Welcome to the second part in a series of blog posts on the Ververica Platform. The first post covered the installation of the platform and the deployment of a simple job. If you missed the first part and want to go over the installation process, Part 1 of Analyzing GitHub Activity with Ververica Platform Community Edition provides everything for you. You can access it here.

This post will show how Ververica Platform simplifies the maintenance of both ordinary, and not so ordinary, operations when managing Flink in production.
The third and last part of the series will dive deeper into some Advanced Configurations with Ververica Platform Community Edition, namely how you can set Deployment Defaults and Manage Secrets for your Flink application. You can can directly access Part 3 of Analyzing GitHub Activity with Ververica Platform Community Edition by following this link.

Stateful Upgrades
Apache Flink is inherently stateful, and that state is the most valuable part of any application. State snapshots carry over across deployments, upgrades, configuration changes, and bug fixes. It is the most long-lived component of any Apache Flink application.
Kubernetes, on the other hand, is tailored towards stateless services. Ververica Platform bridges this gap by managing Apache Flink state snapshots across application upgrades & migrations, allowing you to manage and configure your Apache Flink deployments in a stateless, declarative manner.
Let's go back to our analytics application from the first blog post. It has been successfully running in production for some time, but now we need to make a change. In this case, it appears activity has increased in the Apache Flink repository, so we would like to scale up our Deployment.
Click on the Configure Deployment button and change the parallelism from 1 to 2 before clicking Save Changes.
In the upper right-hand corner of the page, you will see the state of the deployment move from Running to Transitioning as the change takes effect.
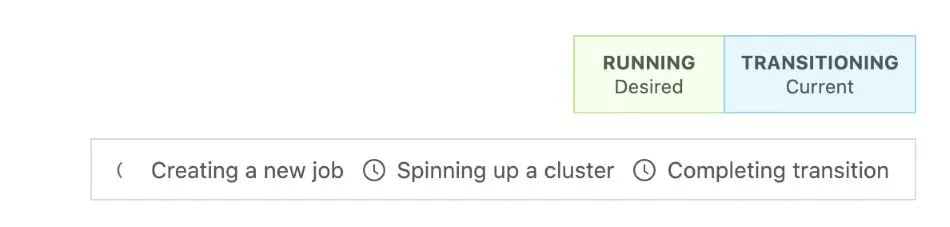
Additionally, you can select the Events tab of the deployment to see what the platform is doing under the hood.
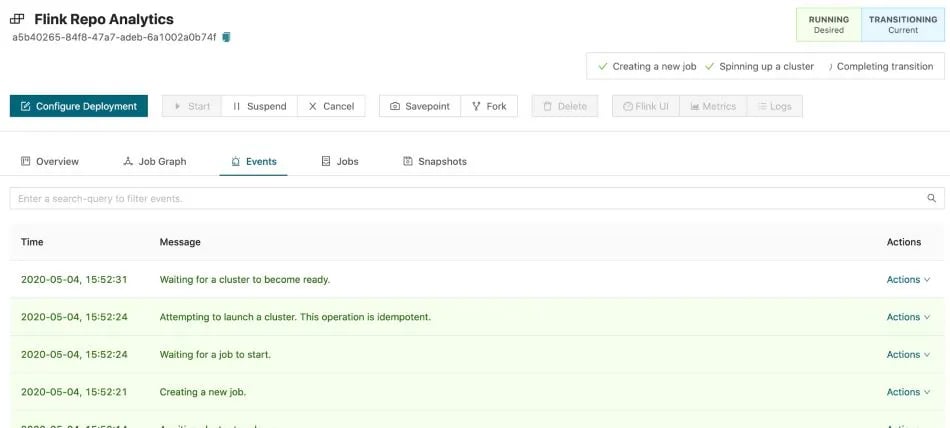
A snapshot of the application state is taken, and the cluster is reconfigured based on the updated deployment specification. This snapshot, along with all others in this deployment, is available under the snapshots tab. If we later discover that this reconfiguration was causing issues in production, we can reset the deployment to a previous snapshot. In this way, you can roll back both configuration and state such that your deployments will simulate failure-free execution.
Exploring our Update
In the previous post, we discussed how Ververica Platform raises the abstraction level from Flink Job to Deployment. Now that we have changed the parallelism, which resulted in a new Flink Job being created under the hood, let's further explore this concept of a Deployment.
