













Recently there has been significant discussion about edge computing as a major technology trend in 2019. Edge computing brings computing capabilities away from the cloud, and rather close to the field, especially in the Industrial IoT sector (IIoT). In this blog post we describe how Trackunit leverages Apache Flink as the stream processing framework of choice to build data pipelines for fleet management operations in the construction industry.
Trackunit has specialized in the design, development and production of fleet management systems. The company is a world leader in telematics solutions for the construction industry and provides IoT services for a broad portfolio of companies and sectors to optimize the daily operations of its customers. In the following paragraphs, we describe how Trackunit’s data architecture evolved over time to include new features for the company’s data pipeline.
The company’s journey with Flink started in 2016 as part of a new strategy to build its technology powered by distributed, open source data processing technologies for increased scalability and efficient production deployment. The infrastructure was built on AWS, initially using Amazon Kinesis as the messaging queue and Amazon EMR for cluster management, alongside Flink1.2 (which was quickly upgraded to Flink1.3). The following diagram gives an overview of the initial pipeline:
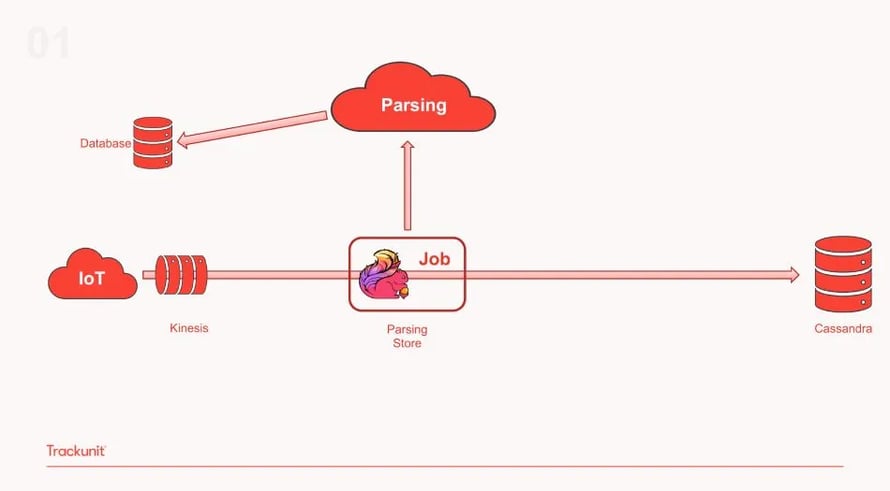
As shown above, in this phase of the architecture the IoT devices send data through telematics to a Kinesis topic that is then passing them on to a single Flink Job for parsing and storage. During this stage, the architecture included an external parsing service that was additionally accessing data from a database asynchronously. The results were then passed back to the single Flink job and then stored in Cassandra.
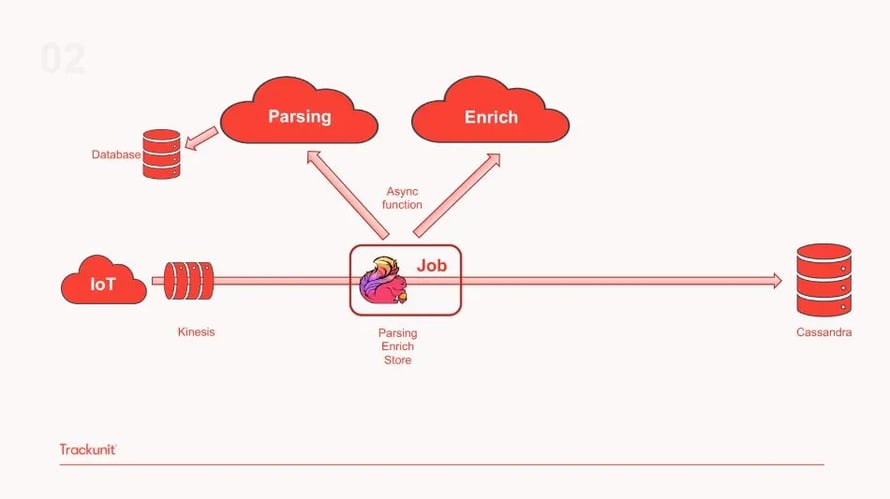
However, due to location data being important for industrial IoT applications like Trackunit’s, the second iteration of the pipeline includes additional data enrichment. This is achieved using Flink’s Async I/O function that calls two separate external services: one for parsing and a second for enriching the data that is then transferred back to the pipeline as shown in the diagram below.
