













Data Labs from SK telecom was at FlinkForward Berlin 2017 and 2018, to present how SK telecom uses Apache Flink for different scenarios in the company. Last year at FlinkForward Europe 2019, we presented FLOW, a web service that allows users to do “Flink On Web”. FLOW aims at minimizing the effort of handwriting streaming applications by letting users drag and drop graphical icons representing streaming operators on a Graphical User Interface (GUI).In the following sections, we will discuss the motivation behind developing FLOW at SK telecom, we will describe how the FLOW GUI develops and executes Flink streaming pipelines and finally, we will explain the product’s architecture and how it interacts with Apache Flink.
Motivation behind developing FLOW
SK telecom’s journey with Apache Flink started back in 2017 with the development of a predictive maintenance solution as the first use case and expanded further in 2018 with the development of a real time driving score service. However, as the adoption of Apache Flink grows within the organization, the existing way of working provided inefficiencies when it comes to scaling the development of Flink streaming applications. Essentially, the data engineering team was in the middle of the domain experts, with their domain knowledge, requirements and data to be processed, and the technical background necessary to develop and deploy Flink applications. As a result, we had to come up with a way to democratize the development of streaming applications with Apache Flink to the wider technology teams in the company, while at the same time minimize any efforts of onboarding teams to a new technology, from scratch.
This is where FLOW comes into play. FLOW is an easy-to-use abstraction layer on top of Flink that allows our internal teams at SK telecom to submit their data, domain expertise and requirements using SQL, and build stream processing pipelines of SQL operators and connectors through a graphical user interface (GUI).
FLOW’s motivation and design aim at minimizing much of the unavoidable, repetitive steps that most Flink users might have experienced when handwriting Flink applications on IDEs, such as:
-
Creating a maven project including all Flink dependencies
-
Initiating a stream processing pipeline with a custom source in order to read sample data from files or arrays
-
Adding DataStream.print() throughout the pipeline to check whether intermediate results are being computed as intended
-
When timers and windows are not working as expected, implementing a custom ProcessFunction and adding it to suspicious operators merely to print record timestamps and watermarks
-
When visualization is needed, copying and pasting intermediate results from the IDE console into Elasticsearch, and then making the visualizations in Kibana
-
Replacing the custom source with a Kafka source and removing (3) and (4) before building an artifact to be executed on production
While eliminating inefficiencies in Flink application development, FLOW also aims at providing domain experts — with basic knowledge of SQL — the building blocks for developing and running Flink applications, by letting them express their knowledge and requirements using SQL expressions and predicates.
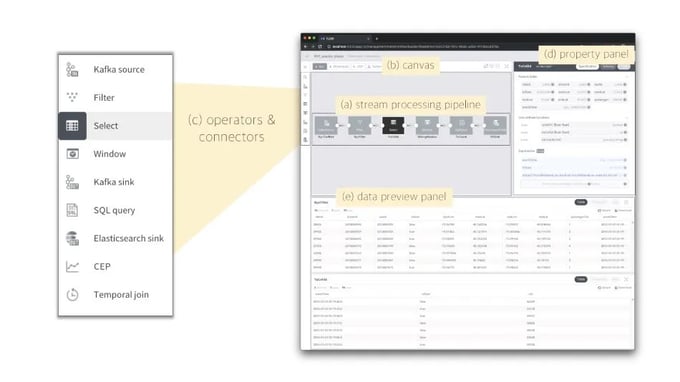
Figure 1: Components of FLOW GUI
Figure 1 shows the main components of FLOW’s GUI, where users can construct (a) a stream processing pipeline on (b) a canvas in a drag-and-drop manner using (c) icons corresponding to operators and connectors. Users are required to configure the selected operator on (d) a property panel. In case of a Select operator — since FLOW assumes that users can at least express their requirements using SQL — users are only required to fill out in the panel a set of expressions for the operator. The property panel also shows useful information, such as parent operator’s schema and available UDF instances, providing users with contextual hints. (e) FLOW’s data preview shows how data changes before and after applying operations, along with useful information such as record timestamps and watermarks as tooltip on mouse hover on each record. In addition, FLOW exports the preview to Elasticsearch and Kibana, and embeds time series charts and geographical maps from Kibana on the preview panel. In this way, FLOW does a lot of things, behind the scenes, in order to improve efficiency in the development of stream processing applications for users.

