













Introduction
Support for event time and stateful event processing are some of the features that make Apache Flink stand out compared to other stream processors. However, using event time may cause checkpoint failures in cases where various sources are progressing through time at different speeds. This post describes what is causing these issues, how you can check whether or not this is the case for your Flink job and proposes a solution to mitigate the problem.
Understanding checkpointing
When a periodic checkpoint is triggered, a consistent snapshot of all stateful operators in the execution plan needs to be made. The fact that the snapshots of the stateful operators are aligned with each other makes it consistent. This alignment process starts with Flink injecting so-called checkpoint barriers in the input channels at the source of the job.
The actual creation of a snapshot of an individual operator starts when a checkpoint barrier arrives at that operator. What happens next is dependent on the execution plan. In case this operator has a single input channel no further alignment is necessary and the snapshot for that particular operator will be created. However, in many Flink jobs there are operators that have multiple input channels, such as jobs that make use of joined streams and keyed operations. In that case, when the first checkpoint barrier arrives at an operator from a certain input channel, further inputs to that channel will be blocked until the checkpoint barriers from all other input channels of the same operator have also been received. Only after the last checkpoint barrier arrives, the snapshot for this operator will be created. Once finished, the operator outputs the checkpoint barrier needed by stateful operators further downstream.
The process described above makes it clear that the creation of snapshots will be slowed down, possibly beyond the checkpointing timeout, when the arrival of checkpoint barriers is being delayed. The Unaligned Checkpointing functionality that was introduced in Flink 1.11 is an improvement that mitigates these issues but in case of event time skeweness the amount of in-flight events can still grow very large.
Let’s look into how watermarks and event time can play a factor in delaying the arrival of checkpoint barriers.
Read more about 3 differences between Savepoints and Checkpoints in Apache Flink
Understanding watermarks
Next to the regular data events in a stream there are also the so-called “system events” that Flink injects into the stream. Examples of such system events are checkpoint barriers, as mentioned in the previous paragraph, but also watermarks.
Apache Flink uses watermarks to keep track of the progress in event time. The event time is extracted from one of the fields of the data event that contain the timestamp when that event was originally created.
Typically, watermarks are generated and added to the stream at the source. What is important to realize is that each individual source will generate its own watermarks and add them to the stream. So, at any given point-in-time there is not just one single event time in the system, but as many as the (instances of the) sources.
In an ideal scenario, your Flink job will consume events as fast as they are being produced so that all event times in your Flink job may all have — within a certain margin — the same time. However, sooner or later situations will occur where the various event times start to differ from each other, and so-called event time skewness appears.
In the next paragraphs we will look at what is causing event time skewness and what problems may arise because of that.
Read more about Watermarks here Watermarks in Apache Flink Made Easy
What is creating event time skewness
Event time skewness is the result of watermarks of the various instances of operators being far apart from each other over time.
One of the causes of event time skewness is when a Flink job needs to consume events from sources that have different characteristics. Let’s take the following set of sources as an example:
- One source with a load of one event per hour
- Another source with a load of 10K events per second
- Finally, a source with an infrequent high burst of events
Consuming this combination of sources will, over time, result in their respective watermark progression being significantly diverged from each other. This is often amplified after a Flink job failure, where the job needs to catch up reading events.
Another cause of event time skewness is when the distribution of the data itself is unbalanced. For example, certain keys can occur more often than others, making the corresponding operators where such keys are being processed to simply have more processing to do which may result in slower watermark progression.
Dive deep into Event time skewness here
Problems caused by event time skewness
In order to understand why event time skewness is a problem, one has to understand how operators make use of watermarks.
Many Flink jobs make use of window related functions and/or keyed operations where timers play an important role for stateful operators to determine what to emit and when.
