













In my last blog post, Simplifying Ververica Platform SQL Analytics with UDFs, I showed how easy it is to get started with SQL analytics on Ververica Platform and leverage the power of user-defined functions without having to worry about the details. However, when developing the examples, we skipped an entire category of queries because these could not be displayed in the SQL editor of Ververica Platform 2.3: queries that produce changelog streams, e.g. non-windowed aggregations, top-n queries, and more. I would thus like to take the opportunity of the recent release of Ververica Platform 2.4 to develop a few SQL queries that derive further insights from the Apache Flink community similarly to how a data scientist would develop a real-time streaming analytics application: by iteratively exploring the input data and tuning the query until it fits. I will present changelog streams and what you can do with them along the line of this story.
Preparation
If you want to follow along and eventually run your own analytics, please refer to our previous blog post to get started. In one of the following articles, we will try to simplify the setup and move the data import into the SQL world. Any statements below will assume that you have successfully imported mailing list data into the following 3 Kafka-backed tables as defined in our README file: flink_ml_dev, flink_ml_user,
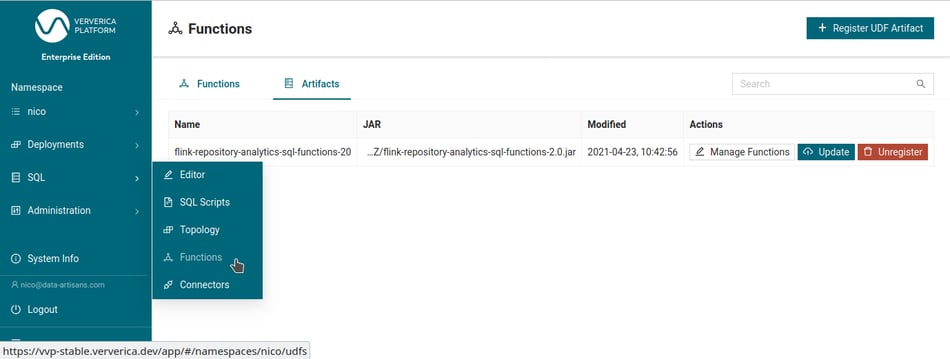
com.ververica.platform.FlinkMailingListToKafka will fetch the mailing list archives from the public mirrors and quickly write their content to Kafka.As before, the code for importing the data, any user-defined functions (UDFs), and more are available on Github as version 2.1. Since we added a few more UDFs to our mix, you need to update the SQL functions' jar artifact (freshly built or fetched from Github’s packages) in Ververica Platform (SQL → Functions → Artifacts → Update), as shown by the screenshot below. After uploading the new version, you will be asked to register any new functions. Select all new functions and register them to use them in the following queries.
We will show any statements below based on Ververica Platform 2.4.2.
Introduction
Last time, we briefly looked at the number of distinct authors on the mailing list with a simple query like this:
SELECT
TUMBLE_END(`date`, INTERVAL '365' DAY(3)) as windowEnd,
COUNT(DISTINCT fromEmail) AS numUsers
FROM flink_ml_user
GROUP BY TUMBLE(`date`, INTERVAL '365' DAY(3));As you see, we have been grouping the result by windows of 365 days. This may be a useful statistic to track over time and look for patterns, especially when altering the query and creating results for different periods of time. You could, for example, change to days of the week or weeks throughout the year with which you should be able to identify typical days or seasons for a vacation that you may also correlate with geographical regions by, for example, comparing the Chinese vs the international user mailing list as the simplest option. However, you may also want to execute this query without grouping by time and just using non-windowed aggregations. In that case, the query will not create an append-only stream but instead a changelog stream that we will explore more below with the help of Ververica Platform 2.4.
