













Flink SQL has emerged as the de facto standard for low-code data analytics. It has managed to unify batch and stream processing while simultaneously staying true to the SQL standard. In addition, it provides a rich set of advanced features for real-time use cases. In a nutshell, Flink SQL provides the best of both worlds: it gives you the ability to process streaming data using SQL, but it also supports batch processing.
Ververica Platform makes Flink SQL even more accessible and efficiently scalable across teams. The platform comes with additional tools for developing SQL scripts, managing user-defined functions (UDFs), catalogs and connectors, as well as operating the resulting long-running queries.
We have seen that there are many use cases for Flink SQL, and we are excited to see what you will build with it. In this three-part series of blog posts, we will show you different types of joins in Flink SQL and how you can use them to process data in a variety of ways.
Make sure to check out our previous articles on Flink SQL:
Flink SQL: Window Top-N and Continuous Top-N
Flink SQL: Joins Series 1 (Regular, Interval, Look-up Joins)
In this article, you will learn:
- what is a non-compacted and compacted Kafka topic
- what is a temporal table
- how to perform a temporal table join between a non-compacted and compacted Kafka topic
- what is real time star schema denormalization
- how to perform real time star schema denormalization
Temporal table joins and non-compacted and compacted Kafka Topics
Apache Kafka's most fundamental unit of organization is the topic, which is something like a table in a relational database. A Kafka Topic can be compacted or non-compacted. A compacted topic retains all messages, even if they are deleted, for a certain time period. A non-compacted topic only retains messages that have not been deleted. In order to join a compacted and non-compacted topic, you can use a temporal table join.
A temporal table is a table that evolves over time. This is also known as a dynamic table in Flink. Rows in a temporal/dynamic table are associated with one or more temporal periods. The temporal table contains one or more versioned table snapshots.
A temporal table join is a feature that allows for data from two different temporal tables to be joined together on a common key, with the data from the second table being automatically inserted into the first table at the appropriate temporal period, or relevant version in the versioned table. This can be useful when integrating data from multiple sources, or when dealing with data that changes over time. This also means a table can be enriched with changing metadata and retrieve its value at a certain point in time.
How to perform a temporal table join between a non-compacted and compacted Kafka Topic
This example will show how to correctly enrich records from one Kafka topic with the corresponding records of another Kafka topic when the order of events matters.
Temporal table joins take an arbitrary table (left input/probe site) and correlate each row to the corresponding row’s relevant version in a versioned table (right input/build side). Flink uses the SQL syntax of FOR SYSTEM_TIME AS OF to perform this operation.
In this recipe, you will join each transaction (transactions) to its correct currency rate (currency_rates, a versioned table) as of the time when the transaction happened. A similar example would be to join each order with the customer details as of the time when the order happened. This is exactly what an event-time temporal table join does. A temporal table join in Flink SQL provides correct, deterministic results in the presence of out-of-orderness and arbitrary time skew between the two tables.
Both the transactions and currency_rates tables are backed by Kafka topics, but in the case of rates this topic is compacted (e.g. only the most recent messages for a given key are kept as updated rates flow in). Records in transactions are interpreted as inserts only, and so the table is backed by the standard Kafka connector (connector = kafka); while the records in currency_rates need to be interpreted as upserts based on a primary key, which requires the Upsert Kafka connector (connector = upsert-kafka).
Flink SQL
CREATE TEMPORARY TABLE currency_rates (
`currency_code` STRING,
`eur_rate` DECIMAL(6,4),
`rate_time` TIMESTAMP(3),
WATERMARK FOR `rate_time` AS rate_time - INTERVAL '15' SECOND,
PRIMARY KEY (currency_code) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'currency_rates',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'raw',
'value.format' = 'json'
);
CREATE TEMPORARY TABLE transactions (
`id` STRING,
`currency_code` STRING,
`total` DECIMAL(10,2),
`transaction_time` TIMESTAMP(3),
WATERMARK FOR `transaction_time` AS transaction_time - INTERVAL '30' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'transactions',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'raw',
'key.fields' = 'id',
'value.format' = 'json',
'value.fields-include' = 'ALL'
);
SELECT
t.id,
t.total * c.eur_rate AS total_eur,
t.total,
c.currency_code,
t.transaction_time
FROM transactions t
JOIN currency_rates FOR SYSTEM_TIME AS OF t.transaction_time AS c
ON t.currency_code = c.currency_code;SQL Client

Data Generators
The two topics are populated using a Flink SQL job, too. We use the faker connector to generate rows in memory based on Java Faker expressions and write those to the respective Kafka topics.