The first thing you should notice is that there is not much to notice. The Job was upgraded as an implementation detail in the background, but the current Deployment is still the same. Important characteristics such as Deployment name and ID are stable and unchanged. Any pre-existing configuration that was not explicitly updated has not been touched. And, as noted above, the new Job was started using the internal state of the previous one, so no data was lost or corrupted.Returning to the Metrics page, you will see that metrics are scoped under Deployment rather than Job. Information about the previous and current Jobs are displayed on the same charts. You have one continuous view of the Deployment over time.
Intelligent Failover
Apache Flink is a distributed system with several moving parts. Because streaming systems must be highly available, clusters need a way of recovering from failure automatically.
Let’s deploy another change to the deployment. The repository analytics jar contains a secret feature that is disabled by default and hidden behind a feature flag. To enable, press Configure Deployment and add --enable-new-feature true to the main arguments. Finally, press Save Changes to deploy the change.
As previously, Ververica Platform will statefully update the running Deployment based on the new specification. Once running, you can check the Snapshots tab and see that checkpoints are being successfully taken for the upgraded Deployment. Unfortunately, it turns out that this new feature has a critical bug and is failing in production. After a few moments Ververica Platform will warn you that the Deployment is failing.
 Consider the situation where a parser is missing a particular edge case. The problem may lie dormant in production for some time until a record triggers this specific bug. If this issue results in an exception being thrown into the Apache Flink runtime, it will cause the deployment to go into a failure loop. Because Apache Flink provides exactly-once record processing guarantees, if a job fails on a specific record, it will throw an exception causing a restart, which in turn will reprocess the record starting the cycle over again.
Consider the situation where a parser is missing a particular edge case. The problem may lie dormant in production for some time until a record triggers this specific bug. If this issue results in an exception being thrown into the Apache Flink runtime, it will cause the deployment to go into a failure loop. Because Apache Flink provides exactly-once record processing guarantees, if a job fails on a specific record, it will throw an exception causing a restart, which in turn will reprocess the record starting the cycle over again.
It is not typically possible to take a Savepoint of an Apache Flink job while it is in a restart loop. Merely canceling the job and restarting from the latest Savepoint is not acceptable if that Savepoint is from several days or weeks ago. The time to reprocess all the records since that point may be prohibitive. Even worse, if working with message queues such as Kafka, the source topics may have compacted, resulting in data loss! Additionally, in our case we know the Job took at least one checkpoint, meaning data has been written out to the sink and restarting from the last savepoint would result in data duplication.
Kubernetes High Availability
Ververica Platform offers a Kubernetes-native high availability (HA) system that leverages the underlying Kubernetes cluster for distributed coordination. This is in contrast to Apache Flink, which requires users to run Apache Zookeeper clusters in production environments. Ververica Platform requires no additional components beyond a Kubernetes cluster and an object store.
Latest State
In the worst case, when a Flink Job becomes unresponsive and cannot be gracefully stopped, Ververica Platform ships with a feature called Latest State. When jobs are deployed using Kubernetes HA, the platform can track retained checkpoints across deployments. If a deployment misbehaves, it can be canceled and restarted without the need to take a Savepoint and without data loss.
Look in the Snapshot tab of the running deployment, which contains the list of state snapshots for the deployment. At the top of the table is a snapshot labeled CHECKPOINT; this is the most recent checkpoint.
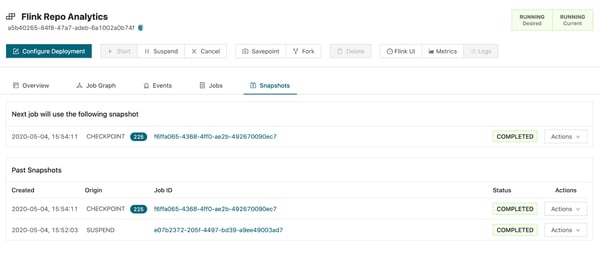 Let's assume that this deployment is misbehaving and cannot be gracefully shut down. Stop the deployment by pressing Cancel, rollback the deployment by removing the feature flag, and then restart it using Start. You will see that the latest snapshot is used as the initial state for the newly started job.
Let's assume that this deployment is misbehaving and cannot be gracefully shut down. Stop the deployment by pressing Cancel, rollback the deployment by removing the feature flag, and then restart it using Start. You will see that the latest snapshot is used as the initial state for the newly started job.
Conclusion
In this post, you learned how Ververica Platform simplifies the maintenance of stateful streaming applications in production. In the next installation, we will explore managing configurations for many deployments and some of the advanced features of the platform. Full documentation covering installation and usage is available on our website. If you have any questions do not hesitate to contact the team at community-edition@ververica.com.