Non-Windowed Aggregations
Possibly the simplest queries to showcase non-windowed aggregations are counting the number of (distinct) rows like in the following example:
SELECT
COUNT(DISTINCT fromEmail) AS numUsers
FROM flink_ml_user;Since in streaming mode, we are processing a potentially infinite stream of events (or “rows” in SQL terminology) and see only one event at a time, there is no such thing as a “complete result”. Therefore, any SQL result table can actually only deliver a (temporary) view of the query’s input data up to the current row(s), followed by further result updates. If this stream of result updates adds new rows and needs to correct or remove previous results, we call this a changelog stream. This is actually nothing special but used in day-to-day business to, e.g., materialize - probably more complex - aggregations into external systems and serve real-time dashboards from the most up-to-date (and continuously updated) results.
Before putting such dashboards into production, however, you need to design your aggregations, and typically you start from something simple, explore the results, and take it from there. In Ververica Platform 2.4, you can run any query and observe its results in the preview pane. Changelog streams like the one from the query above will keep updating the result rows as defined by the query and as long as it is running (you can also pause the execution to look at a specific snapshot in time).
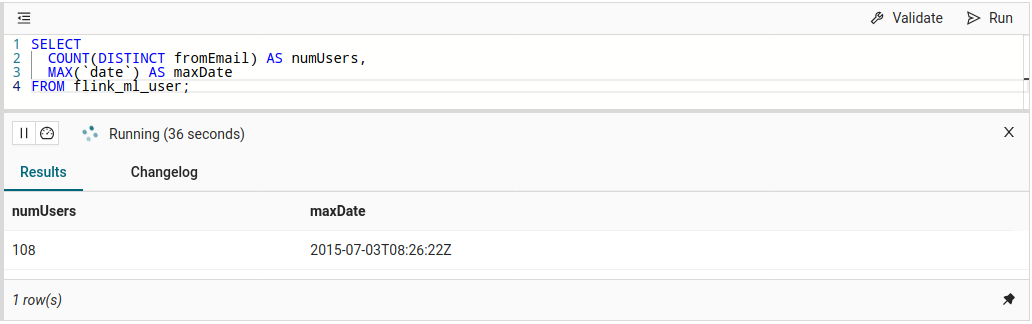
maxDate field as shown, you will also know where you (or your browser) are in our input data. This can sometimes be helpful if you see unexpected results.Behind the scenes, the platform is actually collecting the changes as they appear: the first row inserts “1” (and the date) into the result (+I). As soon as the second distinct user or a new maxDate is seen, the previous row becomes outdated and needs to be retracted (-U), immediately followed by the row's actual update (+U). These updates continue for as long as new data is changing the result and can be observed in detail with the Changelog tab:
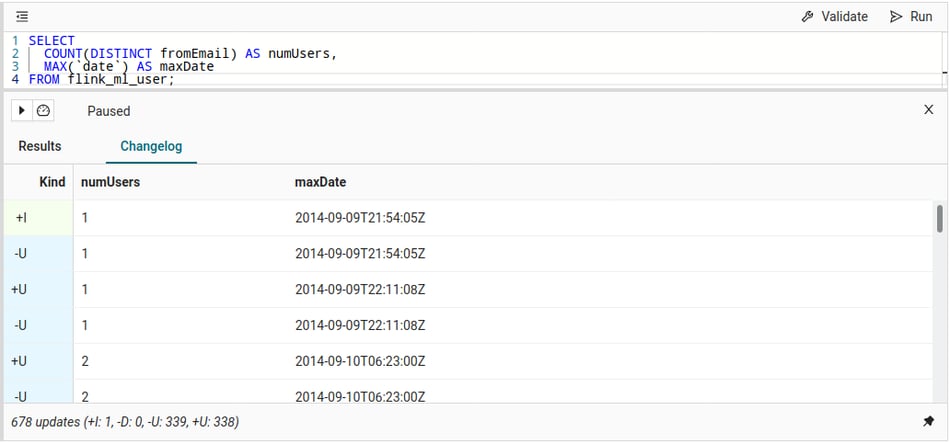
We will iterate these kinds of queries a bit and derive a few more statistics on mailing list use.
