Ververica Platform provides a turnkey solution for running Apache Flink in production. The Community Edition of Ververica Platform, is a free-to-use package that offers the core operational components users need when deploying Flink in production, without arbitrary restrictions on the number or size of your deployments. This is the first in a series of blog posts that will walk you through the installation and usage of the platform. Each blog post in this series is accompanied by one or multiple video step-by-step guides taking you through the necessary process in Ververica Platform. The videos are also available on the Ververica YouTube channel. In particular, this post will cover the installation process and deployment of your first application.
The second part of the series will cover how Veverica Platform Community Edition performs Upgrade Strategies and offers Kubernetes High Availability. You can go directly to Part 2 of Analyzing GitHub Activity with Ververica Platform Community Edition here.

The third and last part of the series will dive deeper into some Advanced Configurations with Ververica Platform Community Edition, namely how you can set Deployment Defaults and Manage Secrets for your Flink application. You can can directly access Part 3 of Analyzing GitHub Activity with Ververica Platform Community Edition by following this link.

To follow along with this and subsequent posts, you will need a Kubernetes Cluster with at least 8GB of memory and 4 CPUs. Please see our Getting Started Guide for instructions on how to run a small Kubernetes cluster locally on your machine.
Begin by cloning the Ververica Platform Playground repository and switching to the branch release-2.1-blogpost. It contains all required configuration files to set up your environment. There is also a convenience setup script that will install Ververica Platform, MinIO, Prometheus, Elasticsearch, and Grafana, along with configuring the necessary namespaces. The script creates two Kubernetes namespaces and then uses Helm to install the components; it is straightforward to inspect. When installing the platform, you will be asked to accept the Ververica Community License; please read it carefully and accept to complete the installation.
$ git clone --branch release-2.1-blogpost-series git@github.com:ververica/ververica-platform-playground.git
$ cd ververica-platform-playground
$ ./setup.sh --with-metrics --with-elastic-search
Flink Repository Analytics
Apache Flink is a large project containing many submodules and components. On any given day, the Flink community is busy working on any number of features, optimizations, and bug fixes. Throughout this series of posts, you will be working on operationalizing a Flink job that tracks commit activity by component. It pulls commit data from the repository using the Github API and writes the results of its aggregations to Elasticsearch. This data is then visualized in Grafana.
The code for this job is available on Github. You may either download the pre-built jar from Github packages or clone the repository and build the project using mvn package.
Deployments, not Jobs
If you have ever worked with Apache Flink in the past, then you might be familiar with the concept of a Job. A job is code at a particular point in time, with specific configurations and initial state. Making a change to any of these components, such as upgrading user code to deploy a new feature or changing certain configurations like its parallelism, requires deploying a new Job.
Organizations do not care about isolated jobs; they are focused on running long-lived services. These services may go through many changes over their lifetime, such as deploying new features and bug fixes, rescaling, and even rolling back. Regardless of how code or configuration changes, it is one continuous service.
Ververica Platform raises the abstraction level, allowing users to manage Deployments, which are long-lived services composed of many Flink jobs over time. In doing so, the platform provides a continuous view of Flink services as they evolve and change.
Our First Deployment
With the platform up and running, let’s go ahead and deploy our application. In order to access the web user interface or the REST API, set up a port forward to the Ververica Platform Kubernetes service:
$ kubectl --namespace vvp port-forward services/vvp-ververica-platform 8080:80
A port forward also needs to be configured to access the Grafana dashboard:
$ kubectl --namespace vvp port-forward services/grafana 3000:80
Deployments are the core resource to manage Apache Flink jobs within Ververica Platform. A Deployment specifies the desired state of an application and its configuration. At the same time, Ververica Platform tracks and reports each Deployment’s status and derives other resources from it. Whenever the Deployment specification is modified, the platform will ensure the running application will eventually reflect this change.
