













Authors: Piotr Wawrzyniak & Jarosław Legierski
This blog post describes how we used Apache Flink as the primary stream processing framework for a Smart City project in the city of Warsaw in Poland. This post is a follow up from our presentation at the Flink Forward Berlin 2018 conference. In the following sections, we will present some background information about the VaVeL project and discuss how we used Apache Flink to build two main components of the project, namely our Vehicle Movement Analyser and Vehicle Delay Prediction Systems. Additionally, we will showcase our experience from the integration, deployment, and management of the Apache Flink streaming applications.
What is the VaVeL project?
The goal of the VaVeL project is to radically advance our ability to use urban data in applications that can identify and address citizens’ needs and improve urban life by analyzing a large number of diverse data streams. The VaVeL project stands for Variety, Veracity and Value in handling multiplicity of urban sensors and is supported by the European Union’s Horizon 2020 research and innovation programme. Our goal is to provide a general purpose framework of mining and managing multiple heterogeneous urban data streams for cities to become more efficient, productive and resilient. We aim at solving major issues in urban transportation and mobility that cannot be effectively managed by the current big data management technologies in place. Let’s now have a look at the VaVeL framework architecture as implemented in the use case of the City of Warsaw.
City of Warsaw use case:
For the city of Warsaw, our architecture involves two streams of data focusing primarily on public transport sources. These include the real time location events of trams and buses in the city, including processing real time events from more than 400 trams and 1,800 buses deployed in the city during peak hours. Additionally, we use static data sets to enrich the raw data streams with information from the bus and tram timetables, text information data to the citizen contact number, as well as map and geolocation data, in our efforts to provide useful knowledge that will help the city’s transportation infrastructure as shown in the diagram below.
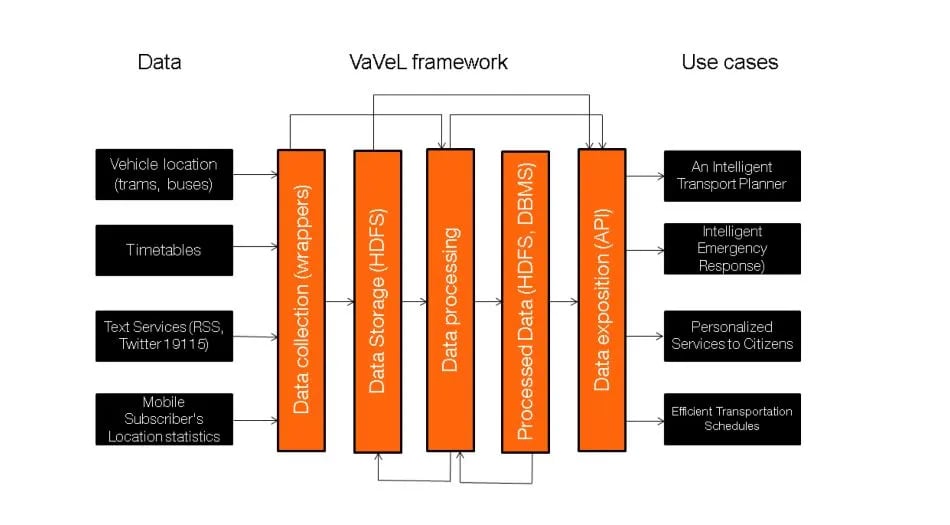 Our architecture includes the data collection and storage layers before moving to the stream processing layer that then exposes the processed data feeds to multiple subscribers. Finally, the four explored use cases in the City of Warsaw include the following:
Our architecture includes the data collection and storage layers before moving to the stream processing layer that then exposes the processed data feeds to multiple subscribers. Finally, the four explored use cases in the City of Warsaw include the following:
-
Intelligent Transport Planner
-
Intelligent Emergency Response System
-
Personalized Services to the Citizen
-
Efficient Transportation Schedule
This system processes sets of data e.g. bus locations (from 2 up 4,5 GBs daily), trams (1 up to 2,5 GB every day), timetables and sets of text information from ZTM (Warsaw Public Transport Authority): web page, RSS feed data, Twitter account data and the non-emergency City reporting system - 19115.