currency_rates Topic
Flink SQL
CREATE TEMPORARY TABLE currency_rates_faker
WITH (
'connector' = 'faker',
'fields.currency_code.expression' = '#{Currency.code}',
'fields.eur_rate.expression' = '#{Number.randomDouble ''4'',''0'',''10''}',
'fields.rate_time.expression' = '#{date.past ''15'',''SECONDS''}',
'rows-per-second' = '100'
) LIKE currency_rates (EXCLUDING OPTIONS);
INSERT INTO currency_rates SELECT * FROM currency_rates_faker;Kafka Topic
➜ bin ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic currency_rates --property print.key=true --property key.separator=" - "
HTG - {"currency_code":"HTG","eur_rate":0.0136,"rate_time":"2020-12-16 22:22:02"}
BZD - {"currency_code":"BZD","eur_rate":1.6545,"rate_time":"2020-12-16 22:22:03"}
BZD - {"currency_code":"BZD","eur_rate":3.616,"rate_time":"2020-12-16 22:22:10"}
BHD - {"currency_code":"BHD","eur_rate":4.5308,"rate_time":"2020-12-16 22:22:05"}
KHR - {"currency_code":"KHR","eur_rate":1.335,"rate_time":"2020-12-16 22:22:06"}transactions Topic
Flink SQL
CREATE TEMPORARY TABLE transactions_faker
WITH (
'connector' = 'faker',
'fields.id.expression' = '#{Internet.UUID}',
'fields.currency_code.expression' = '#{Currency.code}',
'fields.total.expression' = '#{Number.randomDouble ''2'',''10'',''1000''}',
'fields.transaction_time.expression' = '#{date.past ''30'',''SECONDS''}',
'rows-per-second' = '100'
) LIKE transactions (EXCLUDING OPTIONS);
INSERT INTO transactions SELECT * FROM transactions_faker;Kafka Topic
➜ bin ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic transactions --property print.key=true --property key.separator=" - "
e102e91f-47b9-434e-86e1-34fb1196d91d - {"id":"e102e91f-47b9-434e-86e1-34fb1196d91d","currency_code":"SGD","total":494.07,"transaction_time":"2020-12-16 22:18:46"}
bf028363-5ee4-4a5a-9068-b08392d59f0b - {"id":"bf028363-5ee4-4a5a-9068-b08392d59f0b","currency_code":"EEK","total":906.8,"transaction_time":"2020-12-16 22:18:46"}
e22374b5-82da-4c6d-b4c6-f27a818a58ab - {"id":"e22374b5-82da-4c6d-b4c6-f27a818a58ab","currency_code":"GYD","total":80.66,"transaction_time":"2020-12-16 22:19:02"}
81b2ce89-26c2-4df3-b12a-8ca921902ac4 - {"id":"81b2ce89-26c2-4df3-b12a-8ca921902ac4","currency_code":"EGP","total":521.98,"transaction_time":"2020-12-16 22:18:57"}
53c4fd3f-af6e-41d3-a677-536f4c86e010 - {"id":"53c4fd3f-af6e-41d3-a677-536f4c86e010","currency_code":"UYU","total":936.26,"transaction_time":"2020-12-16 22:18:59"}Real Time Star Schema Denormalization (N-Way Join)
A real-time star schema denormalization is a process of joining two or more tables in a star schema so that the data in the resulting table is denormalized. This can be done for performance reasons, to make it easier to query the data, or both. Denormalization can be used to improve the performance of queries that join large numbers of tables, by reducing the number of joins that need to be performed. It can also make it easier to query the data, by providing a single table that contains all the data that would otherwise be spread across multiple tables.