These timers come with an onTimer(…) method that is being called only when the watermark of the operator reaches or exceeds the timestamp of those timers. Given the fact that such operators use the lowest watermark to trigger their timers, it becomes clear that event time skewness leads to a number of side effects, namely:
- The number of pending timers will increase, as will the amount of resources associated with them
- Backpressure is increasing
- The progress of checkpoint barriers will slow down and the overall checkpointing process will take longer resulting in input streams being blocked which in turn slows down the processing of events even further
These side effects may eventually lead to out-of-memory errors, checkpoint failures and even job crashes.
Reducing event time skewness
Since there are multiple causes of event time skewness, there are also multiple solutions that can be applied.
From Flink 1.11 onwards, there is out-of-the-box support for so-called idleness detection. A topic is called idle if it is not producing events for a longer period of time and hence resulting in no watermark progression. The solution offered by Flink is by marking this input source as “temporarily idle” when no events are being received within a configurable time period, causing this source to be ignored when determining the lowest watermark for an operator.
When reading a set of input sources with different characteristics, as explained earlier, a different solution needs to be applied. What we propose for this, is what we call “balanced reading”. Balanced reading can be implemented both at the level of an individual Kafka consumer as well as between the various instances of all Kafka consumers within the Flink job.
Before diving into the details of our proposed solution, let’s first go over how the Kafka client works.
Understanding the Flink Kafka consumer
The Flink Kafka consumer is based on the native Kafka client library and is a complex piece of software whose behavior is configurable via a large number of properties. It plays an important role in committing Kafka offsets, topic partition distribution, and more. Describing every detail of this library would require an entire blog on its own and therefore we limit ourselves to describing the most important aspects that play a key role in event time skeweness.
On a high level, the working of the Flink Kafka consumer consists of the following two-step process:
-
Initially, each Flink Kafka consumer instance of your Flink job gets assigned a number of partitions from which events will be consumed. These partitions may be part of the same topic, all from different topics, or a combination of both. The exact assignment is determined by the Flink Kafka Topic Partition Assigner.
-
Once the partitions have been assigned, each Flink Kafka consumer instance will start consuming events from the partitions it has been assigned to. The exact functionality is dependent on a number of settings. Some of the most relevant ones are:
-
partition.fetch.bytes: The maximum number of bytes being fetched per partition. This setting must be set larger or equal to the size of the largest possible event of any of the registered topic-partitions.
-
poll-timeout: The maximum duration that a single poll cycle will ‘wait’ for events to be consumed from the Kafka broker.
-
poll.records: The maximum number of events being consumed during a single poll cycle.
-
Now that we have a basic understanding of the Flink Kafka consumer, let’s take a look at two scenarios. In the first one, the Flink Kafka Consumer consumes events as fast as they are being produced, while in the second scenario the Flink Kafka Consumer is lagging behind and needs to catch up.
Scenario 1: Reading events as fast as they are being produced
After having been assigned a set of partitions by the Kafka partitioner, the Flink Kafka consumer instance will start consuming events from the first assigned partition. Once all events have been consumed, it will continue to consume events from the second partition that was assigned, etc. Under normal circumstances none of the limits of the three settings described earlier are hit before all events have been consumed.
Scenario 2: Reading events when catching up
As decribed before, there are situations where more events are available on a partition than can be consumed during a single poll cycle. The most obvious example is when some downtime occurred after which Flink needs to catch up.
In this scenario the Flink Kafka consumer instance will start consuming events from the first assigned partion. However, before all events have been consumed it will hit one of the thresholds of the three settings described earlier. Depending on the values of these settings, the threshold that may be hit first could be the ‘max.partition.fetch.bytes’ setting. The amount of progress that has been made in event time may vary significantly depending on the characteristics of the events of this partition. For instance, the event time will typically progress quicker on a topic with smaller events that have been produced at a low rate — meaning there is a relative big difference in event time between events — compared to a topic where events are larger and created at a higher rate.