Number of Emails per Mailing List User
Instead of counting the total number of emails, how about finding out how many emails each user sent and when they sent the last one? We can do this with a simple extension to our first query:
SELECT
fromEmail AS `user`,
COUNT(*) AS numEmails,
MAX(`date`) AS maxDate
FROM flink_ml_user
GROUP BY fromEmail;While this query is running, you will see new result rows popping up in the preview and existing rows changing. Just as above, you can also inspect the individual changes. These updates are flowing in at a speed where you may even still be able to see individual changes. If you want to take a look behind the scenes and observe the changes live, click the “View in Flink UI” button in the editor which will direct you to the Flink job that is running in the SQL preview’s session cluster.
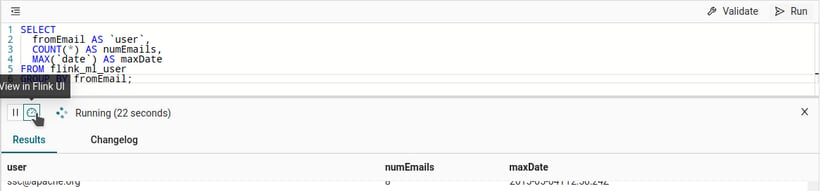
Now, if you click through the tasks from the query you posted, you will eventually find out that the source task is backpressured by the sink task, which does the aggregation and holds the results for Ververica Platform. We made this sink to backpressure the Flink job if the UI is not fast enough in fetching the results - something that feels natural in the streaming world.
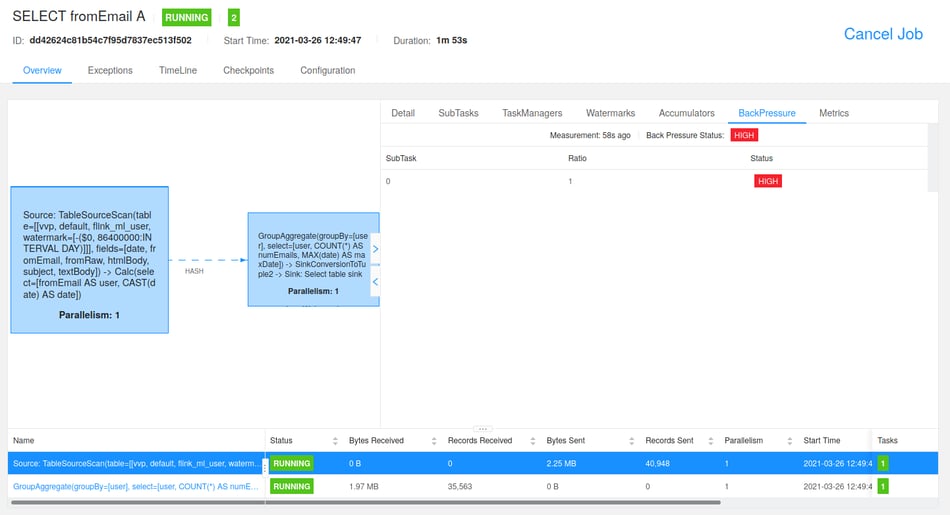
We could now wait until the UI has processed all results and present them on screen, but that wouldn’t be too useful after all since it is too much data to look at anyway. Actually, we do not need the full set of results for this query since we typically use the preview for rapid prototyping of SQL queries to see whether it is working as expected. Similarly, we will expand our query a bit further in the next sections of this post.
INSERT INTO output_table SELECT …
When you run such a query, Ververica Platform will ask you to create a deployment that you can then manage independently and outside of the SQL editor. You can configure this deployment to your needs, and you can change the parallelism, state backends, checkpointing, and more. In addition to cluster settings like these, there are also a couple of SQL Tuning options you can find in our documentation.