The process of denormalization can be applied to any schema, but it is most commonly used with star schemas, which are schemas that have a central fact table surrounded by a number of dimension tables. The fact table contains the data that is being analyzed, and the dimension tables contain data that can be used to describe the data in the fact table. When denormalizing a star schema, the data in the dimension tables is combined into the fact table.
How to perform real-time star schema denormalization
This example will show how you can denormalize a simple star schema with an n-way temporal table join.
Star schemas are a popular way of normalizing data within a data warehouse. At the center of a star schema is a fact table whose rows contain metrics, measurements, and other facts about the world. Surrounding fact tables are one or more dimension tables which have metadata useful for enriching facts when computing queries.
Imagine, you are running a small data warehouse for a railroad company which consists of a fact table (train_activity) and three dimension tables (stations, booking_channels, and passengers). All inserts to the fact table, and all updates to the dimension tables, are mirrored to Apache Kafka. Records in the fact table are interpreted as inserts only, and so the table is backed by the standard Kafka connector (connector = kafka);. In contrast, the records in the dimensional tables are upserts based on a primary key, which requires the Upsert Kafka connector (connector = upsert-kafka).
With Flink SQL you can now easily join all dimensions to our fact table using a 5-way temporal table join. Temporal table joins take an arbitrary table (left input/probe site) and correlate each row to the corresponding row’s relevant version in a versioned table (right input/build side). Flink uses the SQL syntax of FOR SYSTEM_TIME AS OF to perform this operation. Using a temporal table join leads to consistent, reproducible results when joining a fact table with more (slowly) changing dimensional tables. Every event (row in the fact table) is joined to its corresponding value of each dimension based on when the event occurred in the real world.
CREATE TEMPORARY TABLE passengers (
passenger_key STRING,
first_name STRING,
last_name STRING,
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time - INTERVAL '10' SECONDS,
PRIMARY KEY (passenger_key) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'passengers',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'raw',
'value.format' = 'json'
);
CREATE TEMPORARY TABLE stations (
station_key STRING,
update_time TIMESTAMP(3),
city STRING,
WATERMARK FOR update_time AS update_time - INTERVAL '10' SECONDS,
PRIMARY KEY (station_key) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'stations',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'raw',
'value.format' = 'json'
);
CREATE TEMPORARY TABLE booking_channels (
booking_channel_key STRING,
update_time TIMESTAMP(3),
channel STRING,
WATERMARK FOR update_time AS update_time - INTERVAL '10' SECONDS,
PRIMARY KEY (booking_channel_key) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'booking_channels',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'raw',
'value.format' = 'json'
);
CREATE TEMPORARY TABLE train_activities (
scheduled_departure_time TIMESTAMP(3),
actual_departure_date TIMESTAMP(3),
passenger_key STRING,
origin_station_key STRING,
destination_station_key STRING,
booking_channel_key STRING,
