This post originally appeared on the Apache Flink blog. It was reproduced here under the Apache License, Version 2.0.
2017 was another exciting year for the Apache Flink® community, with 3 major version releases ( Flink 1.2.0 in February, Flink 1.3.0 in June, and Flink 1.4.0 in December) and the first-ever Flink Forward in San Francisco, giving Flink community members in another corner of the globe an opportunity to connect. Users shared details about their innovative production deployments, redefining what is possible with a modern stream processing framework like Flink.
In this post, we’ll look back on the project’s progress over the course of 2017, and we’ll also preview what 2018 has in store.
Community Growth
Github
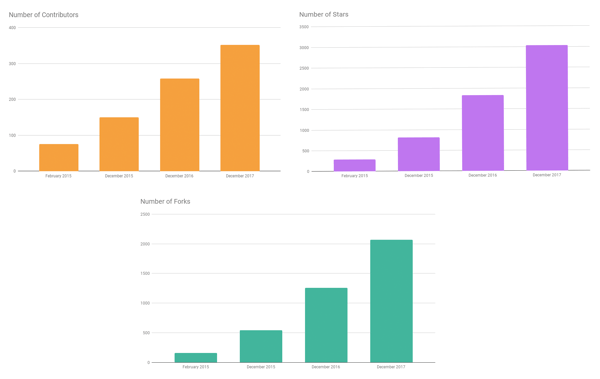
First, here’s a summary of community statistics from GitHub. At the time of writing:
- Contributors have increased from 258 in December 2016 to 352 in December 2017 (up 36%)
- Stars have increased from 1830 in December 2016 to 3036 in December 2017 (up 65%)
- Forks have increased from 1255 in December 2016 to 2070 in December 2017 (up 65%)
The community also welcomed 10 new committers in 2017: Kostas Kloudas, Jark Wu, Stefan Richter, Kurt Young, Theodore Vasiloudis, Xiaogang Shi, Dawid Wysakowicz, Shaoxuan Wang, Jincheng Sun and Haohui Mai.
We also welcomed 3 new members to the project management committee (PMC): Greg Hogan, Tzu-Li (Gordon) Tai and Chesnay Schepler.
 Next, let’s take a look at a few other project stats, starting with number of commits. If we run:
Next, let’s take a look at a few other project stats, starting with number of commits. If we run:
git log --pretty = oneline --after = 12/31/2016 | wc -l
Inside the Flink repository, we’ll see a total of 2316 commits so far in 2017, bringing the all-time total commits to 12,532.
Now, let’s go a bit deeper, here are instructions to take a look at this data yourself.
Download and install gitstats from the project homepage, then clone the Apache Flink git repository:
git clone git@github.com:apache/flink.git
Generate the statistics
gitstats flink/ flink-stats/
View all the statistics as an HTML page using your default browser:
open flink-stats/index.html
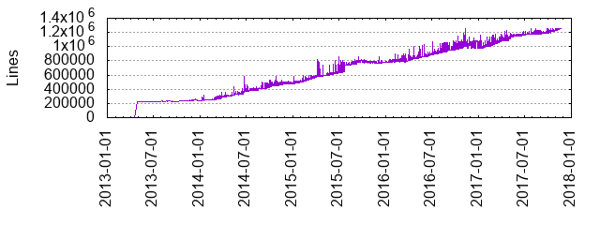
Flink surpassed 1 million lines of code in 2016, and that trend continued in 2017 with the code base now clocking in at 1,257,949 lines.
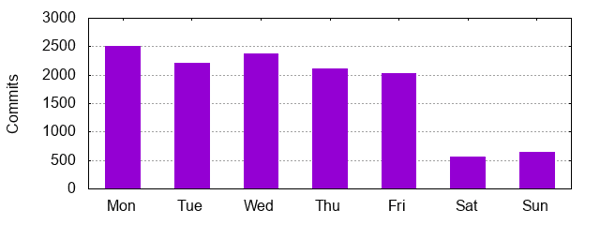
 Monday remains the day of the week with the most commits over the project’s history, but Wednesday is catching up:
Monday remains the day of the week with the most commits over the project’s history, but Wednesday is catching up:
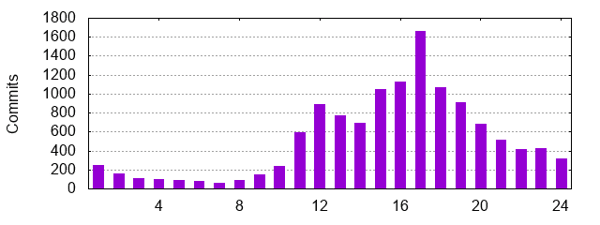
 5 pm remains the preferred commit time, closely followed by 4 pm:
5 pm remains the preferred commit time, closely followed by 4 pm:
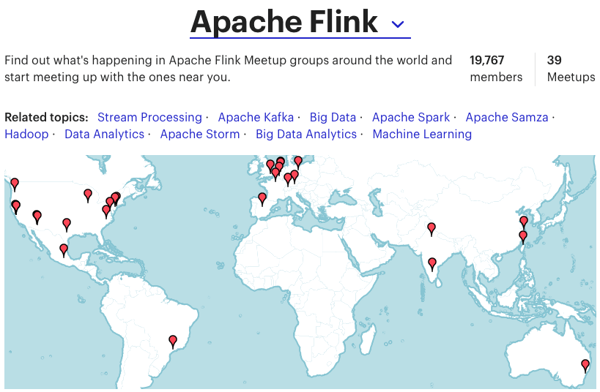
Meetups
Apache Flink Meetup membership grew by 20% this year to a total of 19,767 members at 39 meetups listing Flink as a topic. With meetups on five continents, the Flink community is proud to be truly global.