Depending on the values of the ‘max poll time-out’ and ‘max.poll.records’ settings, the poll cycle continues consuming events from the other assigned partitions until these thresholds are met and the poll interval stops leaving remaining events to be consumed by the next poll cycle. It is very well possible that the poll cycle ends before events have been consumed from all partitions causing no progress in event times for some of the partitions. This process will repeat itself in the next poll cycle and only when the Flink Kafka consumer instance has caught up events from the first assigned partition(s) there will be enough remaining ‘poll time’ and/or ‘poll.records’ left to also consume events from the last assigned partitions.
The question now is how this affects the progress of watermarks further downstream in the Flink job. When catching up on the first assigned topic the watermarks may initially progress regularly. Once the Flink Kafka consumer has caught up reading events from the first partition, or when the max.partition.fetch.bytes threshold is hit, events will then be consumed from the next assigned topic. However, consuming events from that topic may not result in the progress of watermarks if the event times of events in that partition are older than the events of the first partition that have already been consumed by. In this case, we have a lot of ‘late events’, meaning events that are probably outside of the expected time-windows of operators further downstream.
It is worth mentioning that the behavior between different Flink Kafka consumer instances within the very same Flink job may also be different from each other in case each Flink Kafka consumer is assigned a different set of partitions with its own characteristics. Even the order of assigned partitions within a single Flink Kafka consumer is therefore relevant.
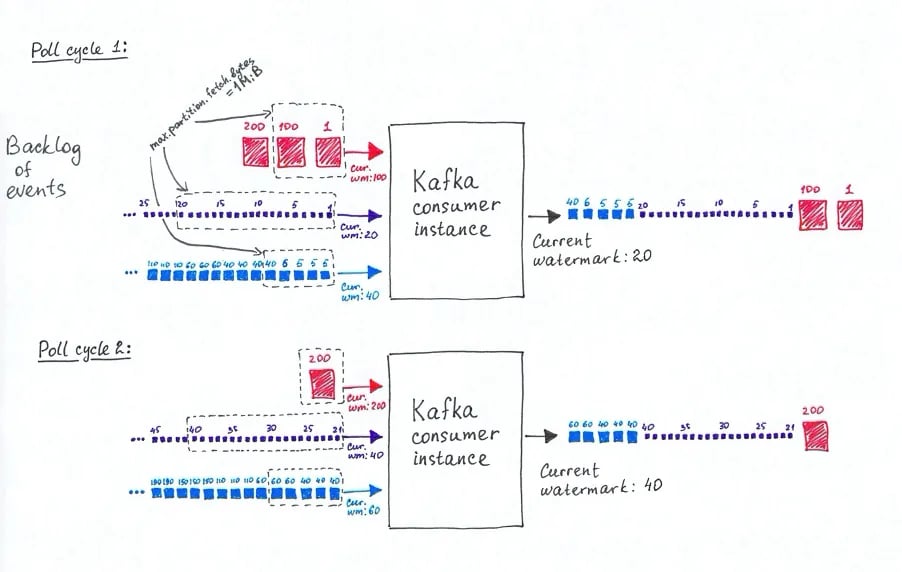 Example 1: Slow watermark progression based on the second partition although events with higher watermarks are already emitted.
Example 1: Slow watermark progression based on the second partition although events with higher watermarks are already emitted.