Figure 2: Comparison of Flink relational APIs for solving the same problem
When compared with writing a very long SQL query, building a stream processing pipeline with the use of SQL operators is significantly easier-to-use. For instance, consider the two different approaches to the same problem using Flink’s relational APIs shown in Figure 2. Although SQL is designed to be declarative, it can get complicated and become harder to reason about, especially when things get nested as shown above. Instead, we decided to use operations of Flink’s Table API as FLOW’s icons, such as Select, Filter, Window, so that even domain experts can build their stream processing applications with familiar vocabulary in a procedural way. Together with the data preview, this decision allows users to experience the results of applying each SQL operator on sample data instantly, something that brings FLOW’s usability to a higher level, when compared to only allowing long SQL queries.
It’s worth mentioning that FLOW also lets advanced users directly write SQL queries in the middle of a pipeline via the SQL query operator. Therefore, different pipelines can be built on FLOW to figure out the same problem:
-
Kafka source→SQL query (long nested query)→Kafka sink
-
Kafka source→Filter→Select→Window→Filter→Select→Kafka sink
-
Kafka source→Filter→Select→Window→SQL query (Filter+Select)→Kafka sink
-
Kafka source→SQL query (Filter+Select)→Window→SQL query→Kafka sink
-
Kafka source→SQL query→SQL query (Window)→SQL query→Kafka sink
Even though these pipelines do not look the same, Flink produces the identical optimized query plan thanks to the architecture of its relational APIs as shown in Figure 3.
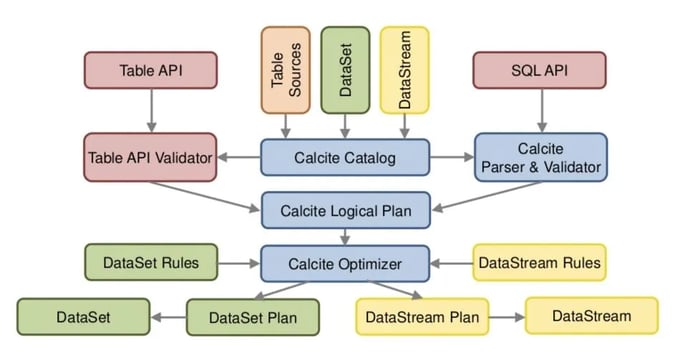
Figure 3: Architecture of Flink's relational APIs
Once a pipeline is fully constructed, FLOW internally generates a Maven project and a Java application, mainly written in Flink’s Table API, on behalf of the user. Note that the one-to-one correspondence between Flink Table API operators and FLOW pipeline components makes the code generation just a piece-of-cake. When the user clicks on the download button on the canvas, FLOW builds an artifact by packaging the Maven project. In addition, FLOW allows to download the Maven project itself so that the user can start building more complicated pipelines or projects from this point. This way FLOW is intended to support both domain experts and seasoned Flink users altogether.
With the development of FLOW we anticipate that the speed and scalability of bringing Flink streaming applications to SK telecom will be significantly accelerated, allowing more technology and domain experts to leverage the power of real time data and a powerful stream processing framework like Apache Flink.
How FLOW interacts with Apache Flink
In this section we discuss how FLOW interacts with Apache Flink under the hood. Whenever a user drags and drops an operator’s graphical icon on the canvas, FLOW creates a corresponding resource on its RESTful backend server. Every time a user completes the specification of an operator on the GUI, the corresponding resource is updated with the same information in the backend. In order to provide the schema and preview on the GUI, FLOW relies on a number of preview loaders, namely the KafkaPreviewLoader and the FlinkPreviewLoader, instead of computing the schema and data preview on the system’s backend.
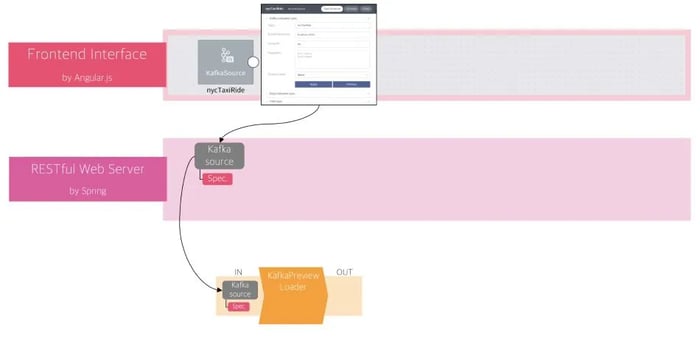
Figure 4: The input of KafkaPreviewLoader
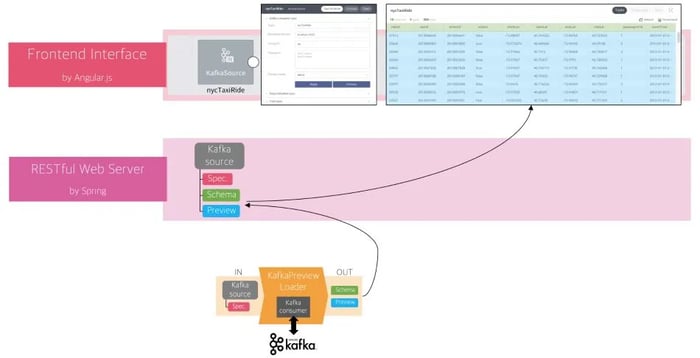
Figure 5: The output of KafkaPreviewLoader
The KafkaPreviewLoader will receive the specifications from FLOW’s backend system as an input (Figure 4) and will push back to the backend both the schema and data preview as an output which then brings up the table results to the user interface (Figure 5). The specification of an external connector like Kafka source also includes a policy about how to get samples from the external storage system, in this case Apache Kafka.