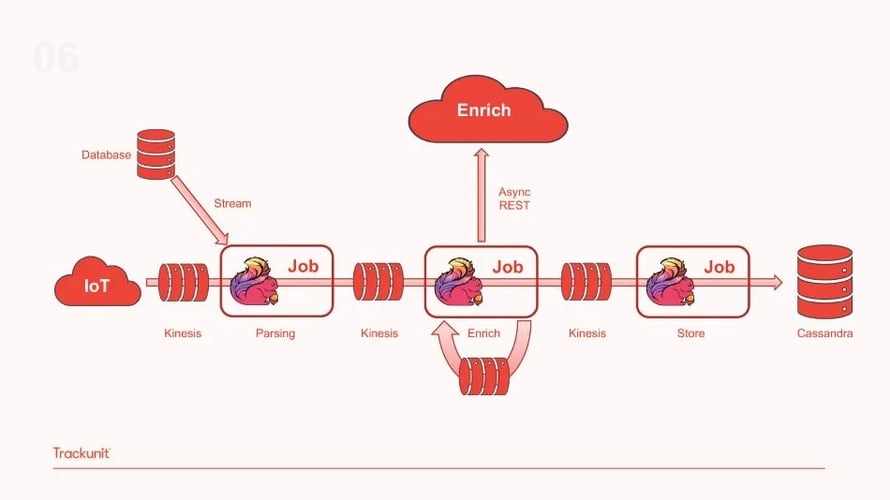
The third evolution of the pipeline includes separating this single job to multiple ones, each specialized in a specific pipeline task. As illustrated below, this iteration includes a Flink job responsible for parsing the data which is then moved to a Kinesis topic, followed by a second Flink job responsible for data enrichment and a third one storing the enriched data to Cassandra.
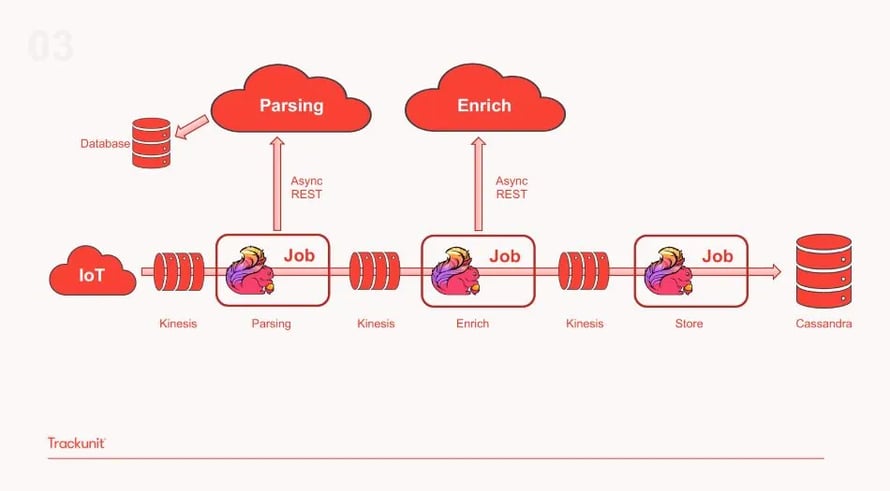
By separating the single Flink job to different ones, the team was able to reuse and add functionality to the same pipeline. Additionally, with each Flink job focusing on a single operation, it became easier to debug and fix issues. Finally, Trackunit’s team can re-use different parts of the infrastructure in different applications as required by the business. This proves to be a scalable solution that allows development work to be repeated and shared across use cases. However, with this setup, the team experienced a slowdown in Flink’s throughput that was caused by the external parsing service. As a solution, the team removed the external parsing service and embedded the code to the Flink parsing job for greater efficiency and faster parsing of the data as shown in the diagram below.
