













I recently presented at Flink Forward San Francisco 2019 and showcased how the User Location Intelligence team at Yelp uses Apache Flink for predicting real-time store visits. In the following sections, I will give an overview of our stream processing journey with Flink, describing the product that we built, the algorithms that we used to resolve specific problems and how Flink enabled us to overcome some limitations we faced with our legacy systems and code execution. Let’s first showcase the product that we built based on Flink.
Real-time store visits prediction at Yelp
Yelp’s mission is to connect people with great local businesses and part of what the Yelp Engineering team does is build products and experiences to help our users find, connect and interact with those businesses on the Yelp app.
To do that, we built a new mobile notification with the primary objective to inform and suggest the best nearby local businesses to Yelp users. As simple as it might sound, this feature requires a lot of background work to ensure that any push notification sent to a user is timely and relevant.
The product requires low latency data processing since any communication with the user should take place while the user is in close proximity to these local stores. That, in turn, provides great response rates and ensures an optimal user experience. At the same time, notifications need to be relevant and tailored to the specific user, at this designated place in the specific moment to ensure that any recommendation is personalized for the user and their current and previous interaction with the Yelp app. To accomplish this, we built a Machine Learning model tightly coupled with a Flink stream processing application.
One important thing to note about the product is that notifications are only sent to users who explicitly share their location data with Yelp. Users can choose between sharing their location data or not and can easily update their preferences and user settings on the Yelp app at any time.
Let’s now look at our data input and how we process it to enable real-time store predictions at Yelp. As illustrated in the following picture, our input data consists of geospatial location data from mobile devices of Yelp users. In order to make sense of the data, we need to first determine whether there is an ongoing user visit (as illustrated within the blue circle where various samples from the same device are in close proximity to each other at a selected timeframe). Once we have determined a visit (or stopover), we use a Machine Learning algorithm to rank and predict the best candidate business nearby and finally send timely notifications with suggestions to Yelp users.
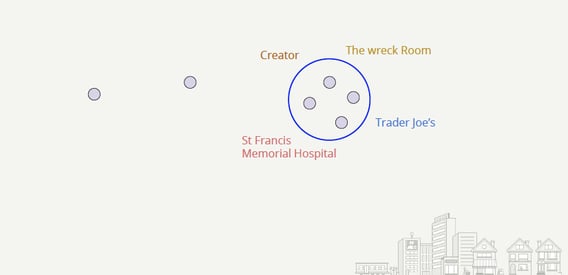
The user's store visit is predicted in real-time leveraging a XGBoost Machine Learning Model that is trained to match businesses given the specific locations and users.
System Overview
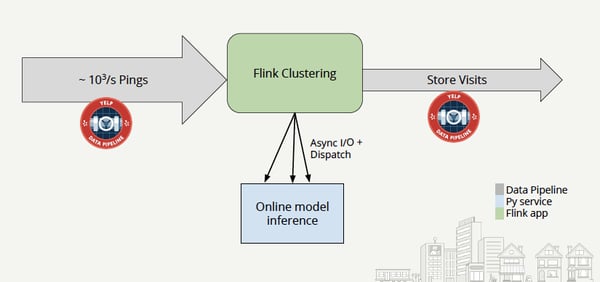
Our system overview includes the Yelp Data Pipeline ingesting tens of thousands of pings per second into the Flink job for real-time clustering. Our clustering bundles raw location data into visits that will be linked to business IDs later on. Flink delegates the Machine Learning inference to an external Python service using Flink’s Async I/O in combination with scala_dispatch — for efficient execution of HTTP calls. The online model will then return the predictions back to Flink which sends them downstream as “store visits” for other teams to use.
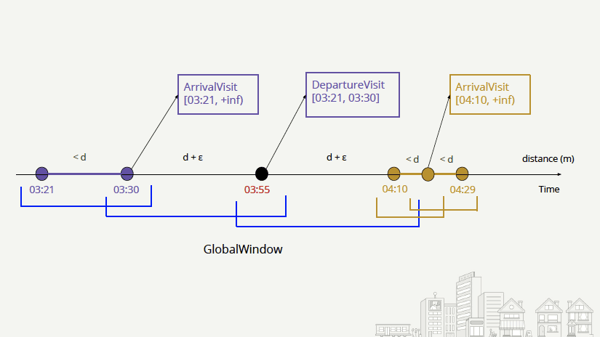
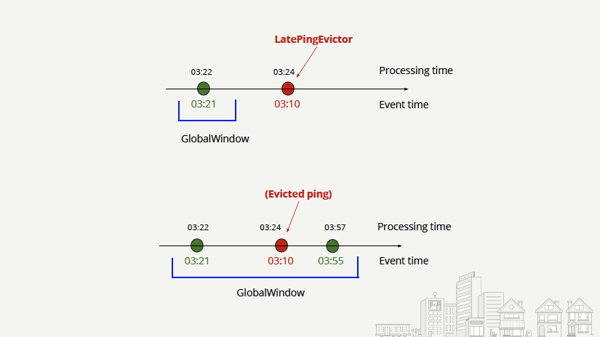