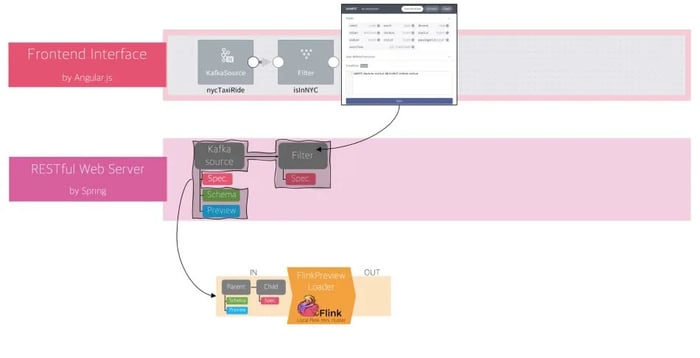
Figure 6: The input of FlinkPreviewLoader
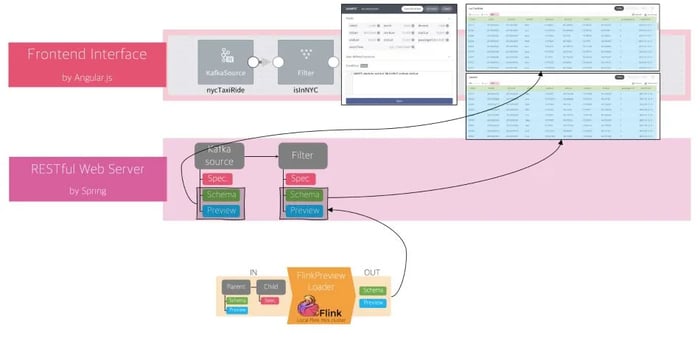
Figure 7: The output of FlinkPreviewLoader
The FlinkPreviewLoader will be invoked when the user adds a SQL operator on the canvas and connects it to a parent operator. Consider a scenario when the user adds a Filter operator on the canvas and connects it with the Kafka source (Figure 6). The FlinkPreviewLoader requires as input not only the specification of the Filter but also the schema and preview of the Kafka source (Figure 5). This is because the Filter operator has no way but to derive its schema and preview data from its parent operator. Once calculated by the FlinkPreviewLoader, Filter’s schema and preview are then stored on the backend and returned back to the user interface along with its parent’s schema and preview (Figure 7). That allows the user to see and experience the difference between and after applying the SQL operation on the web user interface. The process is the same for other operators supported in FLOW. The overall architecture for data preview is shown in Figure 8.
