













We are excited to announce the general availability of data Artisans Streaming Ledger, an exciting new technology that brings serializable ACID transactions to applications built on a streaming architecture.
In this post, we will explain why serializable ACID transactions are an extremely hard problem for modern enterprises, how Ververica came to a solution and how you can use the technology for your stream processing applications.
The next evolutionary step in stream processing
At Ververica, we have witnessed the growth of data stream processing from its nascent days to a rapidly growing market that is projected to reach almost $50 billion by 2025. Since the very creation of Apache Flink, we have always held the strong belief that stream processing is a technology that will power the most mission-critical software applications in the enterprise, applications that we now see being deployed every day in our customers.
As stream processing is being adopted in more and more industries and powers more and more mission-critical applications, the technology itself evolves to offer increasingly better guarantees for data and computation correctness.
Step 1: Distributed stream processing for data analytics (“at least once guarantees”)
The first distributed stream processors that entered the mainstream targeted analytical applications, and in particular offered a way to analyze data in an imprecise manner, in real time while the precise analysis was taking place in the background. This was referred to, at the day, as the “lambda architecture” wherein a stream processor offered imprecise results while the data arrived, and a batch processor offered the correct answer in hourly or daily batches. This kind of guarantees are called “at least once processing” in stream processing nomenclature. They are the weakest possible correctness guarantees offered by stream processing systems and were the initial step in the stream processing technology journey.
Step 2: Distributed stream processing for single-key applications (“exactly once guarantees”)
Apache Flink pioneered the adoption of true stateful stream processing with exactly once guarantees at scale. This allowed a particular class of applications, both analytical and transactional in nature, to be implemented using stream processing technology with strong correctness guarantees. This fully alleviated the need for the lambda architecture and batch processors for a particular class of applications.
The catch in the above has always been the “particular class of applications”. Today, many stream processors available in the market offer strong consistency guarantees but only for applications that update a single key at a time. This means, for example, that an application that updates the balance of a single bank account can be implemented correctly with stream processing today, but an application that transfers money from one bank account to another is hard to implement with strong consistency guarantees.
Step 3: Distributed stream processing for general applications (“ACID guarantees”)
With the introduction of Streaming Ledger as part of Ververica Platform, users of stream processing technology can now build applications that read and update multiple rows and multiple tables with ACID guarantees, the strongest guarantees provided by most (but not all) relational databases.
And Streaming Ledger provides these guarantees while maintaining the full scale-out capabilities of exactly once stream processing, and without affecting the application’s speed, performance, scalability, or availability.
A good (but not 100% accurate) analogue in database systems might be to think of at least once guarantees in a Lambda architecture as a form of eventual consistency (eventually the batch system would catch up). Exactly once guarantees as offered by Flink are akin to distributed key/value stores that offer consistency for single-key operations, and the guarantees that the Streaming Ledger provides are akin to ACID guarantees that relational databases provide for more generalized transactions that operate on multiple keys and tables.
We believe that this is the next evolutionary step in stream processing that opens the door for a much wider set of applications to be implemented in a correct, scalable, and flexible manner using the streaming architecture.
An Introduction to Multi-Key, Multi-Table Transactions
Many relational database management systems (RDBMSs) perform ACID transactions so that each transaction modifies tables with ACID semantics under isolation level serializable for full data consistency. With ACID semantics all transactions are Atomic, Consistent, Isolated, and Durable. ACID semantics are crucial in high-transaction speed industries like financial services or e-commerce.