For data clustering, we customize Flink’s ProcessWindowFunction and utilize a GlobalWindow keyed by “user_id” to continuously analyze pairs of consecutive pings from the same user as shown in the diagram below. Using stateful operations in Flink, we assign each new ping to the GlobalWindow, we evict the old ping and run the clustering to detect when the new ping refers to an arrival, a visit, or a departure from a local store.
Handling time and out-of-order data
One of the biggest challenges in building this product feature was handling time and dealing with out-of-order or late data. Mobile devices showcase a very particular behavior in that they are far from the backend, can go offline for hours or even days and have mobile clocks that can be set up incorrectly. Flink’s ability to handle different notions of time (event, ingestion or processing time) at once simplified our approach significantly. The team developed a LatePingEvictor that prevents any late arriving ping to see the global window as illustrated in the diagram below. Using Flink’s GlobalWindow, Evictors and ProcessWindowFunction, we can see if the event time of a ping is later than the one of the previous to evict it and exclude it from the clustering.
Why we chose Flink
To understand why we chose Flink and the features that turned Flink into an absolute breakthrough for us, let’s first discuss our legacy systems and operations. Firstly, before migrating to Flink, the team was heavily reliant on Amazon SQS as a queue processing mechanism. Amazon SQS does not support state so the team had to work off a fragile, in-house-built state that could not support our use case. With the use of Flink’s stateful computations we could easily retain in Flink state the past (arrival) ping, necessary to successfully run the clustering algorithm — something hard to accomplish with the previous technology.
Secondly, Flink provides low latency and high throughput computation, something that is a must-have for our application. Prior to the migration, the team was operating on an abstraction layer on top of SQS, executed with Python. Due to Python’s global interpreter lock, concurrency and parallelism are very limited. We tried to increment the processing instances, but having so many instances meant it was very hard to find resources by our container management system PaaSTA that made our deployments take hours to complete. Flink’s low latency, high throughput architecture is a great fit for the time-sensitive and real-time elements of our product.
Finally, Amazon SQS provides at-least-once guarantees that is incompatible with our use case since having duplicate pushes in the output stream could lead to duplicate push notifications to the user resulting in negative user experience. Flink’s exactly-once semantics guarantee that our use case leads to superior user experience as each notification will only be sent once to the user.
Looking closer at the impact that Apache Flink had in our development process, we observed the following: Using Flink resulted in 10X increase in visits recall, being able to scale our Machine Learning predictions to thousands per second, decreasing our operations from hundreds of Python instances down to 14 Flink instances and finally being 5X more cost-efficient compared to our previous technology stack.

The overall experience with Flink was very positive, the communication with the community and the mailing lists were very friendly and welcoming and I can only recommend Flink for similar use cases to ours. If you want to find out more about our use case and our journey with Apache Flink, you can access my Flink Forward presentation below or even hear more news about how Yelp is using Flink in the upcoming Flink Forward Europe 2019 event, this October in Berlin.


You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