WATERMARK FOR actual_departure_date AS actual_departure_date - INTERVAL '10' SECONDS
) WITH (
'connector' = 'kafka',
'topic' = 'train_activities',
'properties.bootstrap.servers' = 'localhost:9092',
'value.format' = 'json',
'value.fields-include' = 'ALL'
);
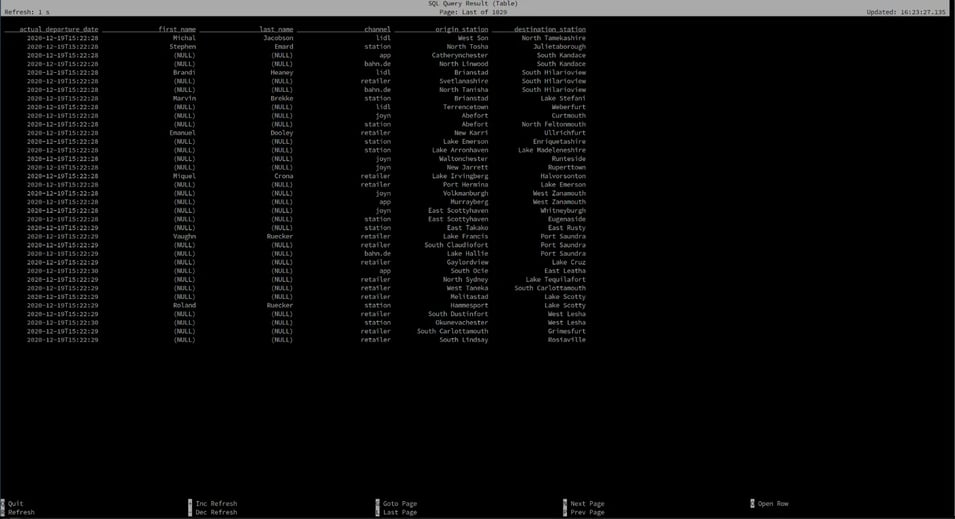
SELECT
t.actual_departure_date,
p.first_name,
p.last_name,
b.channel,
os.city AS origin_station,
ds.city AS destination_station
FROM train_activities t
LEFT JOIN booking_channels FOR SYSTEM_TIME AS OF t.actual_departure_date AS b
ON t.booking_channel_key = b.booking_channel_key;
LEFT JOIN passengers FOR SYSTEM_TIME AS OF t.actual_departure_date AS p
ON t.passenger_key = p.passenger_key
LEFT JOIN stations FOR SYSTEM_TIME AS OF t.actual_departure_date AS os
ON t.origin_station_key = os.station_key
LEFT JOIN stations FOR SYSTEM_TIME AS OF t.actual_departure_date AS ds
ON t.destination_station_key = ds.station_key;SQL Client
JobGraph
Data Generators
The four topics are populated with Flink SQL jobs, too. We use the faker connector to generate rows in memory based on Java Faker expressions and write those to the respective Kafka topics.
train_activities Topic
Flink SQL
CREATE TEMPORARY TABLE train_activities_faker
WITH (
'connector' = 'faker',
'fields.scheduled_departure_time.expression' = '#{date.past ''10'',''0'',''SECONDS''}',
'fields.actual_departure_date.expression' = '#{date.past ''10'',''5'',''SECONDS''}',
'fields.passenger_key.expression' = '#{number.numberBetween ''0'',''10000000''}',
'fields.origin_station_key.expression' = '#{number.numberBetween ''0'',''1000''}',
'fields.destination_station_key.expression' = '#{number.numberBetween ''0'',''1000''}',
'fields.booking_channel_key.expression' = '#{number.numberBetween ''0'',''7''}',
'rows-per-second' = '1000'
) LIKE train_activities (EXCLUDING OPTIONS);
INSERT INTO train_activities SELECT * FROM train_activities_faker;Kafka Topic
➜ bin ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic train_actitivies --property print.key=true --property key.separator=" - "
null - {"scheduled_departure_time":"2020-12-19 13:52:37","actual_departure_date":"2020-12-19 13:52:16","passenger_key":7014937,"origin_station_key":577,"destination_station_key":862,"booking_channel_key":2}
null - {"scheduled_departure_time":"2020-12-19 13:52:38","actual_departure_date":"2020-12-19 13:52:23","passenger_key":2244807,"origin_station_key":735,"destination_station_key":739,"booking_channel_key":2}
null - {"scheduled_departure_time":"2020-12-19 13:52:46","actual_departure_date":"2020-12-19 13:52:18","passenger_key":2605313,"origin_station_key":216,"destination_station_key":453,"booking_channel_key":3}
null - {"scheduled_departure_time":"2020-12-19 13:53:13","actual_departure_date":"2020-12-19 13:52:19","passenger_key":7111654,"origin_station_key":234,"destination_station_key":833,"booking_channel_key":5}
null - {"scheduled_departure_time":"2020-12-19 13:52:22","actual_departure_date":"2020-12-19 13:52:17","passenger_key":2847474,"origin_station_key":763,"destination_station_key":206,"booking_channel_key":3}passengers Topic
Flink SQL
CREATE TEMPORARY TABLE passengers_faker
WITH (
'connector' = 'faker',
'fields.passenger_key.expression' = '#{number.numberBetween ''0'',''10000000''}',
'fields.update_time.expression' = '#{date.past ''10'',''5'',''SECONDS''}',
'fields.first_name.expression' = '#{Name.firstName}',
'fields.last_name.expression' = '#{Name.lastName}',
'rows-per-second' = '1000'
