













Overview
The Apache Flink community introduced the Hybrid Shuffle Mode[1] in 1.16, which combines traditional Batch Shuffle with Pipelined Shuffle from stream processing to give Flink batch processing more powerful capabilities. The core idea of Hybrid Shuffle is to break scheduling constraints and decide whether downstream tasks need to be scheduled based on the availability of resources, while supporting in-memory data exchange without spilling to disk when conditions permit.
In order to fully understand the potential of Hybrid Shuffle, we evaluated it in multiple scenarios based on Flink 1.17. This article will analyze the advantages of Hybrid Shuffle in detail based on the evaluation results, and provide some tuning guides based on our experiences.
Advantages of Hybrid Shuffle
Compared to traditional Batch Blocking Shuffle, Hybrid Shuffle mainly has the following advantages:
- Flexible Scheduling: Hybrid Shuffle overturns the prerequisite that all tasks have to be simultaneously scheduled in Pipelined Shuffle Mode, or must be scheduled stage-by-stage in Blocking Shuffle Mode:
- When resources are sufficient, upstream and downstream tasks can run simultaneously.
- When resources are insufficient, upstream and downstream tasks can be executed in batches.
- Reduced IO Overhead: Hybrid Shuffle breaks the constraint that all data of batch jobs must be written to and consumed from disk. When upstream and downstream tasks run simultaneously, it supports directly consuming data from memory, which significantly reduces the additional overhead of disk IO while improving job performance.
These unique advantages equip Hybrid Shuffle with capabilities that traditional Blocking Shuffle lacks. To validate its effectiveness, we undertook a series of experiments and analyses, which are categorically divided into the following key aspects.
Fill Resource Gaps
Resource gap refers to some idle task slots at certain time points during job execution, meaning that cluster resources are not being fully utilized. This can occur in the Flink Blocking Shuffle, and is particularly significant in scenarios where data skew exists in some tasks.
The following figure compares Blocking Shuffle with Hybrid Shuffle. It can be seen that two task slots in Blocking Shuffle cannot be used, while all three slots in Hybrid Shuffle are in use.
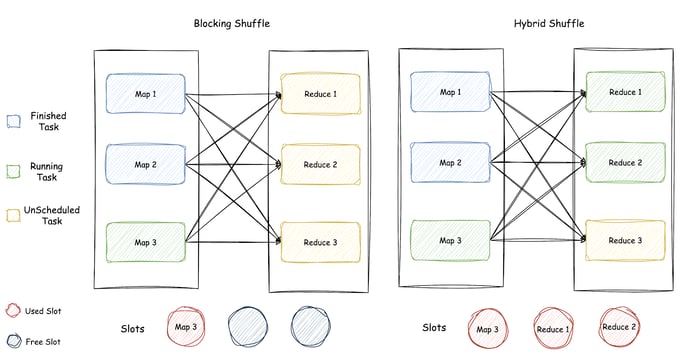
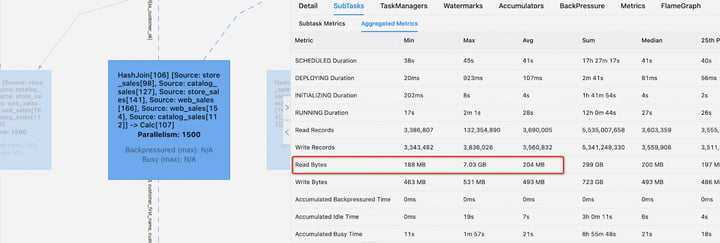
Data skew is a widespread phenomenon. Taking TPC-DS q4 as an example, one HashJoin operator reads an average of 204 MB of data, while one skewed task reads as much as 7.03 GB of data. Testing found that Hybrid Shuffle reduced the total execution time of this query by 18.74% compared to Blocking Shuffle.
Reduce Disk Load
Flink Blocking Shuffle writes all intermediate data to disk. As a result, shuffle writing and shuffle reading phases perform disk write and read operations, respectively. This brings two main problems:
- The disk IO load increases, affecting the throughput of the entire cluster. As the number of jobs on the cluster increases, disk IO will become the bottleneck.
- Shuffle data of large-scale batch jobs can occupy a considerable amount of disk storage space, and the size is difficult to estimate. This problem is more prominent in cloud-native environments represented by Kubernetes: if the configured value is too small, there will be insufficient storage space; if the configured value is too large, it will waste storage resources because resources are in most cases isolated at the pod level.
