














This is a guest post written by Christian Kreutzfeldt (@mnxfst) and Alexander Kolb (@lofifnc) from the Otto Group Business Intelligence Department.
![]()
The Hamburg-based Otto Group is the world's second-largest online retailer in the end-consumer (B2C) business and Europe's largest online retailer in the end-consumer B2C fashion and lifestyle business. Significantly more than 60 percent of all income in the multichannel retail segment is generated online today. Compared to other market actors which mostly run a single website (country specific versions included), the Otto Group facilitates more than 100 sites across different companies and segments.
As most of these companies are operated independently, the Otto Group decided in 2012 to roll out a shop-independent web tracking to generate a consistent view on selected metrics and key performance indicators. Furthermore this information is part of the working foundation of the Otto Group Business Intelligence department. Its business is to apply advanced analytics to generate more in-depth insights by applying cutting edge technology and algorithms.
From a technical perspective the department operates a 2-layered hybrid data processing and storage platform. On the batch layer it follows a classical Hadoop setup extended by our own data processing scheduler Schedoscope. The layer receives all web tracking events on a daily basis and computes different profile views requested by the tracking project itself. The first requirements in terms of the stream processing layer have been defined with the advent of a live dashboard visualizing ecommerce traffic in our shops. As the dashboard supports multiple widgets and is highly configurable with respect to the selection of displayed widgets it demands a compatible flexibility from the underlying stream processing layer which provides the data.
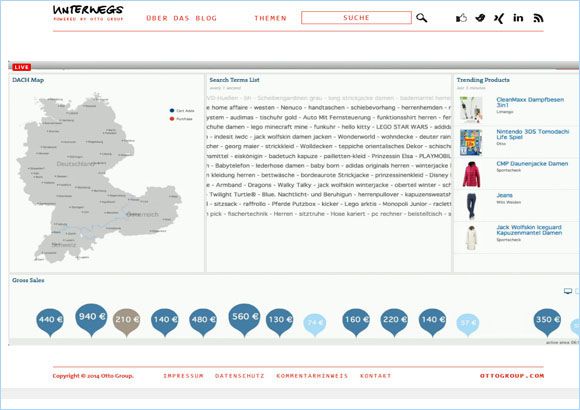
Most eligible frameworks require a programmatic description and deployment of data provisioning topologies which corresponds to a procedure unsuitable for the described use case. The dashboard instances are being set up by people with less technical background and mostly at very short notice. Additionally, a short-term topology modification is required to combine or extend existing processing pipelines to save resources. As a market research could not identify a suitable solution, the department decided to implement its own stream processing framework with a clean focus on support for no-code topology deployments and ad hoc modification: SPQR (spooker).
Technically speaking, the SPQR framework follows a distributed computing approach where work is equally distributed among clustered processing nodes. A processing topology referred to as pipeline in the SPQR context is described as directed graph between single operators. Compared to other frameworks (like Spark, Samza or Flink) SPQR separates code deployments from pipeline deployments. Thus it requires library distribution before an enclosed operator may be referenced by a later published pipeline description. The operator library is kept persistently in a node-local repository which supports different library versions. 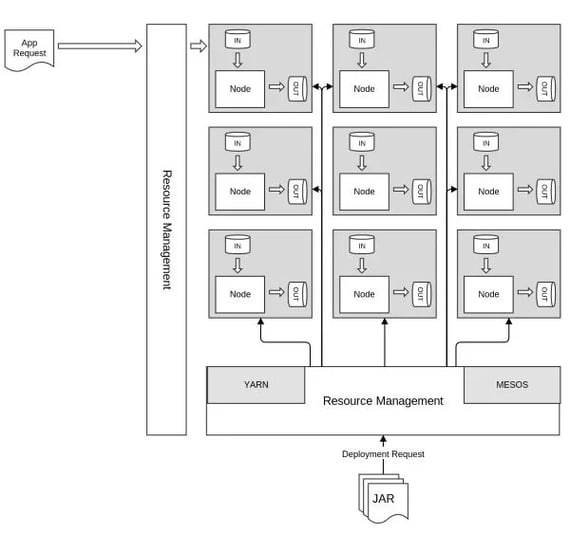
Having worked on SPQR for more than a year we decided to take stock and analyze the progress we have made so far. We evaluated our approach against a set of frameworks which turned up or made significant progress in the meantime. Knowing that most frameworks have done their homework, we focused on those features that we identified as unique selling points for SPQR most notably the ad hoc pipeline deployment and modification (an in-depth presentation on our findings is given by Alexander Kolb at Flink Forward 2015: Flink? Yet another streaming framework?). During the evaluation process we examined four different frameworks: Apache Spark, Apache Flink™, pulsar.io and SQLStream.
