













This post originally appeared on the Bird Engineering account on Medium. It was reproduced here with permission from the author.
Detecting Offline Scooters with Stream Processing
Some of the most interesting challenges at Bird involve dealing with dockless physical hardware. Not only can scooter hardware fail, scooters can be stolen or vandalized by bad actors. We collect telemetry data from the scooters, but analyzing this firehose of data can be challenging.
Stream processing is a natural fit for extracting insights from this telemetry data. We use Flink for processing the data from Kafka (our message bus), running jobs that look for different signals in the data. Flink provides built-in tools for simplifying reading from Kafka and processing streams in a fault-tolerant, distributed manner. Flink also provides a lot of built-in processing functionality, as well as various building blocks for custom logic.
As a business, Bird needs to track the health of our hardware. One symptom of an unhealthy scooter is when it stops sending telemetry records. Scooters going offline could be due to a battery issue, a software issue, or a hardware issue. We need to know when this happens, so we can follow up as quickly as possible.
We wrote a Flink job to detect when scooters go offline, and quickly ran into a set of tricky problems involving Kafka, event time, watermarks, and ordering.
The Flink Approach
Bird refers to each telemetry record that a scooter sends us as a track. We use a Flink job to record the timestamp of each track for a given scooter, and set a timer to fire after a certain amount of time has passed. If we see another track before the timer fires, we reset the timer to reflect this new track’s timestamp. If we do not see another track, the timer fires and we output an event reflecting that this scooter has gone offline.
Telemetry monitoring was a natural fit for a keyed process function, and Flink made it straightforward to get this job up and running. The process function kept keyed state on scooter ID to track the current online/offline status, and event time timers to handle the offline detection. We chose this route since we wanted to do more complicated things with tracks later, and wanted to practice with process functions, instead of just using a session window.
Seems simple enough. But we hit a snag when we tested how this job performed against older data. When replaying older data from Kafka, the job output both false positives (it detected spurious offline events) and false negatives (it missed some real offline events).
Investigating the problem got pretty complicated, and the fix we landed on surfaced some interesting takeaways that we’ve been able to apply to other jobs as well. We learned that it’s critical to understand:
-
why ordering is unreliable in a backfill,
-
how to properly extract your timestamps and watermarks using Kafka, and
-
how timers and processElement interact.
Backfills and Data Ordering from Kafka
Let’s start with ordering. We have a Kafka topic with several partitions, with no specific partition keys. We found that, during a backfill, jobs often do not read these partitions at the same rate. We’d end up with a logical Flink stream with records wildly out of order—by hours or more! Consider the diagram below:
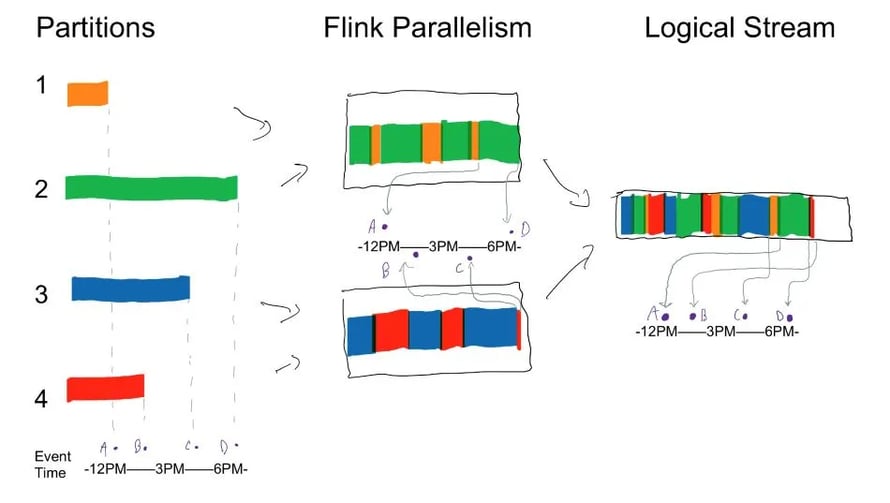
This illustration represents a snapshot in time from a job reading 6+ hours worth of data from a Kafka topic with four partitions. The job has a parallelism level of two, so each task instance is reading from two partitions. Due to network conditions and other differences between each instance-to-broker connection, we’re getting records back at wildly different rates (e.g. records from 3PM come after records from 6PM, and so on).