Let’s use the classic example of a table with account balances and money transactions from one account to another. To ensure transactional correctness, the transfer must change either both accounts or none (atomicity), it should only happen if the source account has sufficient funds (consistency), and no other operation may accidentally interfere and cause incorrect result (isolation, no anomalies). Violation of any of these aspects causes money to be lost or created and accounts to have an incorrect balance.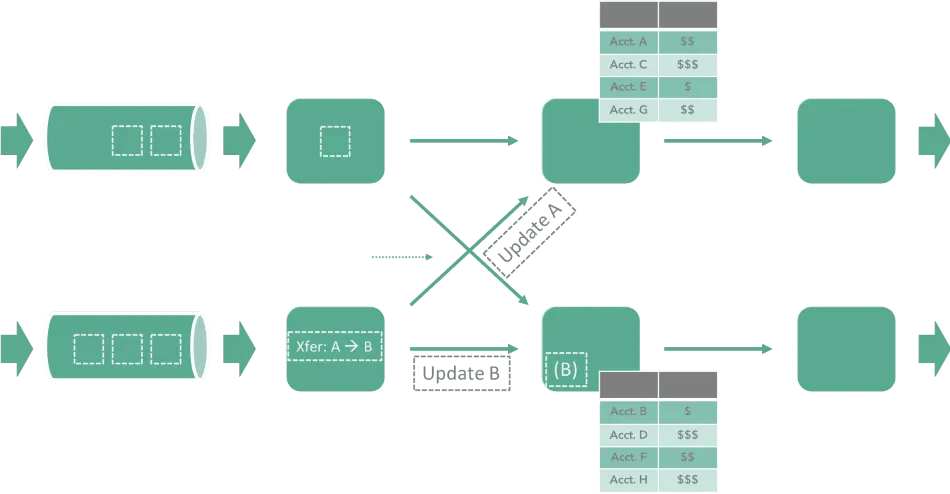
Implementing this example in a stateful stream processor can be shown in the diagram above. The used key, in this case, is the account ID and the two involved accounts are located in different shards. Neither of the shards has access or a consistent view on the other shard’s status, that makes the implementation of such a framework rather complex since one needs to communicate the status between both shards in a way that:
1. Gives a consistent view on state
2. Is able to manage concurrent modifications and
3. Ensure atomicity of changes
Going beyond the exactly once semantics of stream processing frameworks
Ververica Streaming Ledger builds on Apache Flink and provides the ability to perform serializable transactions from multiple streams across shared tables and multiple rows of each table. This can be easily considered as the data streaming equivalent of multi-row transactions on a key/value store or even across multiple key/value stores. Streaming Ledger uses Flink’s state to store tables so that no additional storage or system configuration is necessary. The building blocks of Streaming Ledger applications consist of tables, transaction event streams, transaction functions and optional result streams.
Ververica Streaming Ledger opens the path to implement using stream processing for a completely new class of applications that previously relied on relational database management systems. Data-intensive, real time applications such as fraud detection, machine learning, and real time trade pricing can now be upgraded to the streaming era effortlessly. In the following section, we will guide you through the necessary steps to start developing with Ververica Streaming Ledger using an example use case.
A use case for Ververica Streaming Ledger
Ververica Streaming Ledger fits perfectly with use cases that work with multiple states. The technology enables the transactional modification of multiple states as a result of streaming events. These modifications are isolated from each other and follow serializable consistency.
As an example use case, let us assume a real-time application that looks for patterns in wiring money and assets between account and ledger entries.
In this example, the application will maintain two tables as Flink state: the first one named “Accounts” and the second named “Asset Ledger”. The application consumes streams of transaction events such as transfers between accounts, ledger entries or both. When an event comes in, different transaction types are applied for each event type that then access the relevant rows, check the preconditions, and decide whether to process or reject the transfer. In the former case, it updates the respective rows in the tables. In both cases, the transaction function may optionally produce result events that indicate whether the transfer was accepted or rejected. An illustration of such architecture is displayed in the following diagram:
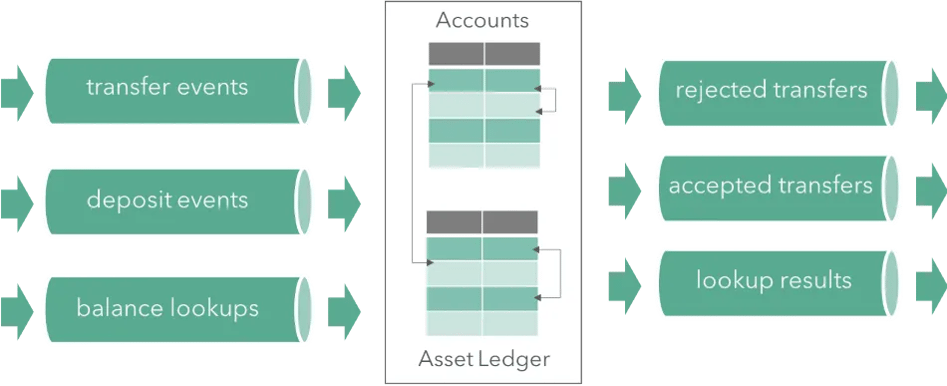
The Streaming Ledger exposes an easy-to-use API that feels natural to both users that have previous stream processing experience, and the ones familiar with relational database management systems. For our use case we use the following assumptions:
-
There are two tables: Accounts and Asset Ledger
-
We have three streams of events: Deposits, Transfers and Balance Lookups
-
Deposits put values into Accounts and the Asset Ledger
-
Transfers atomically move values between accounts and Asset Ledger entries, under a precondition.
In the following, we will walk through the implementation of this use case using the Streaming Ledger API. The API of the Ledger is open source and also contains a serial (single node) implementation, which you can find here.