It turned out that Apache Flink™ is closest to SPQR in terms of how it understands and implements stream processing. Streams are treated as what they are: a sequence of events instead of a notably small batch. Some of the evaluation aspects we focused on were the following:
-
Learning Curve: How steep is the learning curve for inexperienced developers to implement and deploy a simple application?
-
Latency & Throughput: How do latency and throughput behave in a very simple use case? What kind of options are available to influence either one?
-
Missing Features & Time To Add Functionality: Does the framework lack any important features and how easily may missing features be added?
-
DSL/DDL/UI For Creating Pipelines: Are DSL, DDL, or a user-interface provided to describe and deploy processing pipelines?
-
Project Documentation & Community: How well-documented is the framework and how large is the associated community?
-
Testing Framework: Is testing supported on unit level as well as on integration test level? What kind of tools are available?
-
Hot Deployment & Pipeline Redeployment/Reconfiguration During Runtime: Does the framework provide support for hot deployments (no-code deployments) and pipeline reconfiguration during runtime?
-
Monitoring & Ops Support (e.g. Monitoring UI, Metrics Export): What kind of features are provided by the framework to support runtime monitoring? Are any user interfaces available? Does the framework provide metric export using standard formats?
-
Size & Quality Of Operator Library: How many operators (e.g. join, group, filter) are available and what is the quality of their implementation (ease of use)?
-
Support For External System Connectors (Kafka, JMS, HDFS, Kafka, JDBC): How are external sources and sinks supported? Do connectors exists for most common systems, e.g., Apache Kafka, JMS, HDFS, JDBC?
-
Cluster Deployment & Operations Support: How well established are cluster deployments and cluster operations tools?
-
Scalability: Does the framework provide automated scaling?
-
Resilience & Fault Tolerance: How are fault tolerance and resilience supported by the framework?
-
Message Order & Delivery Guarantees: What type of message ordering and delivery guarantees are supported (at least once, exactly once)?
-
State Management: How is state managed inside applications and in case of crash recovery?
-
Licensing Model: Which licensing model does the framework follow?
-
Professional Support: Is professional support available (ad hoc bug-fixing as well as consulting)? Although Apache Flink™ lacked and still lacks support for ad hoc topology deployment and reconfiguration, it fills the gap we previously identified for SPQR turning it into a full-featured stream processing framework: hardened cluster support, a rich operator set, and an active community. Being still convinced that ad hoc'ness is a crucial feature for turning a stream processing framework into a first-class citizen within the enterprise datahub market, we finally decided to go with Apache Flink™ to receive a full-featured stream processing framework but put our efforts into leading over findings from SPQR regarding ad hoc'ness. Until now a whole range of exciting projects at the Otto Group BI department were implemented with Apache Flink™, e.g. a crowd-sourced user-agent identification, and a search session identifier.
To learn more about them, attend the talks given by Christian Kreutzfeldt and Alexander Kolb at FlinkForward 2015: Static vs Dynamic Stream Processing (Christian Kreutzfeldt), Flink? Yet Another Streaming Framework? (Alexander Kolb).

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