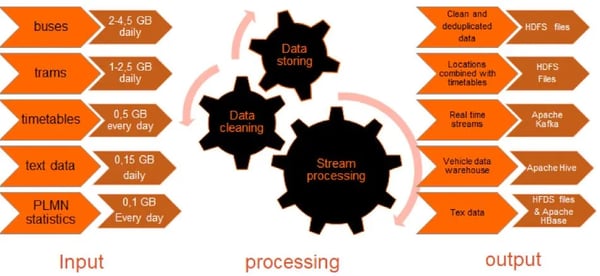
Let’s now discuss the two uses cases where Apache Flink was deployed as the stream processing framework of choice.
Apache Flink - Vehicle Movement Analyzer
This specific application combines event streams of vehicle location data with static timetable data sets in an effort to run real time computations and inform citizens about vehicle delays, stops passing as well as provide the current position of a tram or bus in comparison to the timetable. The application’s input data consists of the real time location information of trams and buses - ingested through Apache Kafka - that is enriched with the timetable data (GTFS files). The system's architecture is shown in the diagram below.
The VaVeL platform produces four new vehicle location data types - vehicle locations linked with schedule 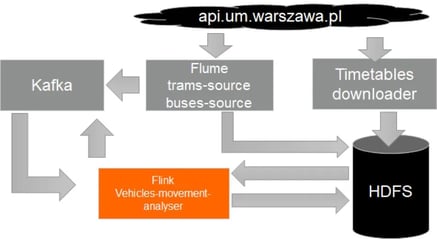 data. Input data - buses and trams location streams are deduplicated, cleaned and combined with timetables information (GTFS). The final output (presented below) is available in the form of a stream in real time and offline in the form of files.
data. Input data - buses and trams location streams are deduplicated, cleaned and combined with timetables information (GTFS). The final output (presented below) is available in the form of a stream in real time and offline in the form of files.
Input data structure
line String, brigade INT, time TIMESTAMP,lon DOUBLE, lat DOUBLE, rawLon DOUBLE, rawLat DOUBLE,
Output data structure
version STRING, line String, brigade INT, time TIMESTAMP,lon DOUBLE, lat DOUBLE, rawLon DOUBLE, rawLat DOUBLE, status STRING, delay STRING, delayAtStop STRING, plannedLeaveTime TIMESTAMP, nearestStop STRING, nearestStopDistance DOUBLE, nearestStopLon DOUBLE, nearestStopLat DOUBLE, previousStop STRING, previousStopLon DOUBLE,previousStopLat DOUBLE, previousStopDistance DOUBLE, previousStopArrivalTime TIMESTAMP, previousStopLeaveTime TIMESTAMP, nextStop STRING, nextStopLon DOUBLE, nextStopLat DOUBLE, nextStopDistance DOUBLE, nextStopTimetableVisitTime TIMESTAMP, courseIdentifier STRING, courseDirection STRING, timetableIdentifier STRING, timetableStatus STRING, receivedTime TIMESTAMP, processingFinishedTime TIMESTAMP, onWayToDepot BOOLEAN, overlapsWithNextBrigade BOOLEAN, atStop STRING,overlapsWithNextBrigadeStopLineBrigade STRING, speed DOUBLE, (serverId STRING) delayAtStopStopSequence DOUBLE, previousStopStopSequence DOUBLE,nextStopStopSequence DOUBLE,delayAtStopStopId STRING,previousStopStopId STRING,nextStopStopId STRING
Detailed information can be found in the VaVeL project deliverables: http://www.vavel-project.eu/deliverables/d63-second-report-system-integration-v13
The output data is used by a dedicated mobile application and other systems of the City of Warsaw.