Hybrid Shuffle introduces two strategies for data spilling:
- Selective spilling strategy: It only spills a portion of the data to disk when there is not enough memory space. This strategy can reduce disk read and write instructions at the same time.
- Full spilling strategy: All intermediate data are written to disk, but downstream tasks can consume unreleased data directly from memory. This strategy can effectively reduce disk read instructions while also improving fault tolerance.
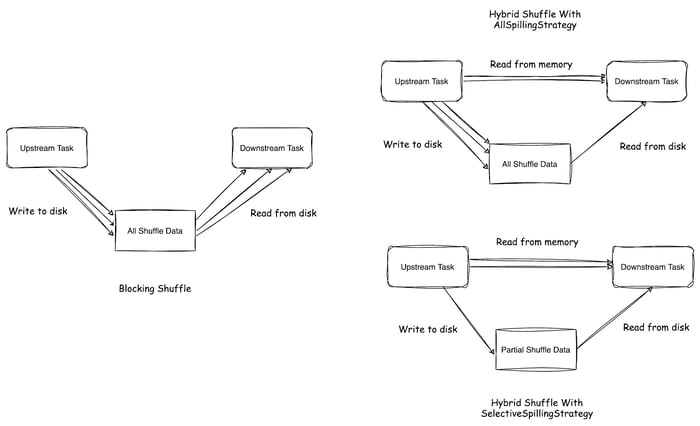
To compare the impacts of different shuffle modes and spilling strategies on disk IO load, we conducted the following experiments:
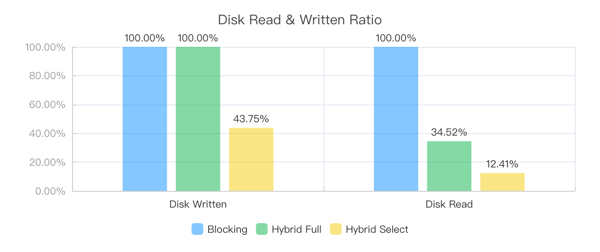
- Testing the proportion of data read from and written to disk compared to the total data under different shuffle modes and spilling strategies:
- Testing the proportion of data read from and written to disk compared to total data under different network memory sizes in the Hybrid Shuffle selective spilling strategy:
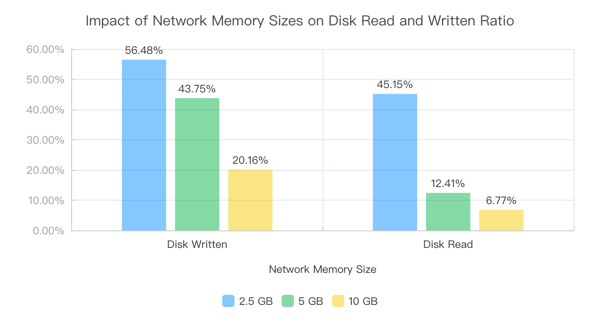
From the experimental results, we can see that:
- Compared to Blocking Shuffle, Hybrid Shuffle greatly reduces the amount of data read from and written to disk.
- Compared to the full spilling strategy, selective strategy can significantly reduce the amount of data written to disk.
- As the network memory increases, the proportion of data directly read from memory by Hybrid Shuffle gradually increases.
We can also observe two interesting phenomena:
- For selective spilling strategy, the amount of data read from disk is less than the amount of data written. This indicates that many disk write operations are unnecessary under this strategy because some data is directly consumed from memory during the writing process, suggesting that further optimizations are possible.
- The amount of data read from disk is not consistent between these two strategies. Selective spilling strategy reduces disk write operations, which also reduces IO load and makes disk read faster. The downstream consumption progress is more likely to catch up with the upstream production progress, thereby making it more likely to read data from memory.
Tuning Guides for Hybrid Shuffle
Based on the above analysis and experimental results, we have summarized the following three tuning guides for the use of Hybrid Shuffle:
Reduce the Parallelism of Operators
Operator parallelism significantly affects the performance of Flink jobs. For batch jobs that use Blocking Shuffle, the parallelism is generally set to a larger value to achieve better distributed execution capabilities.
However, in Hybrid Shuffle mode, with its ability to schedule downstream tasks in advance, reducing the parallelism of operators can allow more stages to run simultaneously. This reduces the amount of data written to disk and achieves better performance for the same total resource usage.