Watermarks
The first thing that we found was that we weren’t extracting our watermarks correctly. Flink’s watermarks are the primary building block for solving these issues, so we had to fix this first. They act as a logical clock that tells every operator in the job how far along in time we are. More can be read here, in the Flink documentation. Fortunately, this was a simple problem - but until we saw this out of order data and started investigating how to fix it, we had missed the full significance of the bit in the documentation here about extracting watermarks per partition.
Our watermark extractor is a fairly basic implementation of BoundedOutOfOrdernessTimestampExtractor. We provide a function for extracting a timestamp from a record, and the library code generates our watermarks by subtracting five seconds from our current max timestamp we’ve seen. This works well if the timestamp of each record is at most five seconds behind the current max timestamp. Records further behind are considered late, and we discarded them. But in our testing, reading the topic live in real-time, we didn’t see any late records.
Given different source partition read rates, the watermark needs to advance at the rate of the slowest partition when reading from Kafka. But we saw a lot of records coming in behind the watermark. We realized we were generating our watermarks after attaching our Kafka sources to the streaming execution environment, not before. So, in the diagram above, we were generating our watermarks at the “Flink Parallelism” level. We were grabbing records out of the combined stream of partitions 1 and 2, and using those as our new watermark candidates. Because watermarks can’t move backwards, this meant that the watermark was only being advanced by the faster partition, partition 2, so it ended up at point (D). For our other task instance, it was similarly being advanced by partition 3, so it ended up at point (C). When combining these two, Flink takes the minimum of the subtask watermarks - point (C) - but this is around 5PM, hours ahead of the watermarks for partitions 1 and 4 should have been.
By properly moving our watermark extraction into the Kafka source, as in the link above, we got correct watermarks. In the example above, our watermark ended up at point (A) instead of point (C) after this change.
Fixing the watermarks stopped our timers from frequently firing early during a backfill. It also stopped us from incorrectly dropping data as “late arriving” when the data was seen behind the watermark. This fix eliminated a lot of false positive offline events.
So far, so good, but moving the watermark extraction wasn’t a complete solution to our ordering issues. We still had issues with sequential logic looking at out of order data, which could give us false negatives. If we jumped from seeing tracks for a scooter for 1PM to a track from 3PM, we’d lose our ability to detect any offline periods that might’ve happened in the two hours in between.
At this point we revisited a couple of our underlying decisions. We could take a different approach entirely - using a session window instead of a process function would leverage more built-in logic for dealing with these ordering issues, but this issue affected some of our more complicated jobs too, so we really wanted to get our process function usage right.
We also looked at our Kafka setup. For this simple case, with a job that only reads one topic, using scooter ID as a Kafka partition key could’ve preserved ordering by scooter, but it doesn’t offer a good general solution - some jobs may want ordering by different dimensions against the same data (by scooter vs by user, say), and joining streams also presents the same fundamental problem. So we wanted to understand how to deal with this behavior more directly in Flink.
First Attempt: Event Time Window As Buffers for Ordering
Our first thought was to use event time windows to fix the out of order data. Since these windows are Flink built-ins, we thought they might be an easy way to ensure ordering for a downstream process function without having to change our usage of process function for sequential logic. We figured that if we added very short event time windows right before the function, that data would be passed on in order.
Some tests bore this approach out, but when we deployed buffering using event time windows for the offline job, we hit an unexpected snag! When backfilling data, we still saw about 10% fewer offline events generated compared to when processing live data. This implementation was far better than what we had before, but it still wasn’t 100% there.
We found a big clue when we looked at some of the periods we missed. We saw a case where we’d detected a scooter being offline for 30 minutes, then marked it back as online 7 seconds later. Somehow that second track that was 30 minutes and 7 seconds after the previous track had caused our event time timer (set for 30 minutes after the first track) to not fire.
Consider the following sequence of tracks for a single scooter, and the corresponding 30-minute-later timers we want to set:
| Time | 30 Minutes Later |
| 17:30:15 | 18:00:15 |
| 17:30:20 | 18:00:20 |
| 17:30:25 | 18:00:25 |
| 18:00:32 | 18:30:32 |
Flink’s KeyedProcessFunction abstract class provides us with processElement and onTimer stubs to override. Every time we see a track for a scooter in processElement, we set an event-time timer to fire 30 minutes later. This timer is continually getting pushed back as we see more tracks. If we go 30 minutes without a track, onTimer is called when the timer fires, and we generate an offline event. If we see a subsequent track in processElement, we generate an online event.