Email Aliases and (potential) Company Association for Users on the Mailing List
Let’s try to be a little fancier and find out which email addresses people use on the mailing lists and whether we can attribute these to companies. Especially the company attribution is not an easy task in general. For this section, we will use the information we have from previous emails sent from that user and look at the used email domains. This is not perfect, but good enough for a start.
Let’s first look at the email domains that are present on the list:
SELECT
DISTINCT SUBSTRING(fromEmail FROM POSITION('@' IN fromEmail))
AS domain
FROM flink_ml_user;That results in over 700 rows (all inserts, no retractions), and if you scroll over the entries, you will see a couple of email providers, which we should filter out from company associations. Let’s make this list a bit more digestible by looking at how many unique users each of these domains have:
SELECT
SUBSTRING(fromEmail FROM POSITION('@' IN fromEmail)) AS domain,
COUNT(*) AS uniqueUsers
FROM (
SELECT DISTINCT fromEmail
FROM flink_ml_user
)
GROUP BY SUBSTRING(fromEmail FROM POSITION('@' IN fromEmail))
HAVING COUNT(*) > 5;By showing only domains with more than 5 unique users, we receive a couple of dozen email domains to check manually for being an email provider.
The company association should now work the following way:
-
a user is identified by the name in the FROM field, which is usually composed of
NAME <EMAIL>(for the scope of this article, we will ignore the fact that names are actually not a unique identifier for a person) -
for each user, we collect all email aliases seen so far
-
the most recent non-email-provider domain will be this user’s associated company
This felt like it can be more easily done in a user-defined function which we implemented as GetEmailAliasesAndCompany ( code ). We will discuss creating various types of user-defined functions and handling data types in a separate blog post. For this article, it suffices to know that the logic above is implemented in a user-defined aggregate function that receives an email address and the date it was used, and creates a ROW type result with three fields: aliases contains collected email aliases, company the most recent company association, and companySince the date of the most recent switch to that company (the latter two in the order of processing the rows).
With this function, we define a new temporary view, i.e. flink_ml_user_with_name_and_aliases, that we can leverage for further analysis:
CREATE TEMPORARY VIEW flink_ml_user_with_name_and_aliases AS
SELECT *,
REPLACE(fromRaw, ' <' || fromEmail || '>', '') AS fromName,