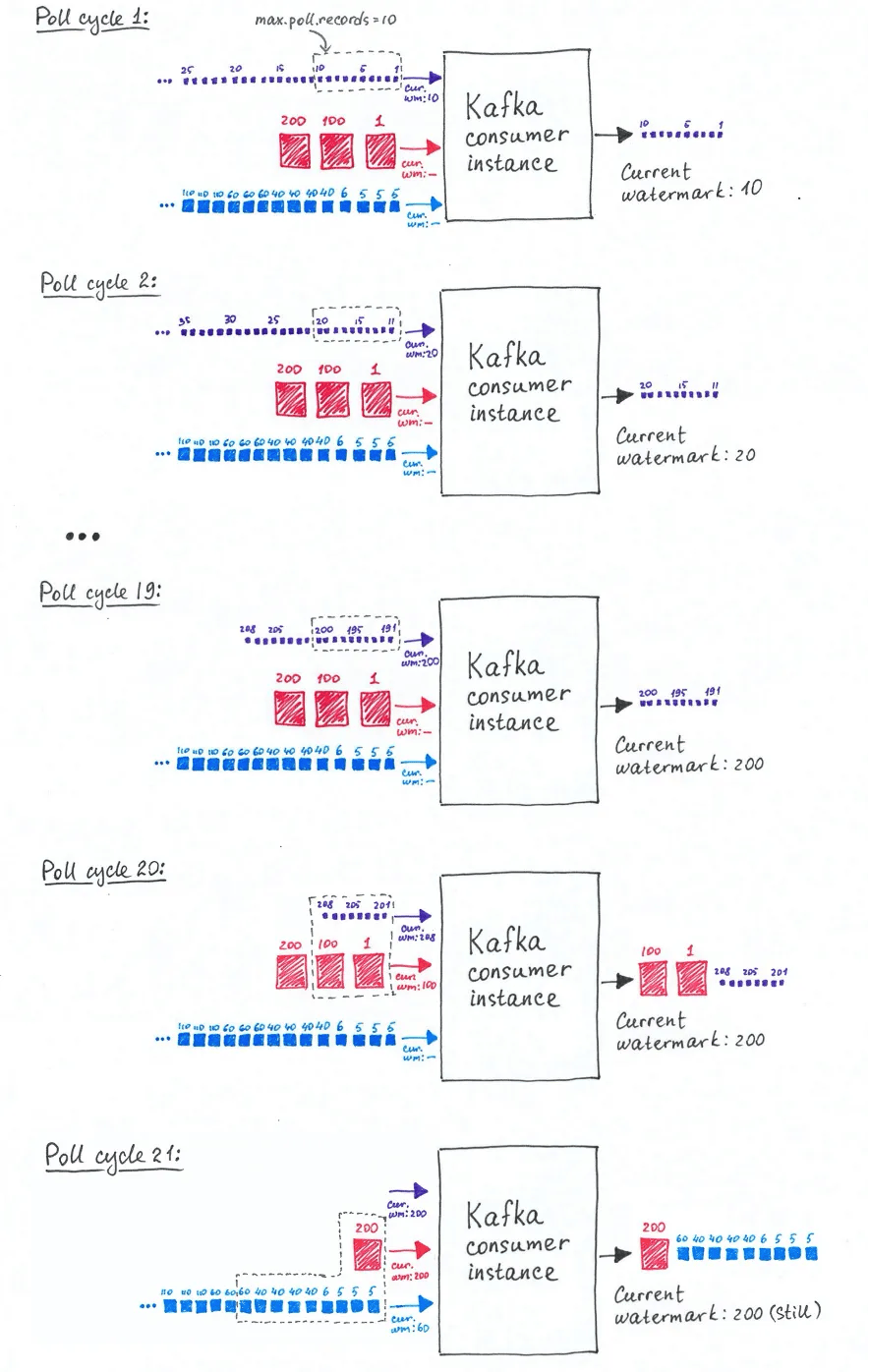 Example 2: Initially a steady watermark progression which later on does not progress for some poll cycles.
Example 2: Initially a steady watermark progression which later on does not progress for some poll cycles.
Finally, when considering that certain operators have multiple input sources and that both watermark progression and progression of checkpoint barriers depend on the watermark with the lowest event time, it is clear that we have a problem that needs to be addressed. Not doing so will result in checkpoints not being completed in time and timers piling up and being triggered too late. This, in turn, will result in increased job latency and potentially also checkpoint failures and increased memory footprint which may lead to your Flink job eventually crashing.