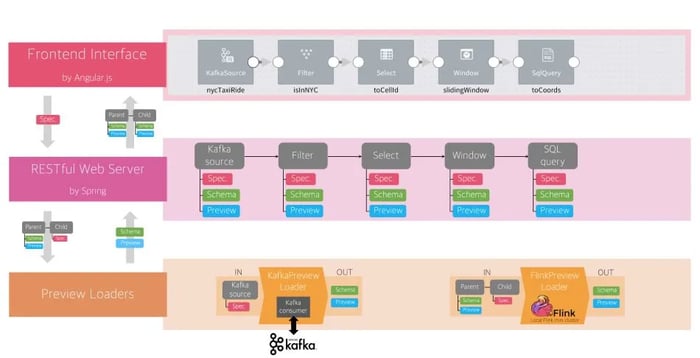
Figure 8: The overall architecture of a FLOW service for data preview
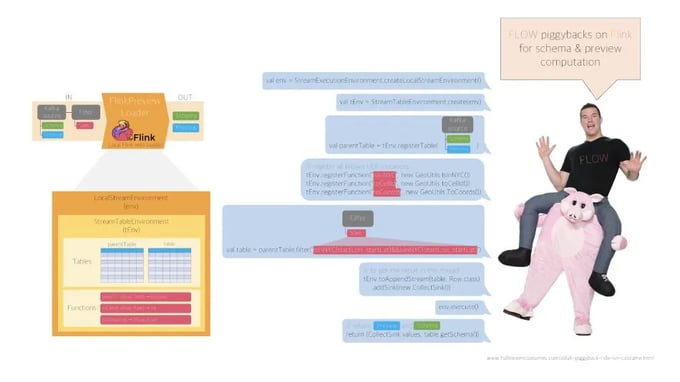
Figure 9: Interaction between FlinkPreviewLoader and Flink Table API
Taking a closer look at how the FlinkPreviewLoader operates, we see that FLOW piggybacks on Flink for computing schema and preview as illustrated in Figure 9. As a first step, a local Flink mini cluster is created along with a TableEnvironment per user session. Then the system inputs the schema and preview of the parent operator to define a parent table and registers all the UDFs before creating the target table using the specification of the target operator, in this example a filtering condition of the Filter operator. Finally, the FlinkPreviewLoader will return the schema and preview of the target table as output.
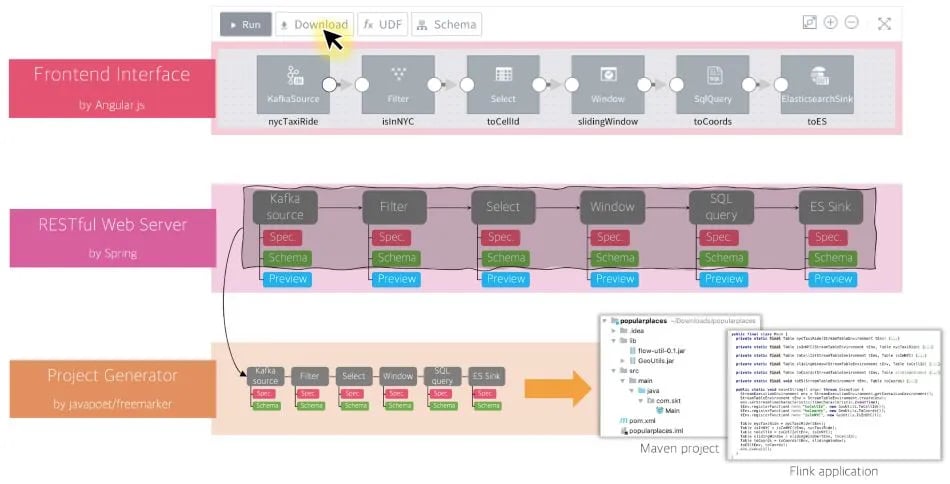
Figure 10: The overall architecture of a FLOW service for project generation
As illustrated in Figure 10, in order to generate a Maven project and a Java application only the specification and schema of each operator is necessary. Note that the generated project does not include the operator’s preview because it is used as an assistance mechanism showing how samples are being transformed when passing through each component of this pipeline.
Summary
Building on this architecture, FLOW currently supports a number of sinks and sources, including Kafka source, Kafka sink and Elasticsearch sink as well as many basic and advanced SQL operators — including Temporal join and Pattern recognition (SQL’s MATCH_RECOGNIZE clause). Additionally, we provide support for a range of UDF functions, supported in Flink relational APIs, and three different data preview types, including table preview, time series chart and graphical maps. Future plans for the development of FLOW include support for additional connectors and SQL operations as well as job management so users can efficiently manage the lifecycle of their streaming pipelines over time. If you want to find out more information about FLOW, you can watch our Flink Forward Europe 2019 session recording on YouTube or contact us with your comments and suggestions.


About the authors:

Dongwon Kim
Dongwon Kim is a big data architect at SK telecom. During his postdoctoral work, he was fascinated by the internal architecture of Flink and gave a talk titled “a comparative performance evaluation of Flink” at Flink Forward 2015. He introduces Flink to SK telecom, SK energy, and SK hynix to fulfill various needs for real-time streaming processing from the companies and shares the experiences at Flink Forward 2017 and 2018. He is recently working on a web service to promote the wide adoption of streaming applications companywide.

Markos Sfikas
Markos is a Marketing Manager at Ververica. He obtained an MSc in International Marketing from the University of Strathclyde. He previously worked at ResearchGate and LinkedIn in the areas of Product Marketing, Content Marketing & Online Advertising.
You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