From the above tracks, we’d expect this to identify online (blue) and offline (pink) periods like so:

The tracks at 17:30:15, 17:30:20, and 17:30:25 would each push the timeout back to 18:00:15, 18:00:20, and 18:00:25, successively. Since we don’t see any more tracks before 18:00:25, we’d fire an offline event at 18:00:25. We’d then fire an online event at 18:00:32 when we received that track.
We saw this work as expected with live data, but that offline event at 18:00:25 was sometimes - but not always - missed in a backfill.
Timers and Event Time vs Processing Time
We ultimately discovered that, even though we thought we were doing everything based on event time, this problem was due to mixing processing time and event time semantics. This was a combination of two things:
-
We were using periodic watermark extraction. Every so often (200ms by default) we looked at a record’s timestamp in order to update our watermark. This approach didn’t cause issues in real-time, but in a backfill it caused randomness. In a backfill, we’re reading records much faster than real time, so far more event time passes in between extracted watermarks. This elevated read rate means that many more records are read in between 200ms intervals, and where the watermarks fall with respect to event time is much less deterministic.
-
Event timers only fire on watermark advancement. The non-determinism of watermark extraction meant that when running a backfill multiple times, event timers would fire at different points relative to records that had run through processElement. The rapid movement of event time in a backfill scenario meant that this could cause dramatic differences.
Offline job backfills, then, would sometimes read that record with timestamp at 18:00:32 before extracting a watermark for a time later than 18:00:25. When that happened, we immediately pushed the event time timer to 18:30:32, so we never generated the offline/online pairs we expected to see.
Each similar situation had some chance of being incorrect in a backfill. As a result, our backfills disagreed with each other as well as with our real-time processing. So the challenge was to figure out how to synchronize watermark-driven timer behavior with the immediate nature of processElement.
We had two thoughts. The first (and easiest approach to test) was to generate watermarks from every record, instead of only periodically. In Flink terminology, we accomplished this with an implementation of AssignerWithPunctuatedWatermarks instead of an implementation of AssignerWithPeriodicWatermarks. And indeed, this got rid of the problem.
However, this approach had a lot of processing overhead, and high component coupling. We now needed the heavier every-record watermark extractor, plus we needed to include the buffering event time windows, plus the process function itself.
Let’s also think once more about expected out of orderness in the stream. We mentioned earlier that here we don’t expect a lot. Our telemetry data is fairly well-ordered in each partition, and we only have a 5 second delay in our watermark extractor, so we hadn’t really noticed this in our live data. However, it could still happen, especially if we were dealing with more out of order data and used a higher delay in our watermark extraction. (This is another place where a keyed topic would not be sufficient on its own.)
The Solution
Instead, we decided to embed the buffering in the process function, and do asynchronous buffered processing of each element. This turned out to be a relatively simply change!
Our processElement function now
-
Puts each incoming track record in a map keyed by its timestamp, and
-
creates an event timer to process that record once the watermark hits that point.
When the watermark advances, all the timers fire in order. The timer for 18:00:25 fires before the buffered track for 18:00:32.
In our onTimer callback, we check two things:
-
if this timestamp has a buffered track: we run the track through a new handleTrack function that contains the logic previously performed by processElement
-
if this timer matches our current timeout: we execute the logic we had directly in onTimer previously
By embedding the buffering in the process function, we were able to use event time to synchronize our handling of both records and timers.
We were able to verify that this buffered-records process function solution resulted in deterministic output, for both the Offline Birds job and also our other jobs that used process functions! We were able to generalize this fix into a BufferedKeyedProcessFunction abstract class on top of KeyedProcessFunction, so we could share the fix with the other jobs that need it.
One downside is that this buffering can end up using a lot of memory and cause large checkpoints while it’s going on, as the partition read rates can vary wildly. But fortunately, this is something the Flink community is working on, with read-time alignment of sources with parallel partitions!
Flink proved a great solution for whipping up streaming logic to handle these cases, but we had to get pretty deep into the weeds around how time is handled to get to the root of the backfill problems. Now that we understand the problem, we’ve applied the BufferedKeyedProcessFunction successfully to multiple jobs. We hope that by sharing our experiences and learning operating Flink in production for some critical applications will help others understand how ordering, watermarks, and process functions all interact!
You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