) LIKE passengers (EXCLUDING OPTIONS);
INSERT INTO passengers SELECT * FROM passengers_faker;Kafka Topic
➜ bin ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic passengers --property print.key=true --property key.separator=" - "
749049 - {"passenger_key":"749049","first_name":"Booker","last_name":"Hackett","update_time":"2020-12-19 14:02:32"}
7065702 - {"passenger_key":"7065702","first_name":"Jeramy","last_name":"Breitenberg","update_time":"2020-12-19 14:02:38"}
3690329 - {"passenger_key":"3690329","first_name":"Quiana","last_name":"Macejkovic","update_time":"2020-12-19 14:02:27"}
1212728 - {"passenger_key":"1212728","first_name":"Lawerence","last_name":"Simonis","update_time":"2020-12-19 14:02:27"}
6993699 - {"passenger_key":"6993699","first_name":"Ardelle","last_name":"Frami","update_time":"2020-12-19 14:02:19"}stations Topic
Flink SQL
CREATE TEMPORARY TABLE stations_faker
WITH (
'connector' = 'faker',
'fields.station_key.expression' = '#{number.numberBetween ''0'',''1000''}',
'fields.city.expression' = '#{Address.city}',
'fields.update_time.expression' = '#{date.past ''10'',''5'',''SECONDS''}',
'rows-per-second' = '100'
) LIKE stations (EXCLUDING OPTIONS);
INSERT INTO stations SELECT * FROM stations_faker;
Kafka Topic
➜ bin ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic stations --property print.key=true --property key.separator=" - "
80 - {"station_key":"80","update_time":"2020-12-19 13:59:20","city":"Harlandport"}
33 - {"station_key":"33","update_time":"2020-12-19 13:59:12","city":"North Georgine"}
369 - {"station_key":"369","update_time":"2020-12-19 13:59:12","city":"Tillmanhaven"}
580 - {"station_key":"580","update_time":"2020-12-19 13:59:12","city":"West Marianabury"}
616 - {"station_key":"616","update_time":"2020-12-19 13:59:09","city":"West Sandytown"}
booking_channels Topic
Flink SQL
CREATE TEMPORARY TABLE booking_channels_faker
WITH (
'connector' = 'faker',
'fields.booking_channel_key.expression' = '#{number.numberBetween ''0'',''7''}',
'fields.channel.expression' = '#{regexify ''(bahn\.de|station|retailer|app|lidl|hotline|joyn){1}''}',
'fields.update_time.expression' = '#{date.past ''10'',''5'',''SECONDS''}',
'rows-per-second' = '100'
) LIKE booking_channels (EXCLUDING OPTIONS);
INSERT INTO booking_channels SELECT * FROM booking_channels_faker;
Kafka Topic
➜ bin ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic booking_channels --property print.key=true --property key.separator=" - "
1 - {"booking_channel_key":"1","update_time":"2020-12-19 13:57:05","channel":"joyn"}
0 - {"booking_channel_key":"0","update_time":"2020-12-19 13:57:17","channel":"station"}
4 - {"booking_channel_key":"4","update_time":"2020-12-19 13:57:15","channel":"joyn"}
2 - {"booking_channel_key":"2","update_time":"2020-12-19 13:57:02","channel":"app"}
1 - {"booking_channel_key":"1","update_time":"2020-12-19 13:57:06","channel":"retailer"}
Summary
In this article, you learned about temporal table joins between a non-compacted and compacted Kafka topic, and real-time star schema denormalization. You've also seen how to use Flink SQL to write queries for both of these types of scenarios.
We encourage you to run these examples on Ververica Platform. You can follow these simple steps to install the platform.
To learn more about Flink SQL, check out the following resources:
You may also like

A World Without Kafka

Introducing The Era of "Zero-State" Streaming Joins

Ververica Platform 3.0: The Turning Point for Unified Streaming Data