Here’s how you can establish your event sources by creating a Flink DataStream program:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<DepositEvent> deposits = env.addSource(…);
DataStream<TransferEvent> transfers = env.addSource(…);
And this is how you can define the scope and tables of your programme:
// define the transactional scope
TransactionalStreams txStreams =
TransactionalStreams.create(“simple example”);
// define the transactional tables
TransactionalStreams.State<String, Long> accounts = txStreams.declareState(“accounts”)
.withKeyType(String.class)
.withValueType(Long.class);
TransactionalStreams.State<String, Long> asset ledger =
txStreams.declareState(“AssetLedger”)
.withKeyType(String.class)
.withValueType(Long.class);
Next, you can specify which transaction function to apply to each stream, and for each table that will be used, how to select the keys for the rows that will be accessed.
The ‘.apply(…)’ functions themselves contain the transactions’ business logic.
For each row being accessed, you add a call that specifies the access ‘.on(table, key, name, type)’:
-
‘table’ indicates the table that is accessed
-
‘key’ is a function through which the key for that row is derived from the input event
-
‘name’ is a logical name for that particular row (used later)
‘type’ qualifies read-only, write-only, or read-write access to the row. This is an optimization, where READ_WRITE is the most generic option.
// define the deposits transaction
txStreams.usingStream(deposits, “deposits”)
.apply(new DepositsFunction())
.on(accounts, DepositEvent::getAccountId, “account”, READ_WRITE)
.on(assetledger,DepositEvent::getassetledgerEntryId, “asset”, READ_WRITE);
// define the transfes that update always four rows on different keys.
// store a handle to the result stream for later use.
OutputTag<TransferResult> result = txStreams.usingStream(transfers, “transfers”)
.apply(new TransferFunction())
.on(accounts, TransferEvent::getSourceAccountId, “source-account”, READ_WRITE)
.on(accounts, TransferEvent::getTargetAccountId, “target-account”, READ_WRITE)
.on(assetledger, TransferEvent::getSourceAssetledgerEntryId, “source-asset”, READ_WRITE)
.on(Assetledger, TransferEvent::getTargetAssetledgerEntryId, “target-asset”, READ_WRITE)
.output();
You then implement the transaction that contains the business logic that decides whether and how to update the table rows provided to it, and what to emit as a result.
These Transaction Functions are passed a state access object for each row that is being read or updated. To correlate the state accesses with the rows and keys, they are annotated with the name defined in the prior step.
For simplicity, we only show the implementation of the ‘TransferFunction’:
public class TransferFunction extends
TransactionProcessFunction<TransferEvent, TransferResult> {
@ProcessTransaction
public void process(
TransferEvent txn,
Context<TransferResult> ctx,
@State(“source-account”) StateAccess<Long> sourceAccount,
@State(“target-account”) StateAccess<Long> targetAccount,
@State(“source-asset”) StateAccess<Long> sourceAsset,
@State(“target-asset”) StateAccess<Long> targetAsset) {
// access the rows for the current values
long sourceBalance = sourceAccount.read();
long sourceAssetValue = sourceAsset.read();
long targetBalance = targetAccount.read();
long targetAssetValue = targetAsset.read();
// check the preconditions: positive and minimum balances
if (sourceBalance > txn.getMinAccountBalance()
&& sourceBalance > txn.getAccountTransfer()
&& sourceAssetValue > txn.getAssetledgerEntryTransfer()) {
// compute the new balances
long newSourceBalance = sourceBalance -
txn.getAccountTransfer();
long newTargetBalance = targetBalance +
txn.getAccountTransfer();
long newSourceAssets = sourceAssetValue -
txn.getAssetledgerEntryTransfer();
long newTargetAssets = targetAssetValue +
txn.getAssetledgerEntryTransfer();
// write back the updated values
sourceAccount.write(newSourceBalance);
targetAccount.write(newTargetBalance);
sourceAsset.write(newSourceAssets);
targetAsset.write(newTargetAssets);
// emit positive result event with updated balances
ctx.emit(new TransferResult(txn, SUCCESS,
newSourceBalance, newTargetBalance));
}
else {
// emit negative result with unchanged balances
ctx.emit(new TransferResult(txn, REJECT,
sourceBalance, targetBalance));
}
}
}
Summary
Ververica Streaming Ledger expands even further the scope of stream processing technology by bringing a whole new wave of applications that previously relied on relational databases to the streaming era!
With Streaming Ledger we are entering in a new chapter for stream processing and we are excited that more and more mission-critical applications can now take full advantage of the real-time, asynchronous, flexible and expressive nature of stream processing. We are very proud of our team and would like to personally thank everyone involved in making this technology possible and bringing stream processing one step forward!


You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