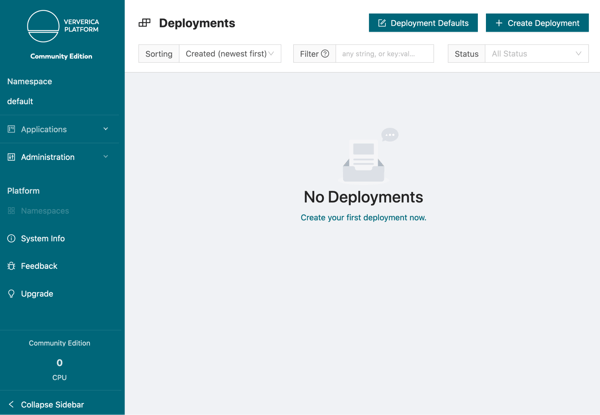 Before creating your first Deployment, you need to create a Deployment Target. A Deployment Target links a Deployment to a Kubernetes namespace, which Apache Flink applications may then be deployed into. In this case, you can use the vvp-jobs namespace that was created by the setup script.
Before creating your first Deployment, you need to create a Deployment Target. A Deployment Target links a Deployment to a Kubernetes namespace, which Apache Flink applications may then be deployed into. In this case, you can use the vvp-jobs namespace that was created by the setup script.
Choose Deployment Targets in the left side-bar under Administration and click Add Deployment Target. Give it the name vvp-jobs and point it to the vvp-jobs namespace.
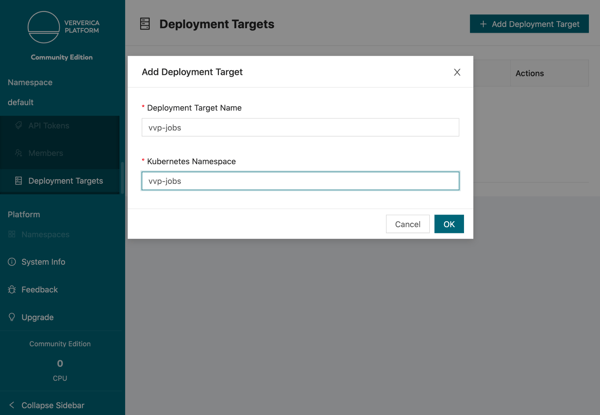 Next, upload the user code jar as an artifact to the platform. Switch to the artifacts page under the Applications tab on the side bar and then upload the flink-repo-analytics jar file.
Next, upload the user code jar as an artifact to the platform. Switch to the artifacts page under the Applications tab on the side bar and then upload the flink-repo-analytics jar file.
 Now, you can create your Deployment. Choose + Create Deployment in the left sidebar. For now, we recommend using the Standard view. This page shows the minimum set of configurations necessary to deploy a Flink application to production.
Now, you can create your Deployment. Choose + Create Deployment in the left sidebar. For now, we recommend using the Standard view. This page shows the minimum set of configurations necessary to deploy a Flink application to production.
-
Name: Provide a name such as “Flink Repo Analytics”
-
Deployment Target: Select the Deployment Target that you just created
-
Jar UI: Choose the uploaded Jar to run
-
Entrypoint main arguments: There are no flags required to deploy this jar, however, it is recommended to set the flag --start-date to 7 days in the past so that the job can quickly process historical data that you can visualize. If the flag --start-date is set to anything longer than one week, the Github API will likely rate-limit the client. Please see the README of the analytics job for a full list of command line arguments.
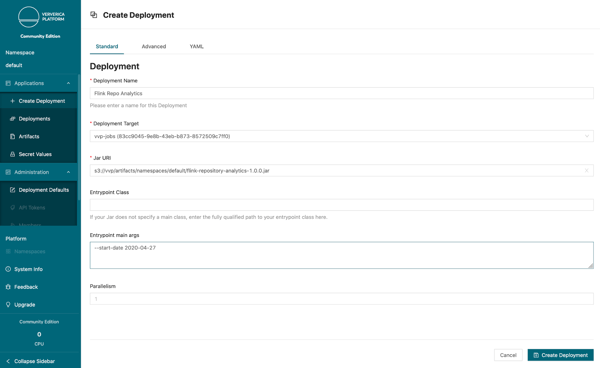 Finally, press Create Deployment to start the application. Ververica Platform will now go ahead and create a highly-available Flink cluster, which runs your application in the vvp-jobs namespace. Once the status bar in the upper right corner moves to RUNNING | RUNNING, the job has been successfully deployed.
Finally, press Create Deployment to start the application. Ververica Platform will now go ahead and create a highly-available Flink cluster, which runs your application in the vvp-jobs namespace. Once the status bar in the upper right corner moves to RUNNING | RUNNING, the job has been successfully deployed.