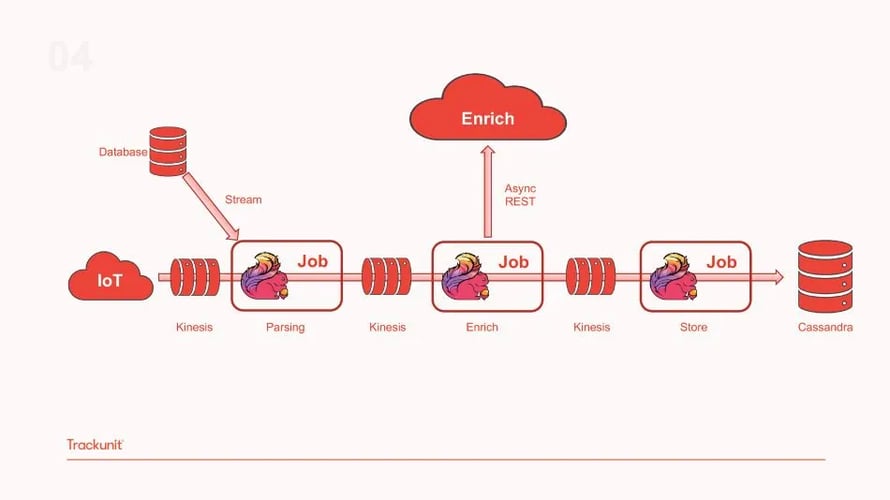
To further increase performance and minimize the number of calls to the async enrichment service, the team implemented a cache to enrich the pipeline with location data before writing to a new Kinesis topic pushing the enriched data downstream as illustrated in the diagram below. This addition managed to decrease the Async calls by 33% which was a big achievement for the team.
Trackunit is constantly looking at new upgrades and Flink features that can increase the pipeline's performance even further and make the architecture more scalable and robust. The team is currently using Flink 1.7.1 in testing and production and plans to replace all internal state to Avro to ensure better state migration.
About Trackunit:
![]() Since 2003, Trackunit has specialized in the design and development of fleet management systems. The company creates both hardware and software solutions within telematics and industrial IoT. Developing unique solutions to provide suppliers, owners and operators of machines with the most effective telematics solutions. We use case studies and customer feedback to generate valuable insights for developing new products and services. Trackunit is the leading global supplier of fleet management solutions, operating out of our HQ in Denmark and eight offices worldwide.
Since 2003, Trackunit has specialized in the design and development of fleet management systems. The company creates both hardware and software solutions within telematics and industrial IoT. Developing unique solutions to provide suppliers, owners and operators of machines with the most effective telematics solutions. We use case studies and customer feedback to generate valuable insights for developing new products and services. Trackunit is the leading global supplier of fleet management solutions, operating out of our HQ in Denmark and eight offices worldwide.
About Apache Flink:
![]() Apache Flink is used by developers to analyze and process data streams of very high volume. By adopting Flink and a data streaming architecture, enterprises can get real-time insights from their data in milliseconds, as well as cover existing historical data processing needs within a single platform. Flink is developed and supported by a vibrant and growing open source community at the Apache Software Foundation with more than 460 contributors, of which Ververica engineers are proud participants.
Apache Flink is used by developers to analyze and process data streams of very high volume. By adopting Flink and a data streaming architecture, enterprises can get real-time insights from their data in milliseconds, as well as cover existing historical data processing needs within a single platform. Flink is developed and supported by a vibrant and growing open source community at the Apache Software Foundation with more than 460 contributors, of which Ververica engineers are proud participants.
You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