GetEmailAliasesAndCompany(fromEmail, `date`) OVER (
PARTITION BY REPLACE(fromRaw, ' <' || fromEmail || '>', '')
ORDER BY `date`
) AS fromAliasesAndCompany
FROM flink_ml_user;REPLACE(fromRaw, ' <' || fromEmail || '>', '') twice in the query above. As long as the called function is deterministic, any number of calls with the same parameters will be optimized into a single actual function call when a query is run. This holds for deterministic built-in functions just as well as any deterministic user-defined functions. This view is essentially the same as the following:
CREATE TEMPORARY VIEW flink_ml_user_with_name_and_aliases AS
SELECT *,
GetEmailAliasesAndCompany(fromEmail, `date`) OVER (
PARTITION BY fromName
ORDER BY `date`
) AS fromAliasesAndCompany
FROM (
SELECT *,
REPLACE(fromRaw, ' <' || fromEmail || '>', '') AS fromName
FROM flink_ml_user
);We can now go ahead and explore this view a bit more. A simple SELECT * FROM flink_ml_user_with_name_and_aliases, for example, presents each email with the information we collected. Before we are confident that we actually implemented it correctly, let’s look at how individual users' results change over time. For that, we need something more practical than this statement: an aggregation for each user, showing the collected aliases and the company association we derived:
SELECT
fromName,
LISTAGG(DISTINCT fromEmail) AS fromAliases,
LEAD(fromAliasesAndCompany.company, 0) AS fromCompany
FROM flink_ml_user_with_name_and_aliases
GROUP BY fromName
HAVING
LEAD(fromAliasesAndCompany.company, 0) IS NOT NULL AND
COUNT(DISTINCT fromEmail) >= 2;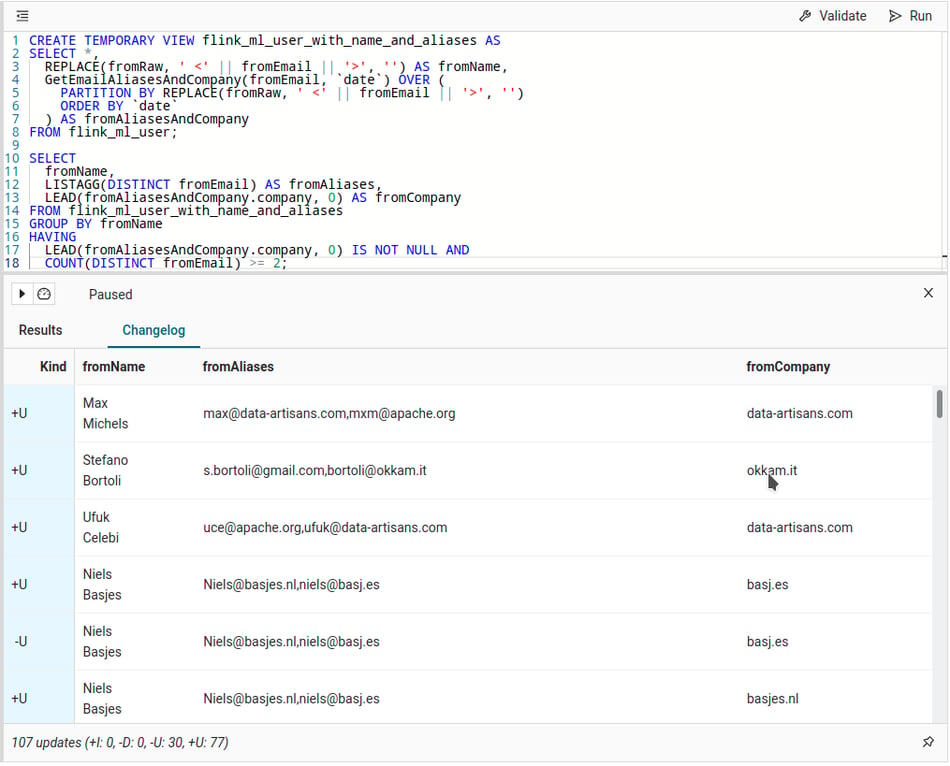
The result is looking fine, and email domains like apache.org are not used for company names but are collected as an alias. You can further explore the flink_ml_user_with_name_and_aliases view by, for example, filtering it on a specific fromName to follow individual people.
fromAliasesAndCompany.aliases in the query above but did our own aggregation with LISTAGG. The reason is two-fold: (1) this field is not being grouped on (which would not make much sense here) and thus cannot be used directly, and (2) we cannot simply use LEAD(fromAliasesAndCompany.aliases, 0) as we did for the company field because LEAD is not defined for array types (yet). If you actually want to verify that the aliases accumulation from GetEmailAliasesAndCompany is also correct, you can either look at the non-aggregated results or use the LargestStringArrayAggFunction user-defined aggregate function ( code )that we implemented for the ARRAY<STRING> type.Finally, we can look at how much activity on Flink’s user mailing list comes from people from specific companies. Here separate for each time window of 30 days:
