













This post explores the Broadcast State pattern that was introduced in Apache Flink 1.5.0. In the following sections, we describe what is a Broadcast State Pattern, how Broadcast State differs from other types of operator state, and finally, we go over some important considerations when using the feature in Apache Flink.
What is a Broadcast State Pattern?
The Broadcast State Pattern refers to streaming applications where a low-throughput event stream (that, for example, contains a set of rules) is broadcasted to all parallel instances of an operator and is then evaluated against all elements coming from another event stream with raw data (for example financial or credit card transactions). Some motivating use cases for the Broadcast State Pattern are the following:
-
Application of rules from a low-throughput event stream to raw incoming data: for example, broadcasting the rule that an alert should be sent when a transaction value is greater than $1 million to all parallel tasks of your operator.
-
Data Enrichment: for example, enriching a stream of transactions that contain a user ID, with the broadcasted data associated with that user ID.
To allow for such applications, a critical component is the Broadcast State, which we describe below.
What is Broadcast State?
The Broadcast State is the third supported type of operator state in Apache Flink. Broadcast State enables Flink users to store in a fault-tolerant and re-scalable way the elements from the broadcasted, low-throughput event stream (see examples above). Events from the second stream can then flow through the individual instances of the same operator that processes them together with the events in the broadcast state. For more information on the other types of state and how to use them visit the Flink documentation here.
There are three main differences between Broadcast State and the rest of operator states. Contrary to the remaining types of operator state, the Broadcast State:
-
has a map format,
-
has as input a broadcasted event stream, and
-
the operator tasks can have multiple Broadcast States with different names.
You can check our previous blog post to explore a step-by-step practical guide to Broadcast State in Apache Flink.
Important considerations
For Flink users keen to get started with Broadcast State, the Apache Flink documentation provides details about the APIs and how to use the feature in your pipelines.
There are 4 important things to keep in mind when using Broadcast State:
- With Broadcast State, operator tasks do not communicate with each other
This is the reason why only the broadcast side of a (Keyed)-BroadcastProcessFunction can modify the contents of the Broadcast State. The user should ensure that all operator tasks modify the contents of the Broadcast State in the same way for each incoming element. Alternatively, different tasks might have different contents, leading to inconsistent results.
- The order of events in Broadcast State may differ across tasks
Although broadcasting the elements of a stream guarantees that all elements will (eventually) go to all downstream tasks, elements may arrive in a different order to each task. As a result, any state update for each incoming element should not depend on the ordering of the incoming events.
- All operator tasks checkpoint their Broadcast State
Upon checkpointing, all tasks checkpoint their Broadcast State, and not just one of them, even though all tasks store the same elements in their Broadcast State. This is a design decision to avoid reading from a single file during a restore and consequently avoiding hotspots. However, there is a tradeoff of increasing the size of the checkpointed state by a factor p (= parallelism). Flink guarantees that upon restoring/rescaling there will be neither duplicates nor missing data. In case of recovery with the same or smaller parallelism, each task reads its checkpointed state. Upon scaling up, each task reads its own state, and the remaining tasks (p_new-p_old) read checkpoints of previous tasks in a round-robin approach.
- RocksDB state backend is not available for Broadcast State
Broadcast State is kept in memory at runtime. Since currently, the RocksDB state backend is not available for operator state, Flink users should arrange their application’s memory provisioning accordingly for all operator states.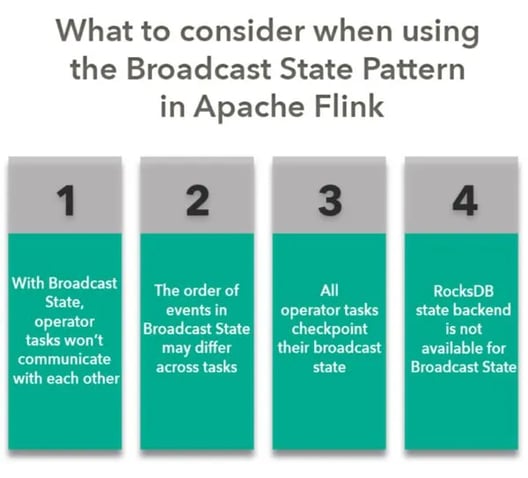 Sign up to Apache Flink Public Training in a location near you for a comprehensive introduction to stateful stream processing with Apache Flink or contact us with your questions and recommendations below.
Sign up to Apache Flink Public Training in a location near you for a comprehensive introduction to stateful stream processing with Apache Flink or contact us with your questions and recommendations below.


You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