How to detect event time skewness
The most reliable way of knowing if the problem described here is happening in your Flink job would be by looking at the lag of the assigned Kafka partitions per Flink Kafka consumer. Unfortunately, these metrics are not available. It is of course possible to look at the lag of all Kafka partitions but because you do not know how these partitions are assigned to all Flink Kafka consumer instances, it is hard to draw any conclusions. So you need to draw your own conclusions based on some indirect indicators, such as looking into whether the total checkpointing times are increasing faster than the state size or whether there are differences in the checkpointing acknowledgement times between the various instances of the stateful operators. The latter may be partly caused by the fact that your data is not evenly distributed. Possibly the most reliable indicator is an irregular watermark progression of the Flink Kafka Consumer instances.
Balanced reading to the rescue
Reading the events from the Kafka topics in a balanced way will strongly mitigate the issues that are the result of the default behavior of the Kafka consumer. The balanced reading algorithm we used is also known under the name K-way merge.
K-way merge (or balanced reading) can be applied at two levels: the first one is balanced reading of assigned topics within a single Kafka consumer instance while the second includes the coordination that is needed across all Kafka consumer instances. We cover both levels in the following paragraphs.
Balanced reading within a single Kafka consumer can be achieved by making use of its so-called “Consumption Flow Control” mechanism. This mechanism enables you to temporarily pause consuming events from certain partitions within a poll cycle and then later on resume consuming events again for that partition in a later poll cycle.
Knowing when to pause and when to resume requires changing the algorithm of the Flink Kafka consumer as follows: initially the consumer tries to read all assigned partitions. In case some of the assigned partitions cannot be read in the first poll cycle, the already read partitions will be paused making sure the remaining assigned partitions will be read in the next poll cycle or any of the poll cycles thereafter. During this process we are queuing all events from all partitions and we are not emitting anything at this point. Only when all partitions have been read we can determine what has to be emitted by establishing the highest watermark across all non-idle topic partitions. The algorithm used to assemble the collection of events to be emitted is the so called K-way merge algorithm. This algorithm uses K-sorted lists as input — in our case the consumed events from the assigned partitions filtered on timestamps up until the highest common watermark. The result is a balanced list of events sorted by event time across all partitions. Emitting this sorted list will result in a gradual progress of watermarks.
This process then repeats itself at which point we can choose to further optimize it by having the algorith calculate the optimum value for the ‘poll-timeout’ of each poll cycle.
So far we explained how we can do balanced reading for a single Kafka Consumer instance. Question remains how do we do this across all instances of all Kafka Consumers within your Flink job. We are opting to the default Fink behavior here, where Flink operators with multiple input streams manage their watermark. This is then managed indirectly via backpressure which may introduce some latency, something that is preferable over introducing complex inter-node-communication.