SELECT
COALESCE(fromAliasesAndCompany.company, 'unknown') AS fromCompany,
TUMBLE_END(`date`, INTERVAL '30' DAY) as windowEnd,
COUNT(*) as numContributions
FROM flink_ml_user_with_name_and_aliases
GROUP BY
COALESCE(fromAliasesAndCompany.company, 'unknown'),
TUMBLE(`date`, INTERVAL '30' DAY)
HAVING COUNT(*) > 10;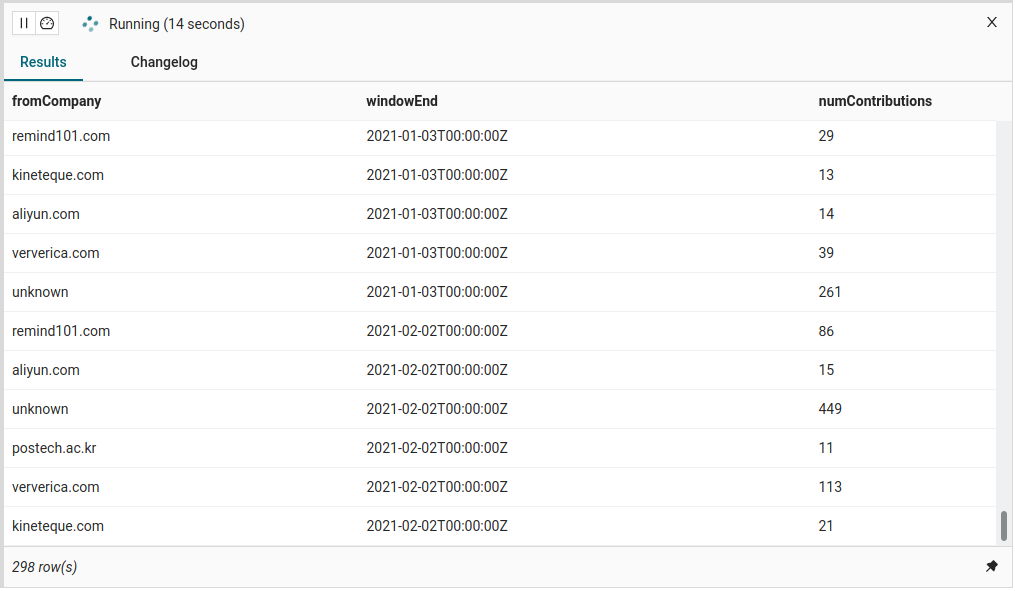
Top-N Aggregations
Another type of query that is often used for analytics and creates changelog streams is a Top-N aggregation that returns the N largest (or smallest) values as determined by a set of columns. The Flink SQL optimizer recognizes Top-N queries if they follow a specific pattern described in detail in our Top-N documentation.
We will use Top-N aggregations to bring some order to the results from the queries shown above and make them easily interpretable. With this, we can widen our statistic’s scope as well.
Read more aboutFlink SQL Recipe: Window Top-N and Continuous Top-N
Most Active Users on any Flink Mailing List
The queries above already created the statistics for the number of emails per mailing list user on user@flink.apache.org. Let’s combine these with the emails on the other Apache Flink community lists that we imported, i.e. user-zh and dev, and find out who was most active per year. We can build the query in two steps for better maintainability:
-
create a (temporary) view of the combined email lists and aggregate the number of emails per user:
CREATE TEMPORARY VIEW flink_ml_user_count_per_user_1y AS SELECT fromEmail AS `user`, COUNT(*) AS numEmails, TUMBLE_END(`date`, INTERVAL '365' DAY(3)) AS windowEnd FROM ( SELECT fromEmail, `date` FROM flink_ml_user UNION ALL SELECT fromEmail, `date` FROM flink_ml_user_zh UNION ALL SELECT fromEmail, `date` FROM flink_ml_dev WHERE NOT IsJiraTicket(fromRaw) ) GROUP BY fromEmail, TUMBLE(`date`, INTERVAL '365' DAY(3)); - apply the Top-N pattern, e.g. for the 10 most active users:
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER ( PARTITION BY windowEnd ORDER BY numEmails DESC, `user`) AS rownum FROM flink_ml_user_count_per_user_1y ) WHERE rownum <= 10;
Alternatively, you can inline the view definition into the Top-N query, e.g. with a sub-query. However, the proposed separation supports you better in looking at the individual tables, e.g. for introspection or debugging. It also allows you to re-use the view many times. e.g. if you, later on, write a full SQL deployment that emits output from different aggregations to multiple Kafka tables via statement sets.
