













The Smart Systems IoT Use Case
IoT systems use data and artificial intelligence (AI) to monitor, control, or predict the behavior of internet-connected devices. They are the basis for new smart factories, smart cities, and smart vehicle fleets that are transforming the way society lives, travels, and produces goods.
The challenge for IoT software developers is to process and act on the massive amounts and variety of data these systems produce. If you are developing smart systems, this blog post describes the architecture of an open source IoT data platform stack that makes it easy and economical to handle the following IoT requirements:
-
Scale - Millions of messages per second to ingest, enrich, store, and analyze.
-
Performance - Sub-second query speed to control, alert, predict in real time.
-
Data variety - Hundreds of different sensor message structures, always evolving.
-
Time Series, Search, SQL - Process time series data and more without needing multiple databases.
-
Variability - Unpredictable outages and delays impact data accuracy.
-
Uptime - Non-stop operation and reliability.
-
No lock in & time to market - Standard interfaces & open source make it easy to hire talent, integrate with other technologies, and avoid platform lock-in.
This whitepaper provides a step-by-step tutorial that demonstrates how IoT streams can be processed and inserted into CrateDB for further analyses.

An Open Source Stack for Industrial IoT Time Series Streaming
Industrial IoT presents extreme time series challenges for developers. Data from connected factories, energy grids, and service vehicle fleets is often orders of magnitude more varied and voluminous than time series workloads in the IT systems monitoring and consumer IoT fields.
In this the following section, we explain how to meet the IoT data requirements above, and in particular, industrial time series processing, with an open source stack containing Apache Kafka, Apache Flink, and CrateDB.
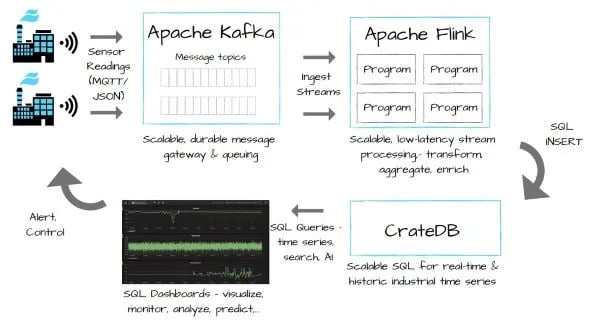
Apache Kafka - IoT Sensor Message Gateway
The stack uses Apache Kafka on the front line, to queue messages received from IoT sensors and devices and make that data highly available to systems that need it (e.g., Apache Flink).
Apache Kafka is a distributed, high-throughput message queuing system based on a distributed commit log. The core abstraction is a topic that is partitioned into multiple partitions. Producers, such as sensors in an IoT device, publish their records to partitions of a topic. The Kafka cluster durably persists incoming messages using the configurable retention policy that determines how long messages are available for consumption. Each partition maintains the immutable, ordered sequence of messages. Partitions are assigned to and replicated over multiple brokers.
Apache Kafka is a publish/subscribe-based messaging system. One or more downstream consumers subscribe to topics to read messages from its partitioned log. Consumers are assigned to consumer groups. Each record from a topic is processed by a single consumer from a group. Consumers groups load balance message processing over its consumers and allow parallel processing of messages.
Apache Flink - IoT Sensor Data Stream Processing
The stack uses Apache Flink to process and inject the sensor data stream that has been queued by Apache Kafka, into the CrateDB database.
Apache Flink is a stream processing framework that executes data pipelines--stateful computations over the data streams. Apache Flink has the unique ability to perform the following:
-
Fault-tolerant, high-throughput execution - Flink processes data streams in memory, and in parallel, across a cluster of servers. It has been benchmarked executing over one million events per second per CPU core.
-
Exactly-once” semantic - Flink guarantees that processed messages affect the final results exactly once, even under system failures.
-
Correct event order - Flink has the concept of “event time,” which ensures data is processed with respect to its timestamp, even if the events do not arrive in order. Flink offers multiple options when this happens, for handling data that is received “late.”
-
Back pressure relief - Flink throttles data sources to prevent them from overloading or crashing jobs.
-
Powerful computational model with windowing - Flink enables powerful computations, even computations bound by arbitrary time windows, to be performed over the data stream reliably and fast.
CrateDB - Query Real-time or Historic Industrial IoT Time Series Data
The stack uses the CrateDB SQL DBMS to store and query data that has been processed and enriched by Apache Flink.
CrateDB is a new kind of distributed SQL database that makes the stack extremely adept at handling industrial time series data due to its ease of use (SQL), and ability to work with many terabytes of time series data with thousands of sensor data structures.
CrateDB operates in a shared-nothing architecture as a cluster of identically configured servers (nodes). The nodes coordinate seamlessly with each other, and the execution of write and query operations are automatically distributed across the nodes in the cluster.
Increasing or decreasing database capacity is a simple task of adding or removing nodes. Sharding, replication (for fault tolerance), and rebalancing of data as the cluster changes size are automated.
Until recently, workloads like these often required a NoSQL solution like Cassandra, Elasticsearch, or InfluxDB, often in combination with a traditional RDBMS. CrateDB makes it possible to handle them in a single system, without sacrificing the familiarity and power of SQL. CrateDB connects seamlessly with tools like Grafana for data visualisation and monitoring which is a perfect fit for time series and machine data use cases.
If you have questions, feel free to contacts us for more information about the tutorial and whitepaper below.


You may also like

The Data Platform Bar Has Risen. Ververica Has Set It: Introducing Ververica Platform 3.1

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders