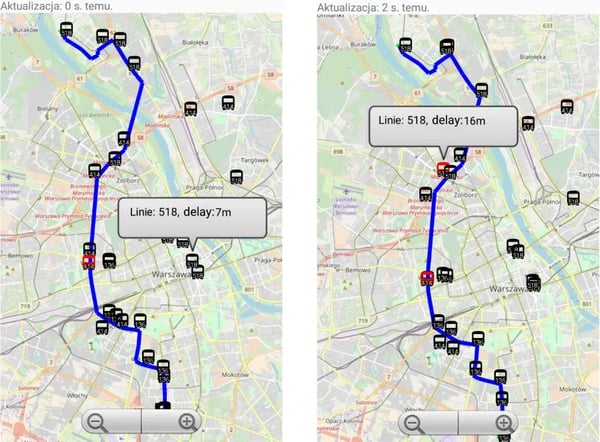
Apache Flink - Vehicle Delay Prediction
This module is built with the goal to predict potential bus or tram delays depending on the route they are following. As shown in the below diagram, the architecture uses as input the pre-processed data from the vehicle movement analyzer and leveraging Apache Flink’s time windowing operations creates time windows of 5, 10, 15, minutes (up to 1-hour windows) that collect information about the delay of a single bus or tram and generate a learning record. This learning record is then used for building the Machine Learning model of the application that predicts the delay of the same bus in the next 15, 20, 30 minute or one hour based on the previously gathered insight. The information is then processed further and included to the route planner interface that informs audiences about potential delays in the next hours.
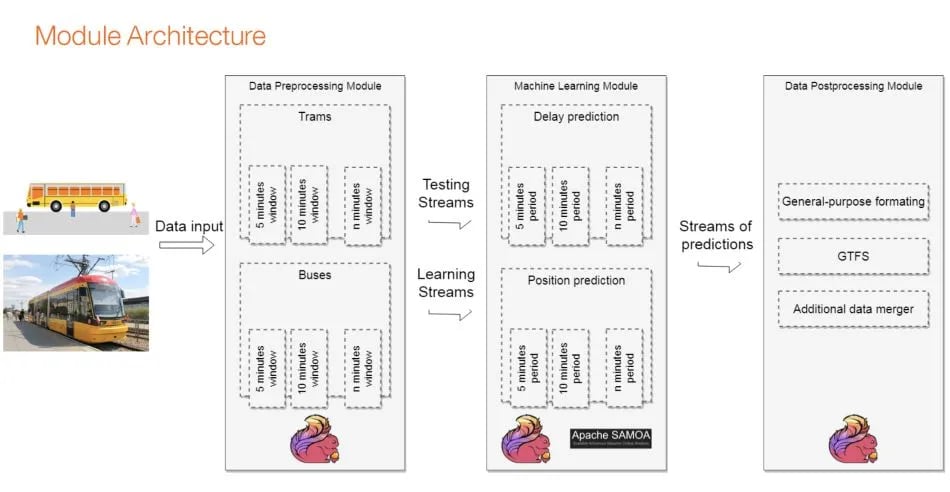
The first Apache Flink job handles the incoming data and provides two main outputs. Firstly, it prepares the testing data stream to be consumed by Apache Samoa which includes data formatting and feature extraction. Secondly, the Flink job prepares the training data used to train the model. The distinction between the two streams is caused by the fact that training data entries can be extracted if - and only if - the desired prediction time elapses. In other words, the true delay or position of the vehicle is known only when a certain amount of time passes while at the same time the predicted values of these features should be available to the user as soon as possible.
In our prototype, solution training data are prepared with the use of the stream windowing feature of the Apache Flink. In particular, different window sizes directly correlated with prediction periods introduced previously, provide streams used to train the ML models. This results in multiple testing and training streams being processed simultaneously.
Conclusion
The goal of the VaVeL project is to radically improve the way we use and understand the city’s data in order to improve citizens’ life quality. This was achieved by efficient processing of data streams and data sets from the public transportation infrastructure of the City of Warsaw. We used Apache Flink to process the data because not only we could handle both data streams and data sets with a single framework, but also because Apache Flink ships with a bunch of features we needed in our processing chain - primarily advanced and flexible windowing operations and stateful stream processing.
Moreover, as we integrated Apache Flink in our prototype clusters and made it manageable via Apache Ambari, we achieved stability and reliability of the entire VaVeL platform and were able to easily control and manage the platform at scale.
The VaVeL project received funding from the European Union Horizon 2020 Programme (Horizon2020/2014-2020), under the grant agreement n° 688380.
Don’t forget to check out our talk from Flink Forward Berlin below or get in touch with us for more information.


You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