When executing these statements, results will build up, and you can see the changes being applied as they come. Eventually, you will see a final result like this:
.png?width=950&height=529&name=Apache%20Flink%20SQL%20Query%20-%20Running%20-%20Ververica%20Platform%20(2).png)
Most Active Users on any Flink Mailing List (2)
The query above assumes that users are uniquely identified by their email addresses. Similarly, we could use the name as the unique attribute (just like in the alias collection and company association further up). Because we separated the original query from the Top-N, we can switch this definition by simply changing the view to account for the new meaning. Here, we can also add a list of all collected email addresses for double-checking:
CREATE TEMPORARY VIEW flink_ml_user_count_per_user_1y AS
SELECT
REPLACE(fromRaw, ' <' || fromEmail || '>', '') AS `user`,
LISTAGG(DISTINCT fromEmail) AS aliases,
COUNT(*) AS numEmails,
TUMBLE_END(`date`, INTERVAL '365' DAY(3)) AS windowEnd
FROM (
SELECT fromRaw, fromEmail, `date` FROM flink_ml_user
UNION ALL
SELECT fromRaw, fromEmail, `date` FROM flink_ml_user_zh
UNION ALL
SELECT fromRaw, fromEmail, `date` FROM flink_ml_dev
WHERE NOT IsJiraTicket(fromRaw)
)
GROUP BY
REPLACE(fromRaw, ' <' || fromEmail || '>', ''),
TUMBLE(`date`, INTERVAL '365' DAY(3));Most Active Companies on any Flink Mailing List
With the examples above, we have all the building blocks to see how active companies - or people we associate with them - were across all mailing lists. Let me list the steps here nonetheless so you can easily adapt them and derive mailing-list dependent results:
CREATE TEMPORARY VIEW flink_ml_users AS
SELECT *,
REPLACE(fromRaw, ' <' || fromEmail || '>', '') AS fromName,
GetEmailAliasesAndCompany(fromEmail, `date`) OVER (
PARTITION BY REPLACE(fromRaw, ' <' || fromEmail || '>', '')
ORDER BY `date`
) AS fromAliasesAndCompany
FROM (
SELECT fromRaw, fromEmail, `date` FROM flink_ml_user
UNION ALL
SELECT fromRaw, fromEmail, `date` FROM flink_ml_user_zh
UNION ALL
SELECT fromRaw, fromEmail, `date` FROM flink_ml_dev
WHERE NOT IsJiraTicket(fromRaw)
);
CREATE TEMPORARY VIEW flink_ml_users_1y AS
SELECT
COALESCE(fromAliasesAndCompany.company, 'unknown') AS company,
TUMBLE_END(`date`, INTERVAL '365' DAY(3)) as windowEnd,
COUNT(*) as numEmails,
COUNT(DISTINCT fromEmail) as numUsers
FROM flink_ml_users
GROUP BY
COALESCE(fromAliasesAndCompany.company, 'unknown'),
TUMBLE(`date`, INTERVAL '365' DAY(3));
SELECT * FROM (
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY windowEnd
ORDER BY numEmails DESC, `company`) AS rownum
FROM flink_ml_users_1y
) WHERE rownum <= 10;.png?width=1304&name=Apache%20Flink%20SQL%20Query%20-%20Running%20-%20Ververica%20Platform%20(3).png)
Conclusion
In this article, we have looked at changelog streams in general and have worked with them by using non-windowed aggregations and Top-N queries. We described how to leverage the SQL preview of Ververica Platform 2.4 to iteratively build these (streaming) queries and eventually derive community statistics like the most active mailing list users and companies. Once you are satisfied with the queries and the results that you see in the preview, you can easily put them into production and create your own stream processing application with the power and simplicity of Flink SQL and Ververica Platform.
You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