Checking Statistics
Once the application is deployed, you are taken to the overview page for that deployment. Before exploring this page further, let's check on the output of the running application. The repository analytics are sent as an output to Elasticsearch and visualized via Grafana. For simplicity, the Grafana instance is the same as the one being used to display metrics.
Press the Metrics button on the top of the page to be automatically redirected. From here, change the dashboard from the Simple Flink Dashboard page to Apache Flink Github Statistic dashboard.
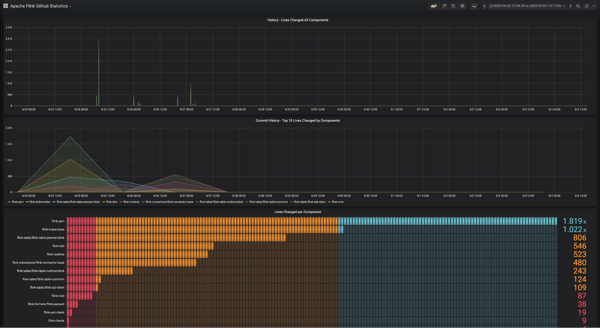
This page shows an overview of the statistics generated by the Flink job. Like any good streaming application, we will see the dashboard continuously updated as new data is processed. The dashboard will be populated slowly as the source is being powered by an unauthenticated Github client. In subsequent posts, we will cover how to securely add credentials to a deployment.
Exploring the Deployment
Let's go back to the overview page for the Deployment. Here you can see how the Flink cluster has been created. Key Flink configurations have been pre-defined for the Deployment. These include Checkpointing and Savepoints, as well as Flink master failover which enables robust production pipelines. These are key requirements for any production usage of Flink, so the platform ensures they are automatically set up correctly every time.
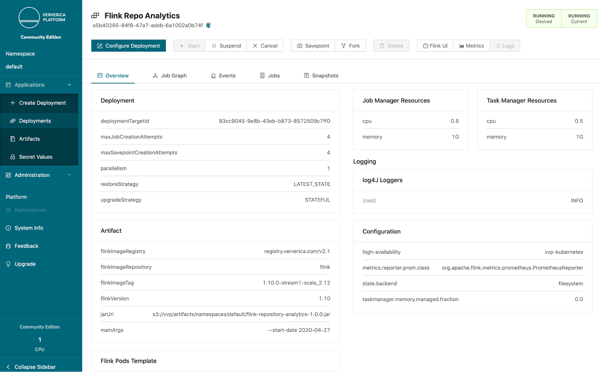
Beyond the main overview page there are a number of tabs to explore:
JobGraph: The Job Graph tab shows a visualization of the running Job.
Events: The Events tab lists the operations Ververica Platform is performing behind the scenes to manage your running Job.
Jobs: The Jobs tab lists all the underlying Flink Jobs that make up this deployment.
Snapshots: The Snapshots tab lists all the Savepoints and Retained Checkpoints for the Deployment.
Universal Blob Storage
You may be curious where your artifacts are being stored, and how checkpoints could be configured if a checkpoint directory was never specified. Ververica Platform ships with a feature called Universal Blob Storage, which allows administrators to configure a central distributed file system for both these scenarios along with savepoint and high availability storage. Of course, any individual deployment can always override these defaults if needed.
In the platform configuration file – values-vvp.yaml – you can see that MinIO is configured to be the universal blob storage provider for the platform.
vvp:
blobStorage:
baseUri: s3://vvp
s3:
endpoint: http://minio.vvp.svc:9000
blobStorageCredentials:
s3:
accessKeyId: admin
secretAccessKey: password
Along with S3, Ververica Platform also supports Azure Blob Storage for universal blob storage. Support for HDFS, Google Cloud Storage, and Aliyun Object Storage Service will be added soon. Please see the official documentation on Universal Blob Storage for more information.
Conclusion
This post walked you through the installation of Ververica Platform and the deployment of an Apache Flink application. In the next post, we will look at how the platform simplifies application management and application upgrades. Full documentation covering installation and usage is available on our website. If you have any questions do not hesitate to contact the team at community-edition@ververica.com.









