













At Flink Forward Global 2020, we presented how we on Intuit’s Data Platform team developed an internal, self-serve stream processing platform with Apache Flink as the primary stream processing engine. In this article, we recap our stream processing platform’s benefits and tech stack, and how Apache Flink is a critical technology in how we do real time data processing at Intuit.
About Intuit
Intuit provides financial software such as TurboTax, Mint and Quickbooks to individuals, businesses, and accountants. Intuit’s mission is to power prosperity around the world, and the Intuit Data Platform team focuses on this goal by accelerating the development of AI and data-driven solutions that enable our customers to access the right information at the right time, and ensure that their finances are handled correctly with high confidence.
Intuit’s Stream Processing Platform
In order to achieve this, we ran multiple interview sessions with our product teams at Intuit to find what data-driven solutions they need to be successful. Some of our key findings from those sessions included:
- Engineering teams needing to quickly develop stream processing applications to provide real-time, personalized experiences for their users
- Significant energy being spent to explore the many rich datasets at Intuit to understand data schemas and lineage on where that data came from
- Operational concerns on the overhead needed to perform lifecycle management and monitoring of these applications
- Operational concerns on the overhead needed to ensure these applications are compliant with our security and privacy standards (which is especially important for all the financial data we process at Intuit)
- Operational concerns on the overhead needed to tune, scale, and restack the infrastructure for these applications
In order to resolve these pain points, we developed the Stream Processing Platform (SPP) at Intuit with the goal of providing a self-serve capability for developers to focus on developing data processing business logic, while the platform handles all the operational and infrastructure management concerns on their behalf. SPP provides self-serve capabilities that enable our users to create and manage the lifecycle of their data processors (i.e., the data processing code representing the business logic for data transformations and aggregations) and their data pipelines (i.e., a deployment that represents an orchestration or DAG of one or multiple data processors). SPP handles the complexity of provisioning infrastructure in a multi-tenant, highly-available, reliable and scalable manner, and additionally manages data access controls to ensure user data is properly securitized.
With SPP, we jumpstart the development of stream processing pipelines by providing an end-to-end development and build environment within a ‘Hello World’ starter kit. Our SDK is based on Apache Beam, which provides flexibility in programming languages, such as Python or Java, as well as different runtime layers, such as Apache Flink. Our control plane microservice provides behind-the-scenes integration with the rest of Intuit’s data ecosystem, which maintains data lineage for all stream processing pipelines and provides insights into the cost of running these pipelines. We also provide out-of-the-box dashboards and tools for our customers to troubleshoot, monitor, and measure their pipelines, such as Wavefront and the Flink Web UI.
Stream Processing Platform Benefits
By providing self-serve capabilities, teams at Intuit are able to focus on the development of the business logic of their data transformations and largely ignore infrastructure and compliance requirements. This reduced the end-to-end development cycle for a stream processing pipeline from three months to within weeks. Users that migrated their batch processing jobs to SPP saw up to 240x improvement in real-time data availability and up to 5x infrastructure cost savings.