This is confirmed by testing Hybrid Shuffle and Blocking Shuffle with different operator parallelism values (500, 750, 1000, 1500, 2000) on the TPC-DS dataset with fixed total resources (slots). The test results, measured by the total execution time, are as follows:
|
Total Number of Slots |
Optimal Parallelism for Hybrid Shuffle |
Optimal Parallelism for Blocking Shuffle |
|
1000 Slot |
500 |
1000 |
|
1500 Slot |
500 |
1500 |
|
2000 Slot |
750 |
2000 |
Hybrid Shuffle achieves optimal performance at a relatively small parallelism, while Blocking Shuffle achieves optimal performance at a parallelism value consistent with the total number of slots. This is because Hybrid Shuffle can reduce parallelism to achieve better parallel execution, while for Blocking Shuffle if parallelism is set too low, there may be idle resources that cannot be utilized.
It is also important to note that although Hybrid Shuffle has the best overall execution time at lower parallelism values, we have also found that some queries have better performance only with higher parallelism values. This is because these queries have a few operators with heavy computation logic, which become the bottleneck of the entire job when the parallelism is too low.
Taking TPC-DS q93.sql as an example, its topology is as follows:
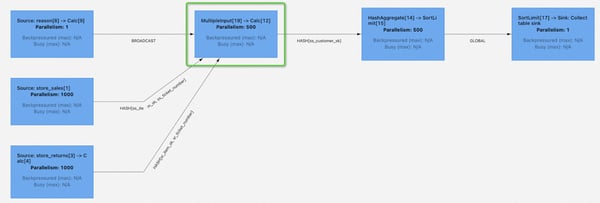
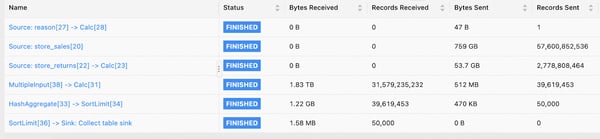
The MultipleInput → Calc node in the green box is the bottleneck of the entire job. Through sampling analysis, we found that it processes a much larger amount of data than other operators, and it processes each data record relatively slowly. Even if downstream tasks have all been scheduled, this bottleneck node still needs to be waited for. Once this node is finished, the entire job will end immediately.
For a topology consisting of n stages in series, let T hi and T li denote the execution time of the i t h stage at high parallelism (when upstream and downstream cannot run simultaneously) and low parallelism (when upstream and downstream can run simultaneously), respectively. Then the total execution time under the two parallelism settings is:
∑ni=1T hi (1)
Max(T l1, T l2 ... T ln) (2)
Note: To simplify the explanation, we only consider the cases where multiple stages run simultaneously or sequentially, without considering the situations where a stage partially finishes and another stage starts.
Reducing parallelism essentially makes the stage run slower (T li is greater than T hi) while enabling it to run simultaneously. If the upstream stage runs much slower than the downstream stage, then reducing parallelism will increase the time spent on the upstream stage, while the downstream stage does not need to start running so early, resulting in more loss than gain.
Returning to the above query: MultipleInput → Calc is the bottleneck of the entire job. Let T hM and T lM denote the execution time of this stage at high and low parallelism, respectively. Then the result of (1) depends primarily on T kM , while the result of (2) equals T lM. The performance loss caused by reducing parallelism (T hM - T lM)is relatively large, resulting in longer job execution time. When we increase the default parallelism of this job from 500 to 1500, the job performance is significantly improved, and the total execution time is reduced by 47%. Therefore, in Hybrid Shuffle mode, reducing the parallelism of operators is not always better.
Increase the Size of Network Memory
The size of network memory has a significant impact on the performance of Flink shuffle stage. If this part of memory is insufficient, the competition for network buffers will become intense, leading to backpressure in the job.
Avoid Insufficient Network Memory Exception
Hybrid Shuffle requires more network memory than Blocking Shuffle. The main reason is that the current implementation of Hybrid Shuffle does not decouple the network memory requirements from the parallelism of tasks. One of the key focuses of the community's work in Hybrid Shuffle is to improve this.
The minimum network memory requirements for the Shuffle Write and Shuffle Read stages for both shuffle modes are shown in simplified form in the following table:
|
Shuffle Mode |
Minimum Network Memory Requirement for Shuffle Write Phase |
Minimum Network Memory Requirement for Shuffle Read Phase |
|
Hybrid Shuffle |
Downstream Parallelism * 32 KB + 1 |
2 * Upstream Parallelism * 32 KB |
|
Blocking Shuffle |
512 * 32 KB |
1000 * 32 KB |
From the table, we can see that:
- The network memory requirements of Blocking Shuffle are not related to parallelism, so increasing job parallelism does not impact the size of the network memory.
