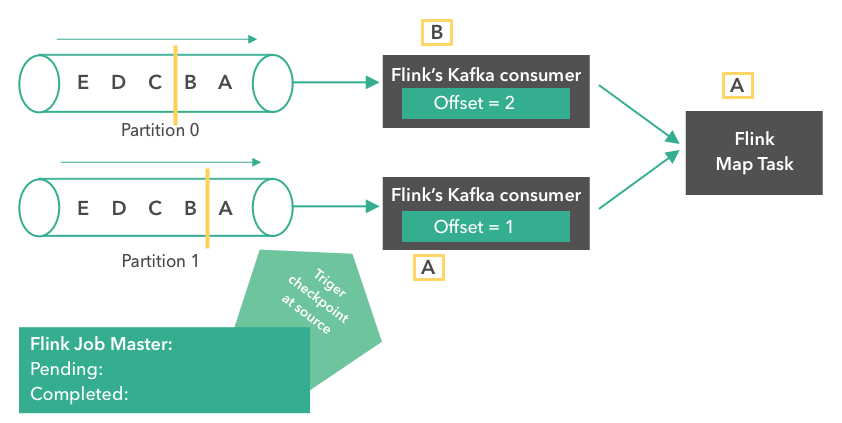
In the third step, message “A” arrives at the Flink Map Task. Both consumers read their next records (message “B” for partition 0 and message “A” for partition 1). The offsets are updated to 2 and 1 respectively for both partitions. At the same time, Flink's Job Master decides to trigger a checkpoint at the source.
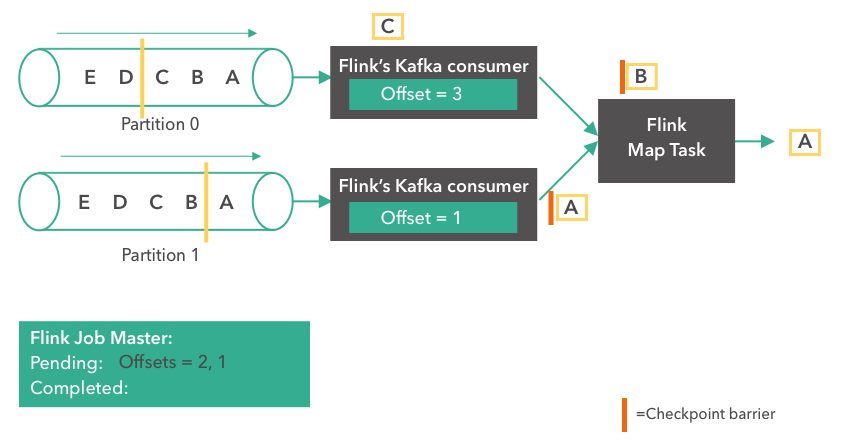
Step 4:
In the following step, the Kafka consumer tasks have already created a snapshot of their states (“offset = 2, 1”) which is now stored in Apache Flink’s Job Master. The sources emit a checkpoint barrier after messages “B” and “A” from partitions 0 and 1 respectively. The checkpoint barriers are used to align the checkpoints of all operator tasks and guarantee the consistency of the overall checkpoint. Message “A” arrives at the Flink Map Task while the top consumer continues reading its next record (message “C”).
Step 5:
This step shows that the Flink Map Task receives the checkpoint barriers from both sources and checkpoints its state to the Job Master. Meanwhile, the consumers continue reading more events from the Kafka partitions.
Step 6:
This step shows that the Flink Map Task communicates to Flink Job Master once it checkpointed its state. When all tasks of a job acknowledge that their state is checkpointed, the Job Master completes the checkpoint. From now on, the checkpoint can be used to recover from a failure. It’s worth mentioning here that Apache Flink does not rely on the Kafka offsets for restoring from potential system failures.
Recovery in case of a failure
In case of a failure (for instance, a worker failure) all operator tasks are restarted and their state is reset to the last completed checkpoint. As it is depicted in the following illustration.
The Kafka sources start from offset 2 and 1 respectively as this was the offset of the completed checkpoint. When the job is restarted we can expect a normal system operation as if no failure occurred before.
You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