Stream Processing Platform Tech Stack
To guide our overview of SPP’s tech stack, the diagram below illustrates the basic topology of all pipelines running on our platform.
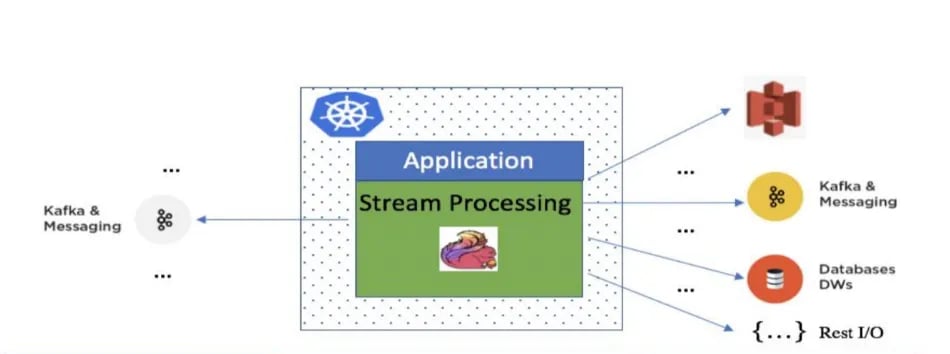
Real-time data can be ingested from different data sources, such as Apache Kafka or other messaging systems. The stream processing pipeline running on SPP will perform data transformations such as filtering, aggregations, enrichment, joins, etc. before publishing results to one or more data sinks (which may be data-in-motion messaging systems, data-at-rest datastores, or third party APIs).
SPP’s tech stack is composed of several different layers, as shown below.
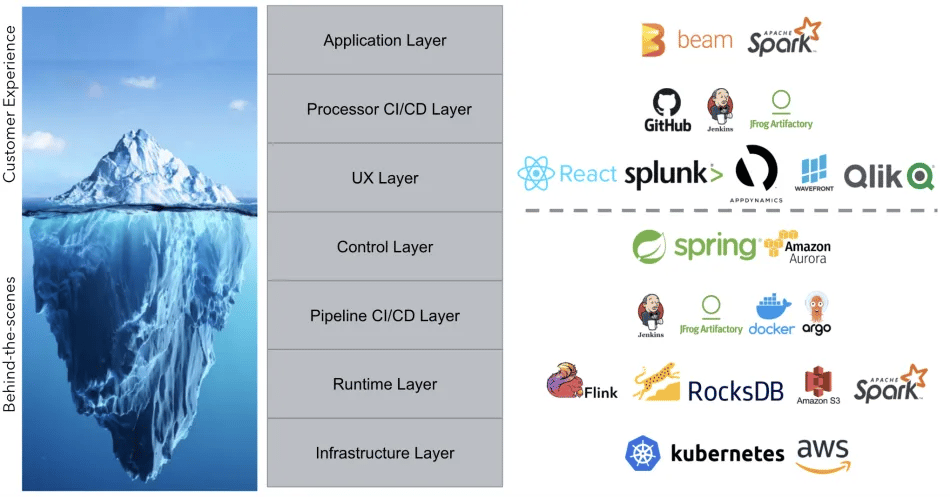
You can watch our talk recording for more details on each layer, but we’d like to highlight a few things here.
The Application Layer is where our customers do all their coding and development. It is based on Apache Beam, which supports multiple languages and both stream and batch execution. It also makes stream processing code agnostic to the technologies used in the Runtime Layer, which gave us a lot of flexibility with our tech stack. The core principle we used for the Application Layer was developer flexibility.
The UX Layer is where our customers configure and manage their stream processing pipelines. It is a React.js front-end and is what our customers see every day when using our platform. It allows them to configure their pipelines’ data sinks and sources, tune their compute resources, start and stop their pipelines, and find useful links to monitor the health and cost of their pipeline. This layer corresponds with our Control Layer, which is our Spring back-end that maintains metadata on all pipelines running on our platform and orchestrates interactions with the rest of the Intuit ecosystem for data governance, asset management, and data lineage. The core principle we used for the UX Layer was customer delight.
The Runtime Layer is what actually executes the Beam stream processing code. When designing our architecture, we wanted to work with technologies that are industry-proven and battle-hardened in terms of the use cases and scale they can support, and this is the main reason why Apache Flink is a first-class citizen in our runtime layer. This layer is composed of Flink clusters running on Kubernetes that get deployed via Argo workflows in our Pipeline CI/CD Layer. We use RocksDB as our state backend, and persist checkpoints and savepoints to Amazon S3. The core principle we used for the Runtime Layer was scalability.
Apache Flink is our stream processing engine of choice and is set as our default runner for several reasons. We wanted our Runtime Layer to support stateful processing, fault-tolerance, and strong at-least-once guarantees. Low deploy and restart latencies were also critical, to allow our customers to effortlessly patch code, tune resource provisioning, and not lose sleep during infrastructure restacks and maintenance. We also wanted an engine with rich operational metrics, such as checkpointing statistics, to enable customers to build operational dashboards and monitor the performance of their pipelines. Last but not least, support for auto-scaling was a must-have so that our users can easily scale their pipelines in situations like peak tax filing periods throughout our calendar year.
Here is a visualization of how these layers interact with each other.
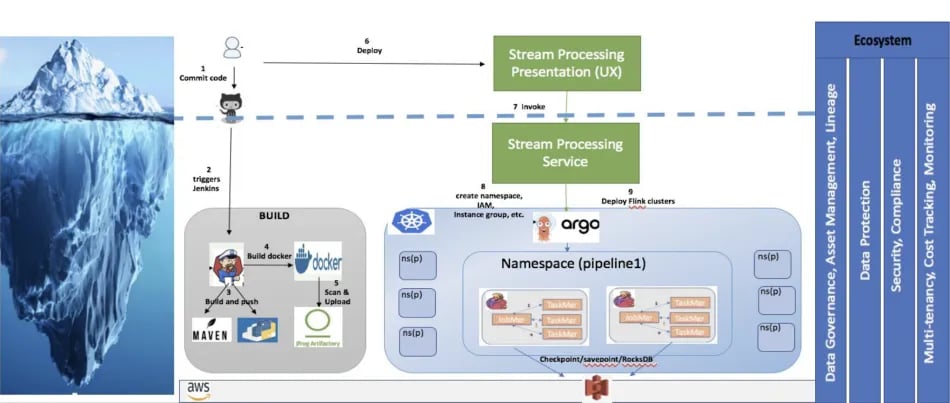
Conclusion & Lessons Learned
Building a self-serve stream processing platform from the ground-up enabled multiple teams at Intuit to accelerate how they develop stream processing applications. SPP increased developer velocity and lowered the barrier to entry to stream processing for a broad set of developers at Intuit, including many that had no or limited distributed systems, stream processing, or Apache Flink experience (including data scientists, iOS mobile engineers, and interns). In the end, anyone at Intuit can now build applications on top of Flink with low friction. This is primarily due to the fact that with SPP and its multiple abstraction layers on top of Flink’s Runtime Layer, developers can focus on refining their business logic from day one without worrying about operational concerns and the underlying infrastructure. As we further evolve SPP at Intuit, we are hoping that more organizations in the industry follow a similar path and understand the benefits of such platforms for their developer teams. We look forward to working alongside the Flink community to implement the latest features and technology improvements for our platform over the coming quarters!
If you would like to explore a demo and get a full picture of SPP, we suggest that you check the recording of our Flink Forward Global 2020 presentation or get in touch with us below.


You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