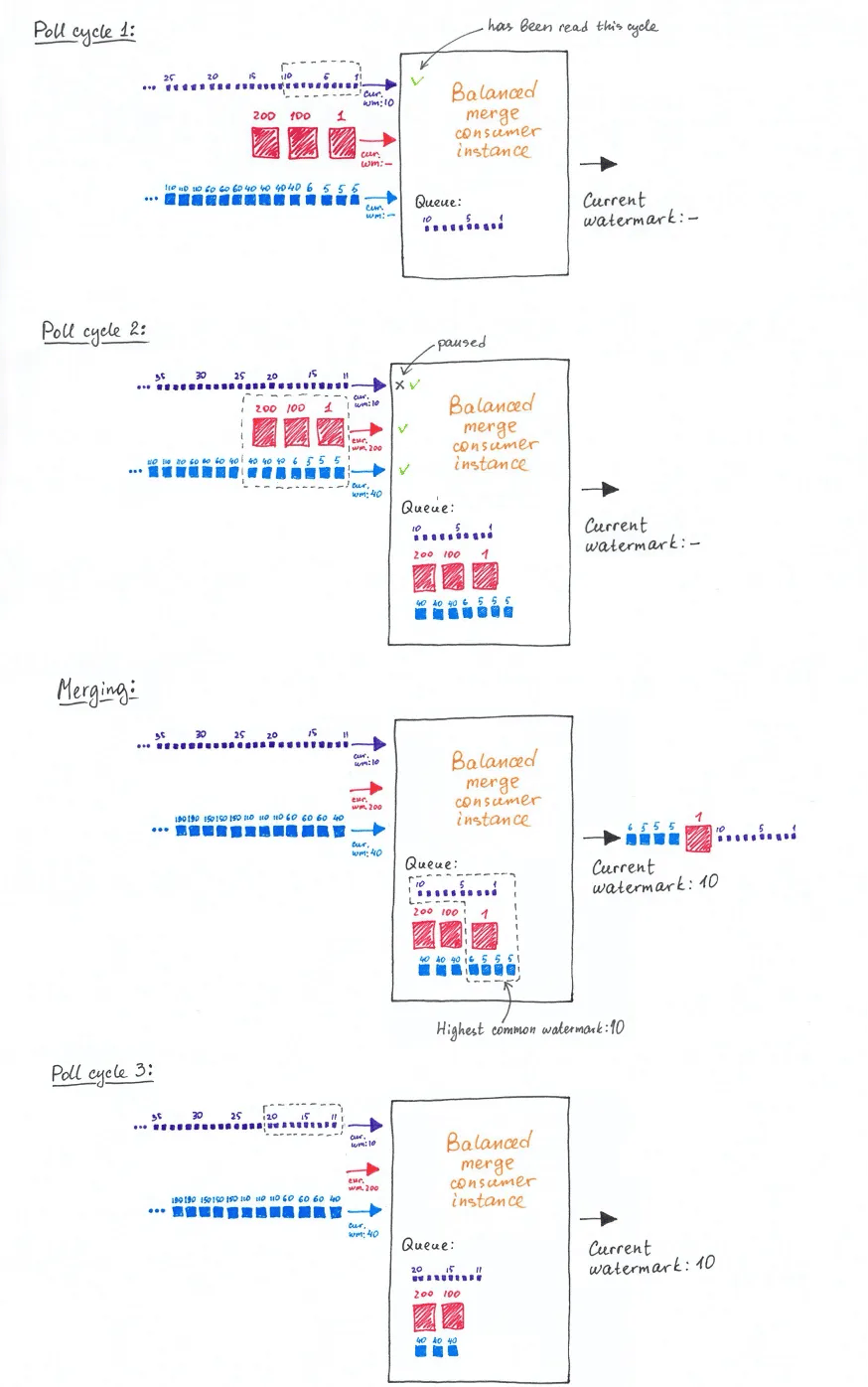
Example 3: Balanced reading resulting in a steadier watermark progression.
Pros and cons
Sometimes, solutions have a trade off where you need to balance both advantages and disadvantages. So does balanced reading, that has a small downside in case multiple poll cycles are necessary to read all assigned partitions before the Flink Kafka consumers can emit its events. The small latency that is introduced and the few extra CPU cycles that are needed are a small price to pay in order to achieve smoother watermark progression. In our case balanced reading did result in smoother progression of checkpoint barriers, fewer checkpoint barriers and in the end fewer task manager crashes.
About the authors
ING started with Apache Flink in 2016 as one of the early adaptors, at a time where there was no 1.0 version of Flink yet! Today this has evolved into what we internally at ING call SDA which is short for Streaming Data Analytics. SDA is the global standard within ING for real time event processing accross various domains. Both Fred Teunissen and Erik de Nooij have been working on SDA since day one. Fred as the lead engineer of the squad, Erik as engineering lead of the product area that SDA is a part of. Finally, a special thanks to Olga Slenders for her thorough review and for adding the graphics.
You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