Flink Forward 2017
2017 was the first year we ran a Flink Forward conference in both Berlin (September 11-13) and San Francisco (April 10-11), and over 350 members of our community attended each event for speaker sessions, training, and discussion about Flink.
Slides and videos are available for all speaker sessions, and if you’re interested in learning more about how organizations use Flink in production, we encourage you to browse and watch a couple.
For 2018, Flink Forward will be back in September in Berlin, and in April in San Francisco.

Features and Ecosystem
Flink Ecosystem Growth
Flink was added to a selection of distributions and integrations during 2017, making it easier for a wider user base to get started with Flink:
-
A Flink connector for Pravega, Dell/EMC’s streaming storage system.
-
Uber announced AthenaX, a streaming SQL platform powered by Apache Flink.
-
dataArtisans announced an early access program of a product that includes open source Apache Flink, dA Platform.
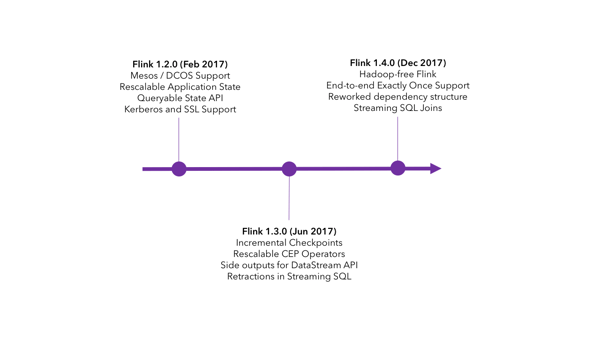
Feature Timeline in 2017
Just in time for the end of the year, our 1.4 release read the full release announcement landed in mid-December culminating 5 months of work and the resolution of more than 900 issues. This is the fifth major release in the 1.x.y series.
Here’s a selection of major features added to Flink over the course of 2017:
If you take a look at the resolved issues and enhancements for 2017 on Jira you can see that the community resolved over 1,831 issues and feature additions.
Regarding roadmap commitments from 2016, there is mixed news, with some items a part of current releases, others scheduled for upcoming releases and some that remain under discussion.
Looking ahead to 2018
A good source of information about the Flink community’s roadmap is the list of Flink Improvement Proposals (FLIPs) in the project wiki. Below, we’ll highlight a selection of FLIPs accepted by the community as well as some that are still under discussion.
Work is already underway on a number of these features, and some will be included in Flink 1.5 at the beginning of 2018.
-
Improved BLOB storage architecture, as described in FLIP-19 to consolidate API usage and improve concurrency.
-
Integration of SQL and CEP, as described in FLIP-20 to allow developers to create complex event processing (CEP) patterns using SQL statements.
-
Unified checkpoints and savepoints, as described in FLIP-10, to allow savepoints to be triggered automatically–important for program updates for the sake of error handling because savepoints allow the user to modify both the job and Flink version whereas checkpoints can only be recovered with the same job.
-
An improved Flink deployment and process model, as described in FLIP-6, to allow for better integration with Flink and cluster managers and deployment technologies such as Mesos, Docker, and Kubernetes.
-
Fine-grained recovery from task failures, as described in FLIP-1 to improve recovery efficiency and only re-execute failed tasks, reducing the amount of state that Flink needs to transfer on recovery.
-
An SQL Client, as described in FLIP-24 to add a service and a client to execute SQL queries against batch and streaming tables.
-
Serving of machine learning models, as described in FLIP-23 to add a library that allows users to apply offline-trained machine learning models to data streams.
If you’re interested in getting involved with Flink, we encourage you to take a look at the FLIPs and to join the discussion via the Flink mailing lists.
Lastly, we’d like to extend a sincere thank you to all the Flink community for making 2017 a great year!