- The network memory requirements of Hybrid Shuffle are basically linearly related to parallelism. As parallelism increases, it may cause the total network memory to be insufficient to meet the minimum requirements for job execution, resulting in an "Insufficient Network Memory" error. When increasing job parallelism, the network memory also needs to be adjusted accordingly.
Increase the Proportion of Data Read from Memory
For Blocking Shuffle, data can be released after spilling and can only be consumed from disk. Therefore, the memory in the network layer only needs to ensure that there is no intense buffer competition. Even given more resources, the performance can hardly improve further. However, in Hybrid Shuffle mode, increasing the memory in the network layer can improve the chance of reading data from memory. This is because Hybrid Shuffle's data eviction strategy considers the usage rate of the memory pool. The more memory is available, the longer data can stay in memory, making it more likely to be directly consumed without touching the disk, thereby reducing the IO overhead.
To study the effect of network memory size on different shuffle implementations, we tested on the TPC-DS 10T dataset. Using a baseline of 24GB total taskmanager memory and 2.5GB network memory, we increased the total taskmanager memory and network memory (with each additional 1GB of network memory causing a corresponding increase of 1GB in total taskmanager memory). The performance improvement relative to the baseline is shown in the following figure:
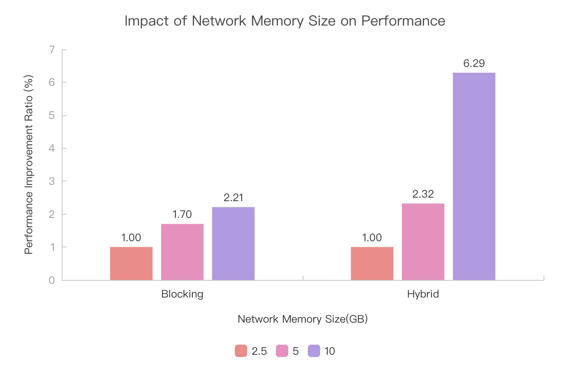
From the experimental results, it can be seen that with the increase of network memory size, the performance of both shuffle modes has improved. The proportion of improvement in Blocking Shuffle is not very significant, while Hybrid Shuffle is more sensitive.
Avoid Using Hybrid Shuffle and Dynamic Parallelism together
Flink supports dynamically setting the parallelism of batch jobs at runtime. The principle behind this is to schedule the job stage by stage, and infer the parallelism of downstream stages based on statistical information (primarily the amount of data produced) from upstream finished stages.
The dynamic parallelism mode has a natural constraint on scheduling: downstream stages can only be scheduled after upstream stages have finished. Hybrid Shuffle can support this mode, but this also means that the advantage of Hybrid Shuffle in scheduling cannot be fully utilized.
To verify the performance of the two shuffle modes under dynamic and non-dynamic parallelism modes, we tested Blocking Shuffle and Hybrid Shuffle on the TPC-DS dataset, with the default parallelism (parallelism.default) set to 1500. The experimental results are shown in the figure.
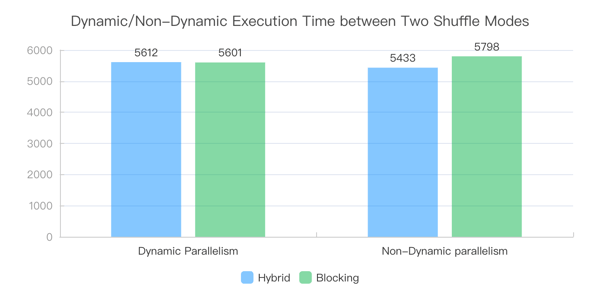
It can be seen that Hybrid Shuffle has little difference in total execution time compared to Blocking Shuffle under dynamic parallelism mode, and the performance is basically the same. At the same time, its non-dynamic parallelism mode has certain performance advantages compared to dynamic parallelism. This is mainly because Hybrid Shuffle can schedule downstream tasks early after some upstream tasks are finished in this mode. On the other hand, the dynamic parallelism mode of Blocking Shuffle has better performance than its non-dynamic parallelism mode, which is due to the reduction of additional overhead in scheduling and deployment for tasks with small amounts of data.
Conclusion
In this article, we primarily investigated the factors contributing to the superior performance of Hybrid Shuffle. Our study included a comprehensive experimental evaluation and analysis of these factors. Furthermore, we presented corresponding optimization guidelines for enhanced utility:
- Reduce the parallelism of operators, generally adjust to allow 2-3 stages to be parallel.
- Increase the size of network memory.
- Avoid using Hybrid Shuffle and dynamic parallelism together.
You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
